
MMMU简介
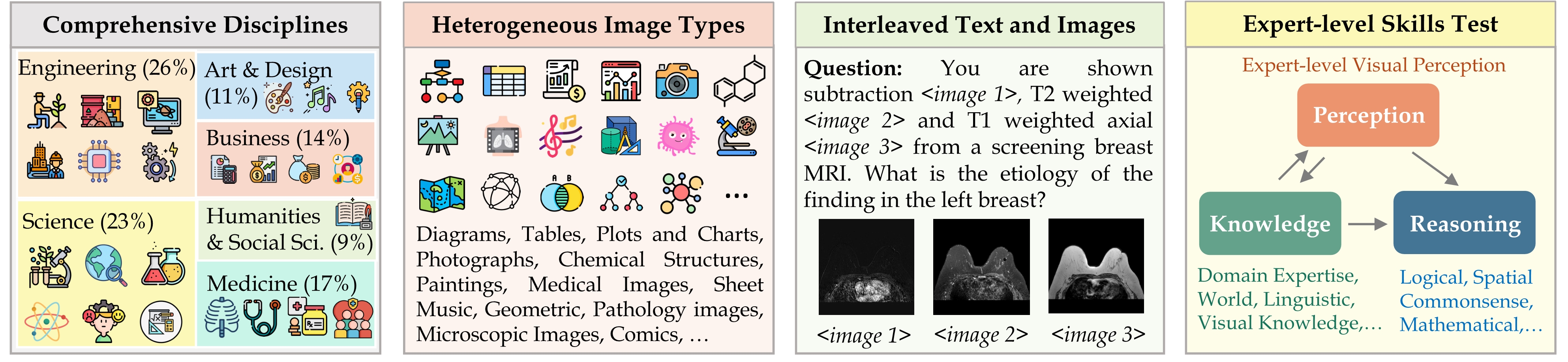
MMMU (Massive Multi-discipline Multimodal Understanding and Reasoning) 是一个大规模多学科多模态理解和推理基准测试,旨在评估多模态AI模型在专家级任务上的表现。它涵盖了艺术与设计、商业、科学、医疗健康、人文社科、技术工程等6大核心学科,包含30个学科和183个子领域的11.5K多模态问题。
MMMU的主要特点包括:
- 全面性:涵盖大学水平的多学科知识
- 多样性:包含30种异构图像类型
- 复杂性:需要专业领域知识和深度推理能力
- 挑战性:当前最先进模型GPT-4V的准确率仅为56%
相关资源
-
- 包含项目概述、排行榜、最新动态等信息
-
- 详细介绍了MMMU的设计理念和评估结果
-
- 在Hugging Face上可以下载和使用MMMU数据集
-
- 包含评估代码和使用说明
-
- 可以在此提交模型预测结果进行评估
使用指南
-
数据集结构:
- 开发集:150个样本,用于少样本/上下文学习
- 验证集:900个样本,用于调试模型和快速评估
- 测试集:10,500个问题(答案未公开)
-
评估流程:
- 在开发集上进行少样本学习
- 使用验证集调试和优化模型
- 在测试集上生成预测结果
- 将预测结果提交到EvalAI平台进行评估
-
注意事项:
- MMMU采用零样本设置,不允许在基准测试任务上进行微调
- 评估关注模型的感知、知识和推理三个核心能力

最新进展
- MMMU-Pro:MMMU的升级版,引入了更严格的评估方法
- 人类专家表现已添加到排行榜,为模型性能提供参考
- 持续更新排行榜,展示最新模型在MMMU上的表现
MMMU为多模态AI模型的评估提供了一个全面而富有挑战性的基准。研究人员和开发者可以利用MMMU来测试和改进模型的跨学科理解和推理能力,推动人工智能向着通用智能的方向发展。










