
项目简介
Mistral AI 团队正式发布了一篇关于Mixtral 8x7B -- 混合专家模型(Mixtral of Experts)的博客,提供了很多测试数据,最让人印象深刻的是,8个7B的混合专家模型,在大部分的性能测试中,Mixtral 不仅达到了 Llama 2 70B 的水平,甚至在很多方面超越了 GPT-3.5。
什么是Mixtral-8x7B
Mixtral-8x7B是Hugging Face上提供的一个模型,因其高质量的性能而著称,并且采用Apache 2.0许可证。
该模型拥有多种能力,包括处理32k令牌的上下文能力以及支持多种语言,包括英语、法语、意大利语、德语和西班牙语。
Mixtral是一个仅解码器的稀疏混合专家网络。其架构使得在控制成本和延迟的同时增加参数成为可能。
Mixtral-8x7B 性能指标
新模型旨在更好地理解和创造文本,这对于希望使用人工智能进行写作或沟通任务的人来说是一个关键特性。它在大多数基准测试中超过了Llama 2 70B,并且与GPT3.5相匹敌,展示了其在提升性能方面的高效性。
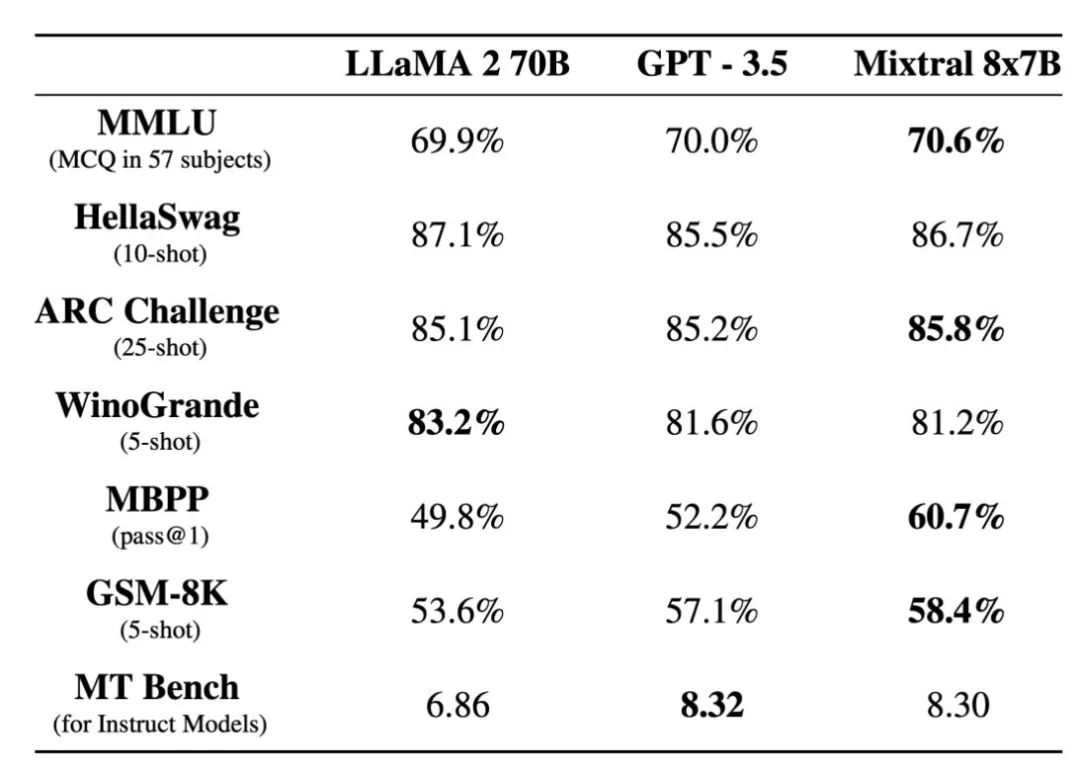
公司指出,在大多数基准测试中,它超过了Llama 2 70B,提供了六倍更快的推理速度。
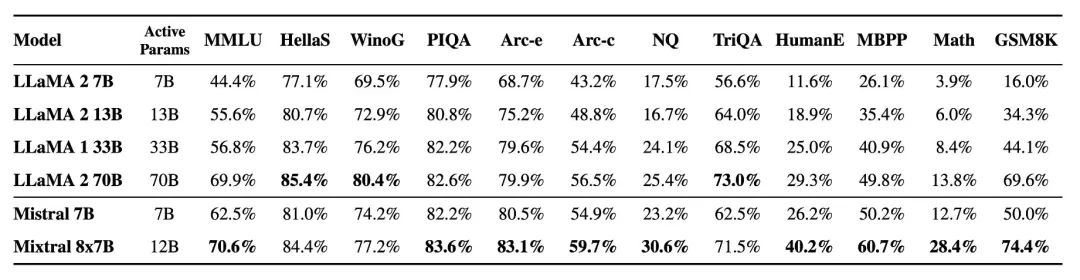
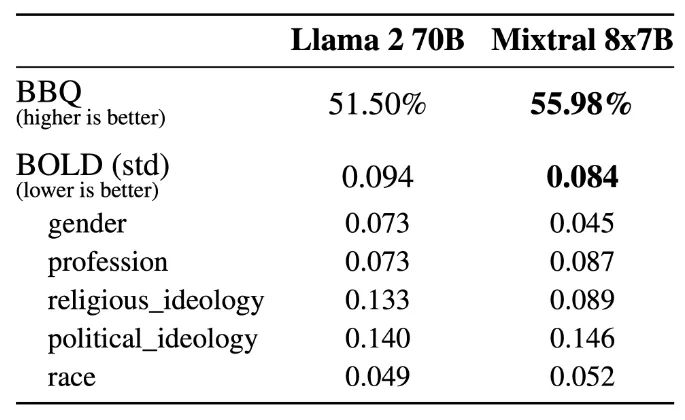
Mixtral在减少幻觉和偏见方面显示出了改进,这一点在其在TruthfulQA/BBQ/BOLD基准测试上的表现中很明显。与Llama 2相比,它展示了更真实的回应和更少的偏见,同时也表现出更积极的情绪。
Mixtral 8x7B在多语言方面的熟练程度通过其在多语言基准测试中的成功得到了证实。

除了Mixtral 8x7B之外,Mistral AI还发布了专为指令执行优化的Mixtral 8x7B Instruct。它在MT-Bench上的得分为8.30,使其成为顶级的开源模型。
Mixtral可以通过开源的vLLM项目集成到现有系统中,Skypilot支持云部署。Mistral AI还通过其平台提供对该模型的早期访问。
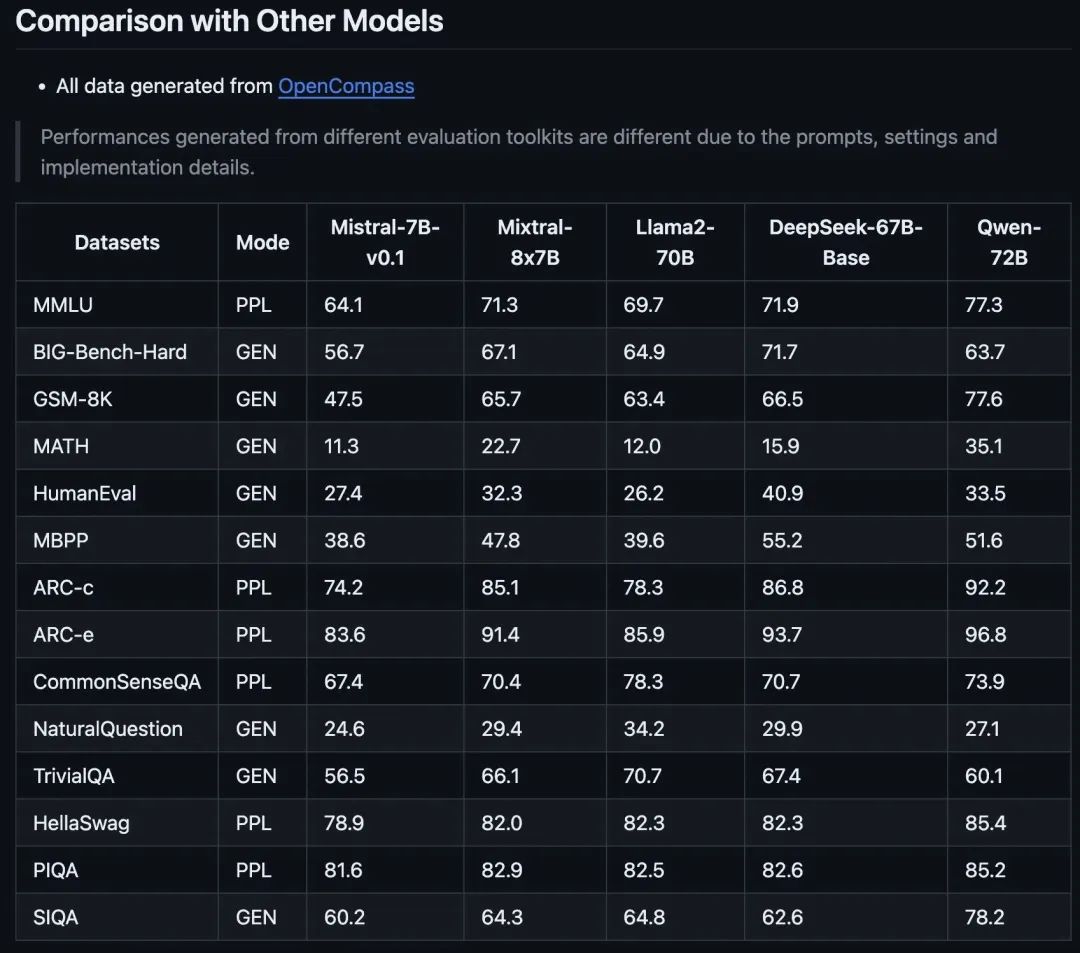
正如OpenCompass所分享的,Mistral家族的这一最新成员承诺以其提升的性能指标革新人工智能领域。
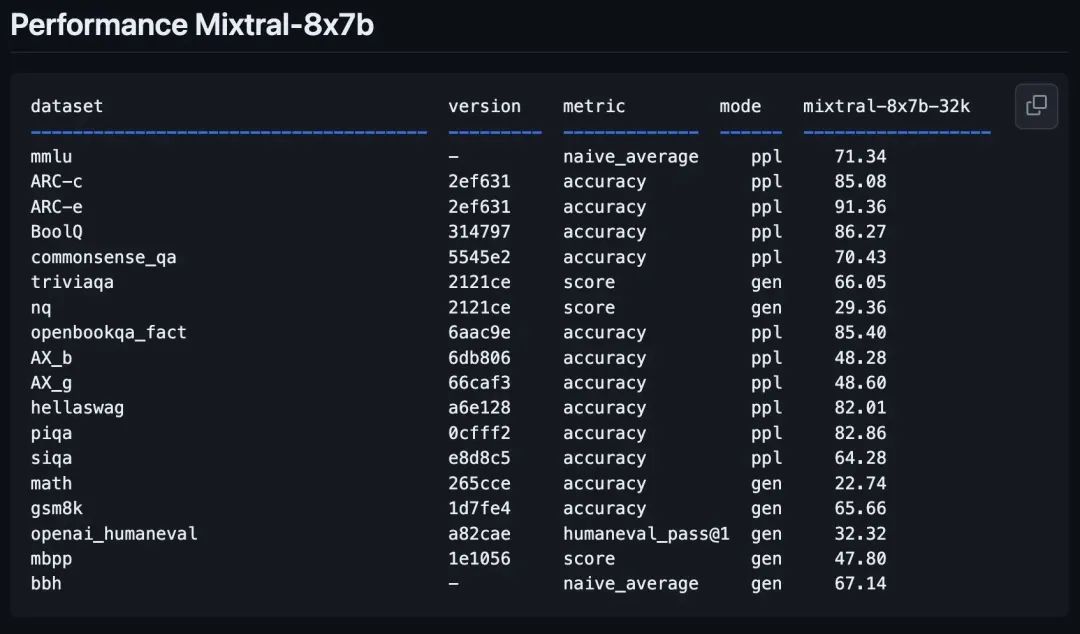
让Mixtral-8x7B脱颖而出的不仅仅是它相比Mistral AI之前版本的改进,还有它与Llama2-70B和Qwen-72B等模型的对比表现。
总结
Mistral AI的最新发布在人工智能领域设立了新的基准,提供了提升的性能和多功能性。但和许多大型语言模型一样,它有时也会提供不准确和意料之外的答案。














