
MixEval: 开创大语言模型评估新纪元
在人工智能和自然语言处理飞速发展的今天,如何准确、高效地评估大语言模型(LLMs)的性能已成为一个关键问题。传统的评估方法往往难以兼顾真实世界的复杂性和评估的可重复性。而最新推出的MixEval基准正是为解决这一难题而生,它巧妙地结合了真实用户查询和现有基准的优势,为LLM评估领域带来了一股清新的变革之风。
MixEval: bridging the gap between reality and reproducibility
MixEval的核心理念是通过融合web挖掘的真实用户查询和现有基准中的相似查询,来构建一个既贴近现实又易于复现的评估体系。这种创新方法不仅保留了真实查询的复杂性和多样性,还继承了现有基准的可控性和可重复性。

MixEval主要由两个版本构成:
- MixEval: 标准版本,在全面性和效率之间取得平衡。
- MixEval-Hard: 难度更高的版本,旨在提升基准区分强模型的能力。
这两个版本都包含自由形式(free-form)和多项选择(multiple-choice)两种类型的任务,以全面评估模型的各方面能力。更重要的是,MixEval采用动态更新机制,每月通过稳定的pipeline更新数据点,有效降低了数据污染的风险。
为什么选择MixEval?
MixEval为LLM评估领域带来了多项显著优势:
- 高度准确的模型排名: 与Chatbot Arena的相关性高达0.96,确保评估结果的可靠性。
- 快速、经济且可重复: 仅需MMLU 6%的时间和成本,无需人工输入即可完成评估。
- 动态更新机制: 通过低成本、稳定的更新流程,确保基准的时效性。
- 全面且无偏的查询分布: 基于大规模web语料库,提供更接近真实世界的评估场景。
- 公平的评分过程: 采用基于ground-truth的评分机制,确保评估的客观性。
MixEval的技术实现
MixEval的实现过程充分考虑了易用性和灵活性。研究人员可以通过简单的步骤快速部署和使用MixEval:
- 克隆仓库并设置环境:
git clone https://github.com/Psycoy/MixEval.git
cd MixEval
conda create -n MixEval python=3.11 --yes
conda activate MixEval
bash setup.sh
- 设置OpenAI API密钥用于模型解析:
MODEL_PARSER_API=<your openai api key>
- 运行评估并获取结果:
python -m mix_eval.evaluate \
--model_name gemma_11_7b_instruct \
--benchmark mixeval_hard \
--version 2024-06-01 \
--batch_size 20 \
--max_gpu_memory 5GiB \
--output_dir mix_eval/data/model_responses/ \
--api_parallel_num 20
这种简洁的操作流程大大降低了评估的门槛,使研究人员可以专注于模型本身的改进而非评估过程的复杂性。
MixEval的实际应用
MixEval不仅仅是一个理论框架,它在实际应用中展现出了强大的潜力。以下是一些具体的应用场景:
-
模型开发迭代: 在模型训练过程中,研究人员可以使用MixEval快速评估模型性能,指导优化方向。
-
跨模型比较: MixEval提供了一个统一的评估标准,使得不同来源、不同架构的模型可以在同一平台上进行公平比较。
-
真实世界性能预测: 由于MixEval融合了真实用户查询,其评估结果对模型在实际应用中的表现有较强的预测能力。
-
动态性能追踪: 通过MixEval的定期更新机制,研究人员可以长期追踪模型性能的变化趋势,及时发现和解决潜在问题。
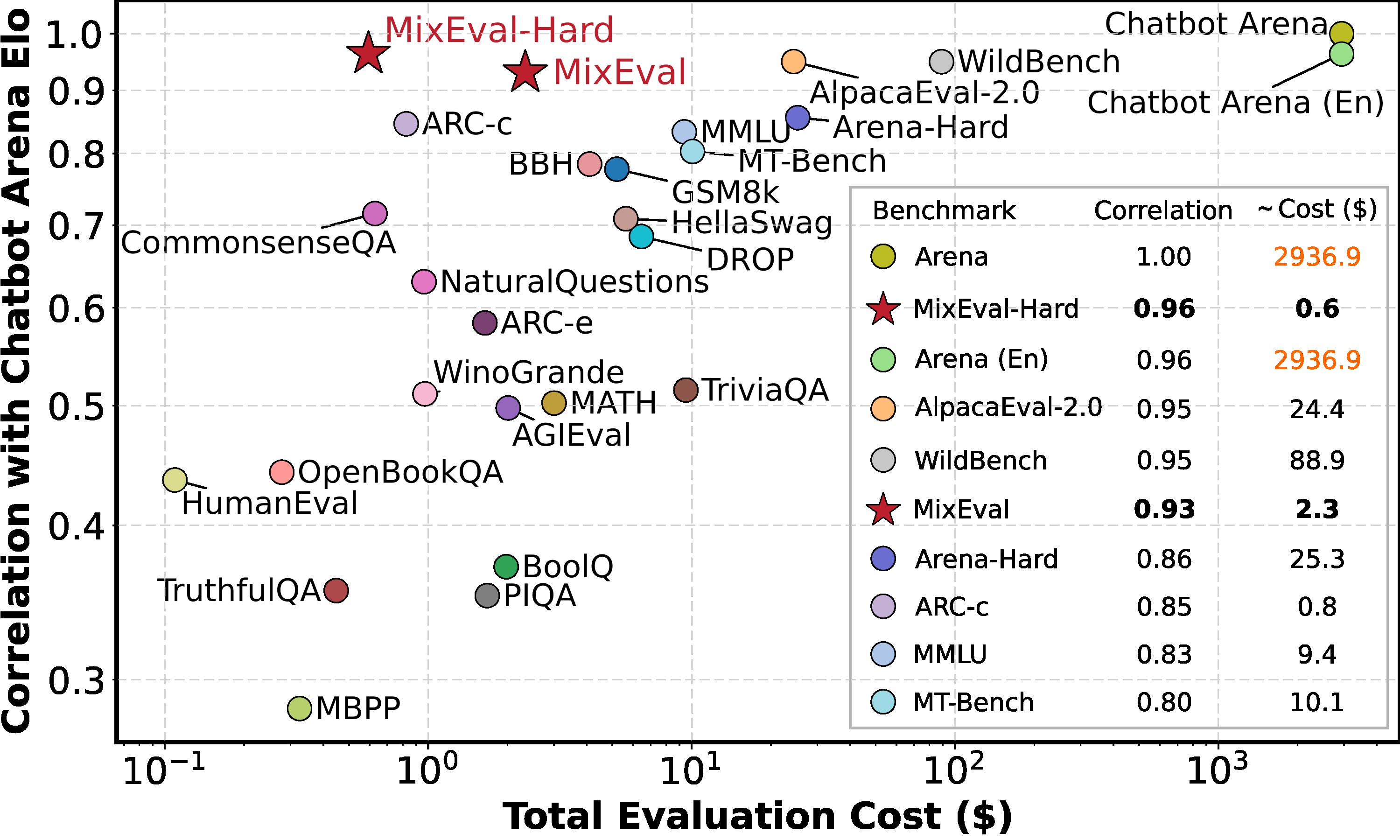
上图展示了MixEval与其他评估方法的成本效益比较。可以看出,MixEval在保持高相关性的同时,大幅降低了评估成本,使得频繁、全面的模型评估成为可能。
MixEval的未来展望
尽管MixEval已经展现出了巨大的潜力,但其发展之路仍在继续。未来,MixEval团队计划在以下几个方向进行改进和扩展:
-
多语言支持: 扩展MixEval以涵盖更多语言,使之成为真正的全球化评估基准。
-
任务多样性: 引入更多类型的任务,如多模态任务、长文本理解等,全面评估模型的各方面能力。
-
社区协作: 鼓励更多研究者和开发者参与MixEval的开发和维护,形成一个活跃的开源社区。
-
实时更新机制: 探索更快速的数据更新方法,使MixEval能够更紧密地跟随AI领域的快速发展。
-
与其他评估框架的集成: 探索与其他流行的评估框架如LMSYS Chatbot Arena的集成,为研究者提供更全面的评估工具集。
结语
MixEval的出现无疑为大语言模型评估领域注入了新的活力。它不仅解决了传统评估方法的诸多痛点,还为未来的模型评估指明了方向。随着AI技术的不断进步,像MixEval这样兼具科学性和实用性的评估工具将发挥越来越重要的作用,推动整个行业向着更高水平迈进。
对于研究者和开发者而言,MixEval提供了一个宝贵的资源,帮助他们更好地理解和改进自己的模型。而对于整个AI社区来说,MixEval的开源性质和持续更新机制,为建立一个更加开放、透明的评估生态系统做出了重要贡献。
让我们期待MixEval在未来能够继续发展壮大,为人工智能的进步贡献更多力量。同时,也呼吁更多的研究者和开发者加入到MixEval的使用和改进中来,共同推动大语言模型评估领域的革新与进步。
📑 如果你觉得MixEval对你的研究或工作有所帮助,请考虑引用以下文献:
@article{ni2024mixeval,
title={MixEval: Deriving Wisdom of the Crowd from LLM Benchmark Mixtures},
author={Ni, Jinjie and Xue, Fuzhao and Yue, Xiang and Deng, Yuntian and Shah, Mahir and Jain, Kabir and Neubig, Graham and You, Yang},
journal={arXiv preprint arXiv:2406.06565},
year={2024}
}
让我们共同见证和推动大语言模型评估领域的革新,为人工智能的未来贡献我们的力量!🚀🌟









