
ModelScan:为AI模型安全保驾护航
在人工智能技术日新月异的今天,机器学习模型已经广泛应用于各个领域,成为许多关键决策和任务的核心。然而,随着模型的广泛共享和使用,其安全性问题也日益凸显。ModelScan应运而生,成为保护AI模型免受序列化攻击的重要工具。
ModelScan简介
ModelScan是由Protect AI公司开发的一款开源模型扫描工具,旨在检测机器学习模型中潜在的不安全代码。它是首个支持多种模型格式的扫描工具,目前可以扫描H5、Pickle和SavedModel等格式,覆盖PyTorch、TensorFlow、Keras、Sklearn和XGBoost等主流框架。

为什么需要扫描模型?
随着机器学习模型在各个领域的广泛应用,模型的安全性变得越来越重要。然而,目前模型的安全检查还远远不够严格,远不如我们对待邮箱中的PDF文件那样谨慎。这种情况亟待改变,而ModelScan正是为此而生的重要工具。
模型序列化攻击是一种新型的安全威胁,攻击者可能在模型序列化(保存)过程中植入恶意代码。当用户加载这样的模型时,恶意代码就会被执行,可能导致凭证盗取、数据泄露、数据污染或模型篡改等严重后果。
例如,一个看似正常的PyTorch模型文件可能包含以下恶意代码:
# 恶意代码注入
command = "system"
malicious_code = """cat ~/.aws/secrets"""
当用户使用torch.load()加载这个模型时,恶意代码就会被执行,可能导致AWS凭证被盗取。
ModelScan的工作原理
ModelScan采用了一种安全的扫描方式,它不会直接加载模型文件,而是逐字节读取文件内容,寻找可能存在安全风险的代码签名。这种方法既快速又安全,可以在几秒钟内完成对大型模型文件的扫描。

ModelScan将检测到的不安全代码分为四个等级:
- CRITICAL(严重)
- HIGH(高危)
- MEDIUM(中等)
- LOW(低危)
如果检测到任何问题,用户应立即联系模型的作者,确定问题的原因。有时,数据科学家可能会在模型中嵌入一些代码以便于复现,但这也可能带来安全隐患。用户需要根据自己的工作负载,谨慎判断是否适合使用这样的模型。
使用ModelScan
ModelScan的使用非常简单,只需几个步骤即可开始扫描模型:
- 安装ModelScan:
pip install modelscan
- 扫描模型:
modelscan -p /path/to/model_file.pkl
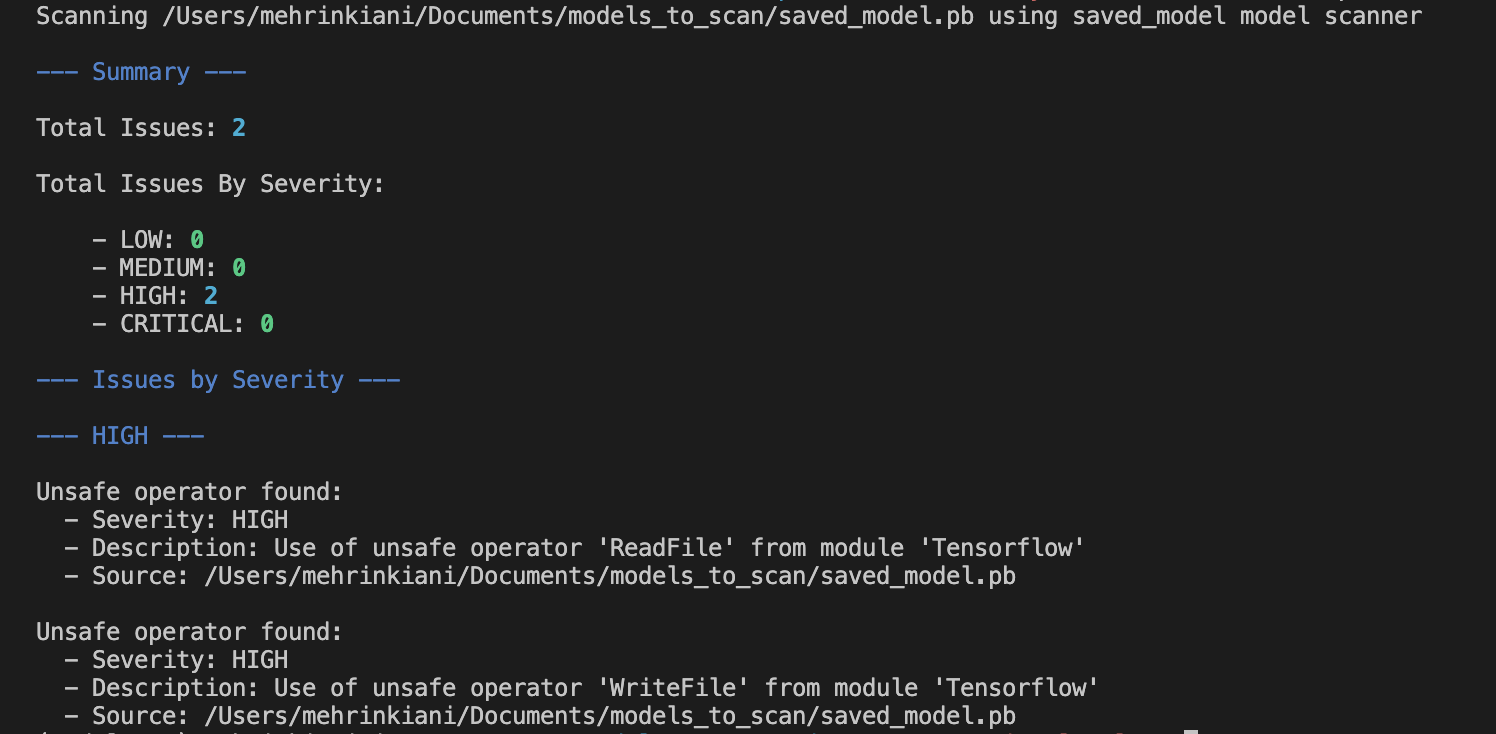
- 查看扫描结果:
扫描结果将包括:
- 已扫描的文件列表
- 未扫描的文件列表
- 按严重程度分类的扫描结果摘要
- 每个严重级别下发现的恶意代码的详细列表
在ML流水线和CI/CD流程中集成ModelScan
虽然临时扫描是一个很好的第一步,但要真正提高生产环境中MLOps流程的安全性,我们需要在多个阶段进行模型扫描:
- 在加载预训练模型进行进一步工作之前进行扫描,防止受损模型影响模型构建或数据科学环境。
- 在训练后对所有模型进行扫描,以检测可能影响新模型的供应链攻击。
- 在将模型部署到端点之前进行扫描,确保模型在存储后未被篡改。
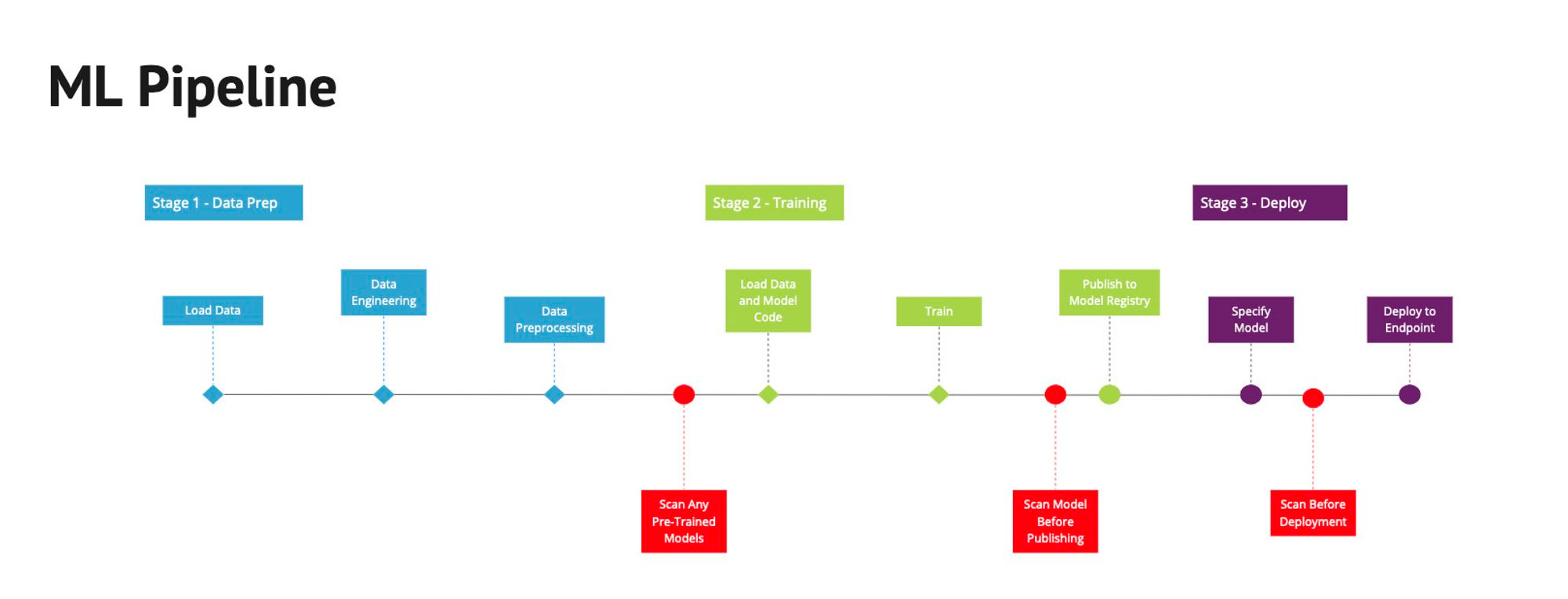
这些过程同样适用于LLM、基础模型或外部模型的微调或任何修改。如果模型部署在CI/CD系统之外,还应将扫描嵌入到部署过程中,以确保使用的安全性。
深入探索
ModelScan的GitHub仓库中提供了多个Jupyter notebooks,展示了如何针对TensorFlow和PyTorch等各种ML框架执行模型序列化攻击。用户可以通过这些示例深入了解攻击的原理和防御方法。
此外,项目文档中的Model Serialization Attack Explainer详细解释了这些攻击的工作原理,为用户提供了更深入的技术理解。
结语
在AI技术快速发展的今天,模型安全已经成为一个不容忽视的问题。ModelScan作为一款开源的模型扫描工具,为AI从业者提供了一个强大的武器,帮助他们保护模型免受序列化攻击的威胁。通过在ML流水线和CI/CD流程中集成ModelScan,我们可以大大提高AI系统的安全性,为AI的健康发展保驾护航。
ModelScan的开发团队欢迎社区的贡献,如果您有兴趣参与这个开源项目,可以查看贡献指南获取更多信息。让我们共同努力,为AI安全贡献自己的力量! 🚀🛡️










