Mol-Instructions: 一个大规模的生物分子指令数据集助力大型语言模型
 Ray
RayMol-Instructions: 一个大规模的生物分子指令数据集助力大型语言模型
随着大型语言模型(LLMs)的快速发展,其在各个领域展现出了卓越的任务处理能力和创新输出。然而,在生物分子研究等专业领域,LLMs的表现仍有待提高。为了解决这一挑战,研究人员推出了Mol-Instructions,一个专为生物分子领域设计的综合指令数据集。
Mol-Instructions的核心组成
Mol-Instructions包含三个关键组成部分:
-
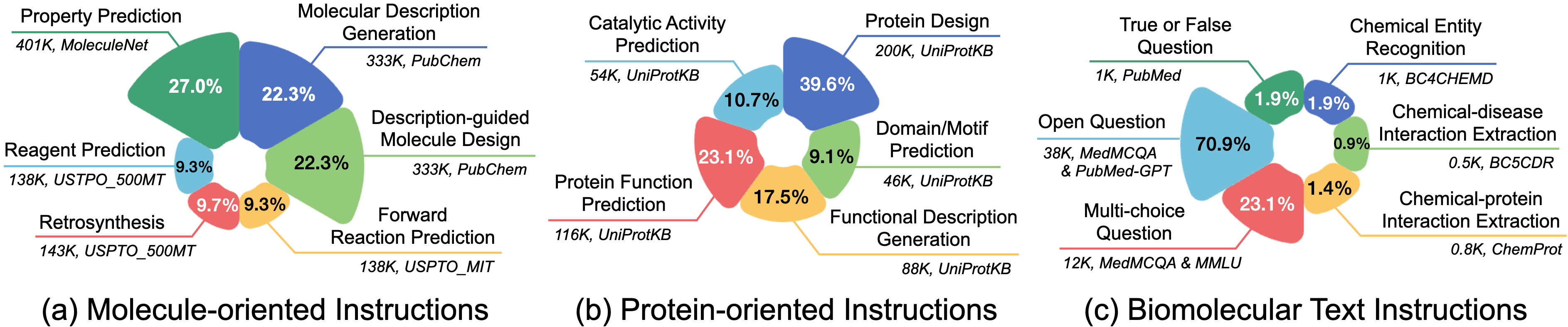
分子导向指令:专注于小分子的固有属性和行为,涵盖了各种化学反应和分子设计的基本挑战。该部分包含148.4K条指令,涉及6个任务。
-
蛋白质导向指令:立足于生物科学,提供了505K条指令,跨越5个不同类别的任务。这些任务旨在预测蛋白质的结构、功能和活性,并根据文本指令促进蛋白质设计。
-
生物分子文本指令:主要针对生物信息学和化学信息学领域的自然语言处理任务,包含6个信息提取和问答任务,共53K条指令。
数据构建过程
Mol-Instructions的数据构建过程经过精心设计,以确保数据的质量和多样性:
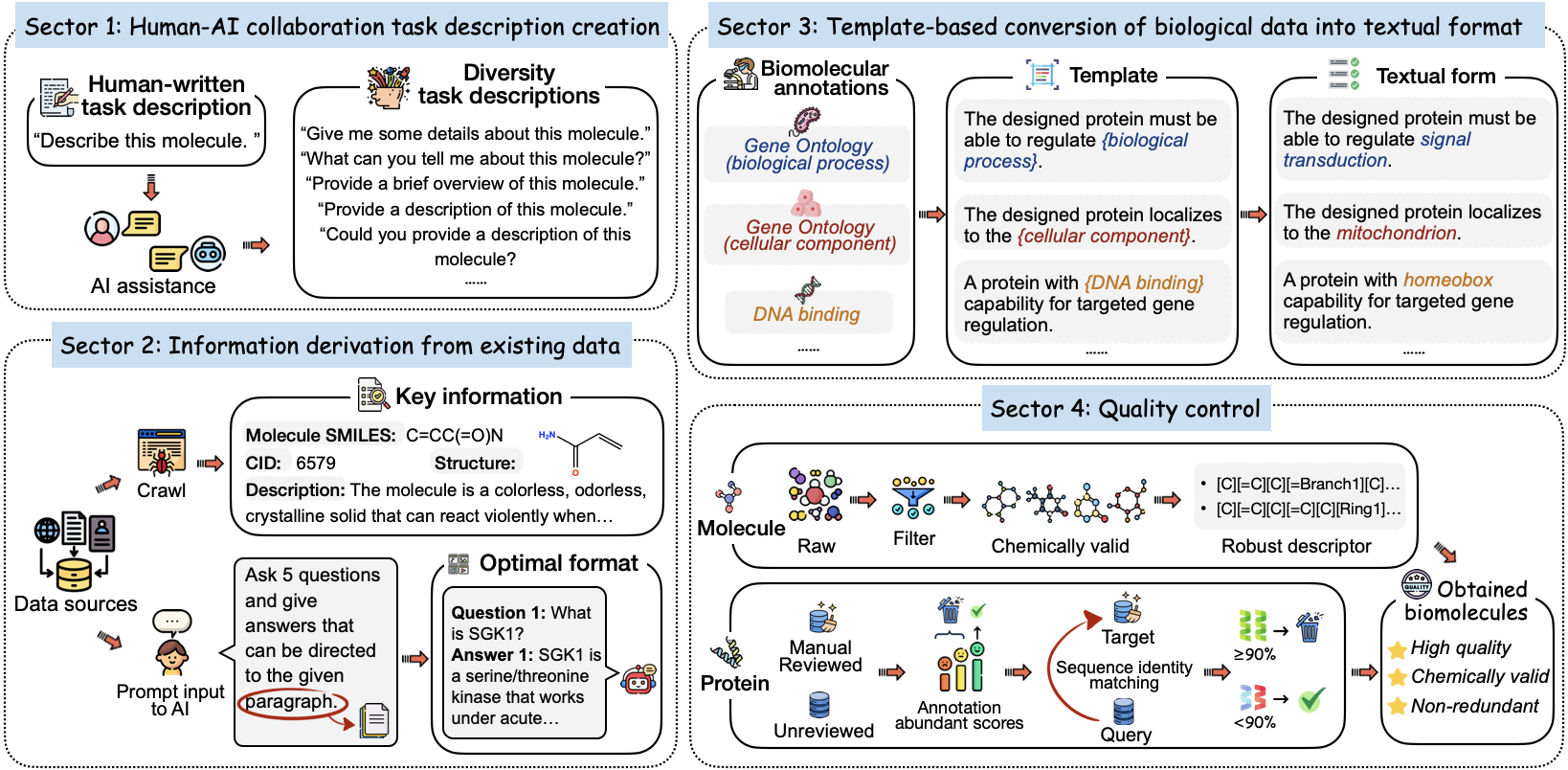
-
人机协作任务描述创建:研究人员首先为每个任务创建清晰的人工描述,然后将其作为输入提供给GPT-3.5-turbo,以生成多样化的任务指令。
-
从现有数据中提取信息:研究团队利用权威的生物化学数据库作为数据源,通过适当的处理提取所需的指令数据。
-
基于模板将生物数据转换为文本格式:设计了多种模板,将结构化注释转换为文本格式,每个文本注释都作为蛋白质设计的指导。
-
质量控制:为了加速模型生成精确的生物分子,研究人员对生物分子数据实施了严格的质量控制措施。
Mol-Instructions的应用与效果
为了验证Mol-Instructions对提��升LLMs在生物分子领域理解能力的效果,研究人员进行了一系列定量实验。实验结果表明,经过Mol-Instructions指令微调的模型在多个任务上都取得了显著的性能提升:
-
分子生成任务:
- 描述引导的分子设计
- 正向反应预测
- 逆合成
- 试剂预测
-
分子性质预测与理解任务:
- 性质预测
- 分子描述生成
- 蛋白质理解
-
生物信息学NLP任务:
- 问答和信息提取
- 化学实体识别
- 化学-疾病关系提取
- 化学-蛋白质关系提取
在这些任务中,经过Mol-Instructions微调的模型普遍优于基线模型,展现出了更强的生物分子理解和生成能力。
Mol-Instructions的开放与未来
Mol-Instructions数据集已在Hugging Face平台上公开发布,供研究人员使用。同时,研究团队也发布了基于LLaMA和LLaMA2微调的模型权重,涵盖分子导向、蛋白质导向和生物分子文本三个方向。
研究人员承诺将定期更新Mol-Instructions数据集,以提高其适用性。这一开放态度将有助于推动生物分子研究社区的进步,促进大型语言模型在该领域的应用和发展。
结语
Mol-Instructions的推出标志着大型语言模型在生物分子领域应用的一个重要里程碑。通过提供高质量、多样化的指令数据集,Mol-Instructions为LLMs在生物分子研究中的应用铺平了道路。未来,随着数据集的不断更新和完善,我们有理由期待看到更多创新性的应用出现,推动生物分子研究领域的快速发展。
通过Mol-Instructions,研究人员希望能够缩小大型语言模型在通用领域和专业生物分子领域之间的能力差距��。这不仅将提高模型在处理复杂生物分子问题时的准确性和效率,还有望激发新的研究方向和应用场景。
随着更多研究者加入到这一领域,我们可以预见Mol-Instructions将在推动生物分子研究、药物开发和相关领域的技术创新中发挥重要作用。这一数据集的开放性质也为跨学科合作提供了宝贵的机会,有望加速生命科学和人工智能的融合发展。
总的来说,Mol-Instructions的出现为大型语言模型在生物分子领域的应用开辟了新的前景。它不仅提供了丰富的训练资源,还为评估和改进模型在该领域的性能提供了基准。随着技术的不断进步和数据集的持续更新,我们有理由相信,Mol-Instructions将成为推动生物分子研究和人工智能交叉领域发展的重要驱动力。
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号