
MoE-LLaVA: 使用专家混合模型提升大型视觉语言模型性能
近年来,大型视觉语言模型(Large Vision-Language Models, LVLMs)在多模态理解和生成任务中取得了显著进展。然而,随着模型规模的不断扩大,训练和推理成本也随之大幅上升。为了解决这一问题,北京大学袁路教授团队提出了一种创新的稀疏LVLM架构——MoE-LLaVA,它巧妙地结合了专家混合(Mixture of Experts, MoE)技术和可学习的路由机制,在保持较少激活参数的同时实现了与更大规模密集模型相当甚至更优的性能。
MoE-LLaVA的核心思想
MoE-LLaVA的核心思想是将模型参数划分为多个"专家"子网络,并通过学习型路由器为每个输入token动态选择最适合的专家组合。具体来说,MoE-LLaVA包含以下关键组件:
-
多个专家子网络:模型参数被划分为多个并行的FFN(前馈网络)模块,每个模块专门处理特定类型的输入。
-
学习型路由器:一个轻量级的线性层,负责为每个输入token预测最适合的专家组合。
-
Top-k激活机制:对每个token,只激活路由器预测概率最高的k个专家进行计算,其他专家保持不活跃状态。
-
加权聚合:根据路由器的预测概率,对k个激活专家的输出进行加权求和,得到最终结果。
通过这种设计,MoE-LLaVA能够在推理时只激活模型参数的一小部分,大大降低了计算开销,同时保持了模型的强大表现力。
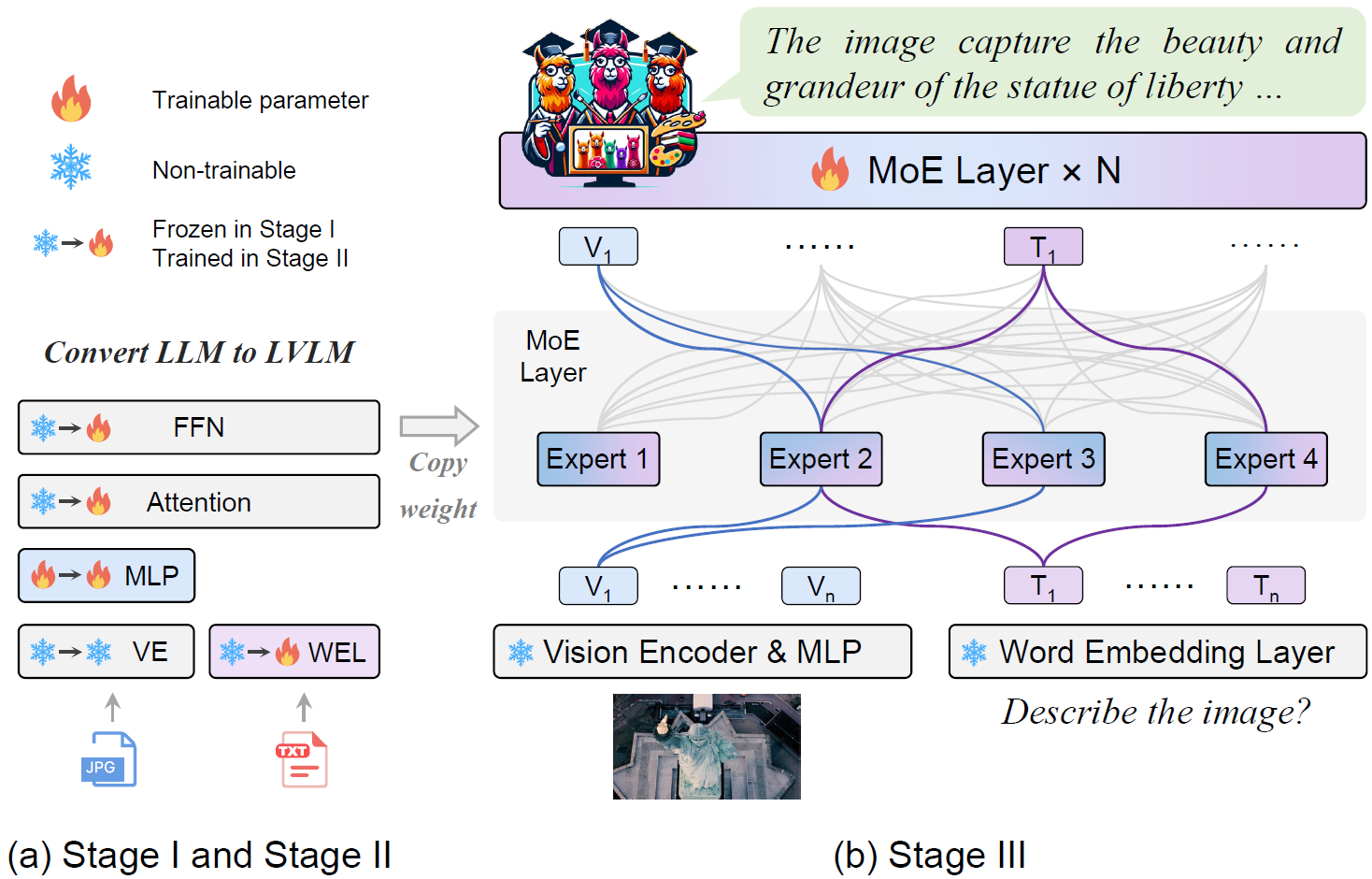
创新的MoE-Tuning训练策略
为了充分发挥MoE架构的潜力,研究团队提出了一种三阶段的MoE-Tuning训练策略:
-
第一阶段:冻结语言模型参数,仅训练视觉投影层,使模型初步具备图像理解能力。
-
第二阶段:解冻全部参数,在更复杂的多模态指令上进行微调,提升模型的跨模态理解能力。
-
第三阶段:复制FFN层初始化多个专家,引入MoE结构和路由机制,进行稀疏模型训练。
这种渐进式的训练方法有效地解决了多模态学习中常见的性能退化问题,使得MoE-LLaVA能够充分利用稀疏结构的优势。
卓越的性能表现
在多项视觉理解基准测试中,MoE-LLaVA展现出了令人印象深刻的性能:
-
仅使用3B稀疏激活参数,MoE-LLaVA-Phi-2.7B×4在多个视觉问答数据集上的表现与LLaVA-1.5-7B相当。
-
在SQAI数据集上,MoE-LLaVA-Phi-2.7B×4以3.6B稀疏激活参数超越了LLaVA-1.5-7B 2.7个百分点。
-
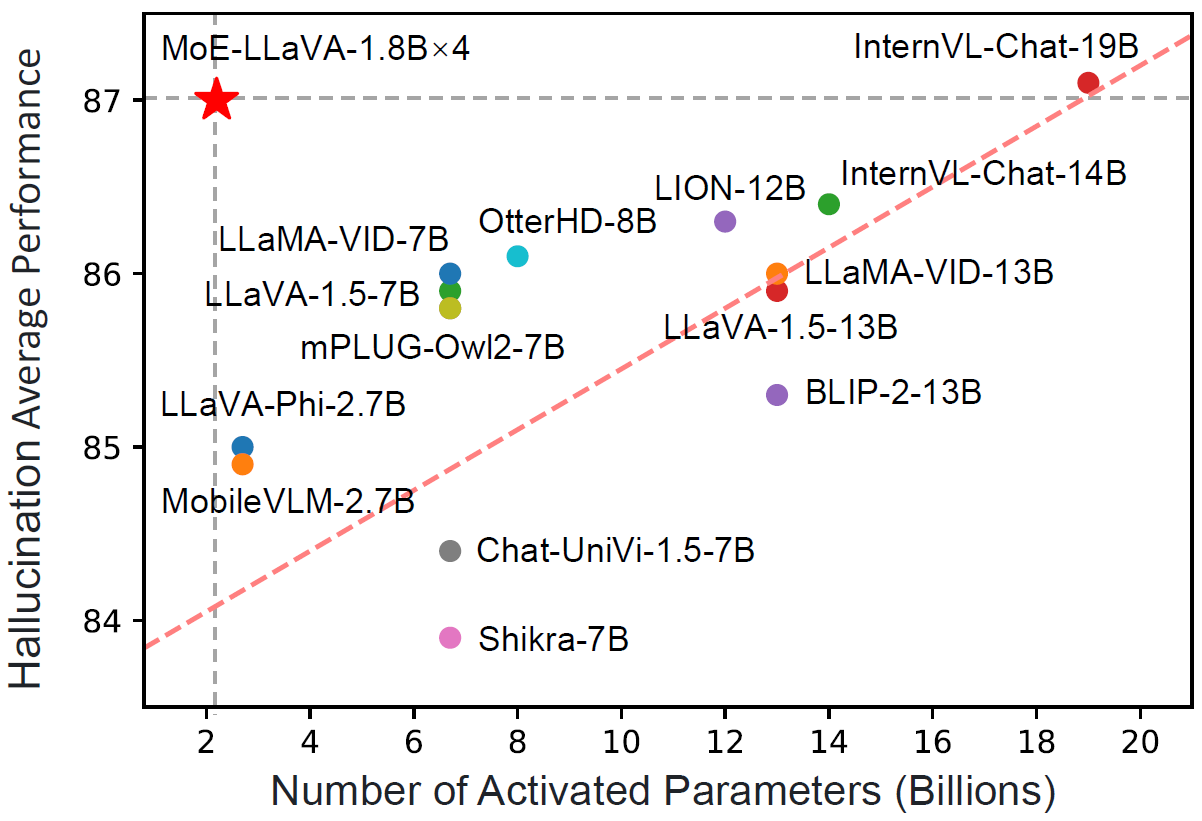
MoE-LLaVA-StableLM-1.6B×4仅使用2.0B激活参数就全面超越了IDEFICS-80B模型。
-
在物体幻觉评估中,MoE-LLaVA-1.8B×4(2.2B激活参数)的表现优于LLaVA-1.5-13B。
这些结果充分证明了MoE-LLaVA在保持较小计算开销的同时,能够达到甚至超越更大规模密集模型的性能。
深入分析专家行为
研究团队还对MoE-LLaVA中专家的行为进行了深入分析:
-
专家负载分布:在浅层,专家2、3、4主要协作,专家1逐渐退出;在深层,专家3的负载显著增加。
-
模态偏好:专家们对处理文本和图像token没有明显偏好,表明了强大的多模态交互能力。
-
激活路径:在token级别,专家2和3倾向于处理深层的未见文本和图像token,而专家1和4更多参与初始阶段处理。
这些发现为理解稀疏模型在多模态学习中的行为提供了宝贵见解。
开源与未来展望
为了推动相关研究的发展,研究团队已将MoE-LLaVA的完整代码和预训练模型开源在GitHub上(https://github.com/PKU-YuanGroup/MoE-LLaVA)。目前,团队正在进行以下工作:
-
训练更强大的高分辨率模型(如768×768)。
-
开发MoE-LLaVA-Qwen1.5版本,以更好地支持中文。
-
探索在其他多模态任务中应用MoE-LLaVA架构。
MoE-LLaVA的成功为构建更高效、更强大的大型视觉语言模型开辟了新的道路。随着研究的深入,我们有理由期待这一技术在未来能够推动多模态AI系统在实际应用中取得更大的突破。
总的来说,MoE-LLaVA代表了大型视觉语言模型领域的一项重要进展,它不仅在性能上达到了新的高度,更重要的是为如何构建高效且可扩展的多模态AI系统提供了宝贵的经验。随着相关研究的不断深入,我们可以期待看到更多基于MoE架构的创新应用,为人工智能的发展注入新的活力。










