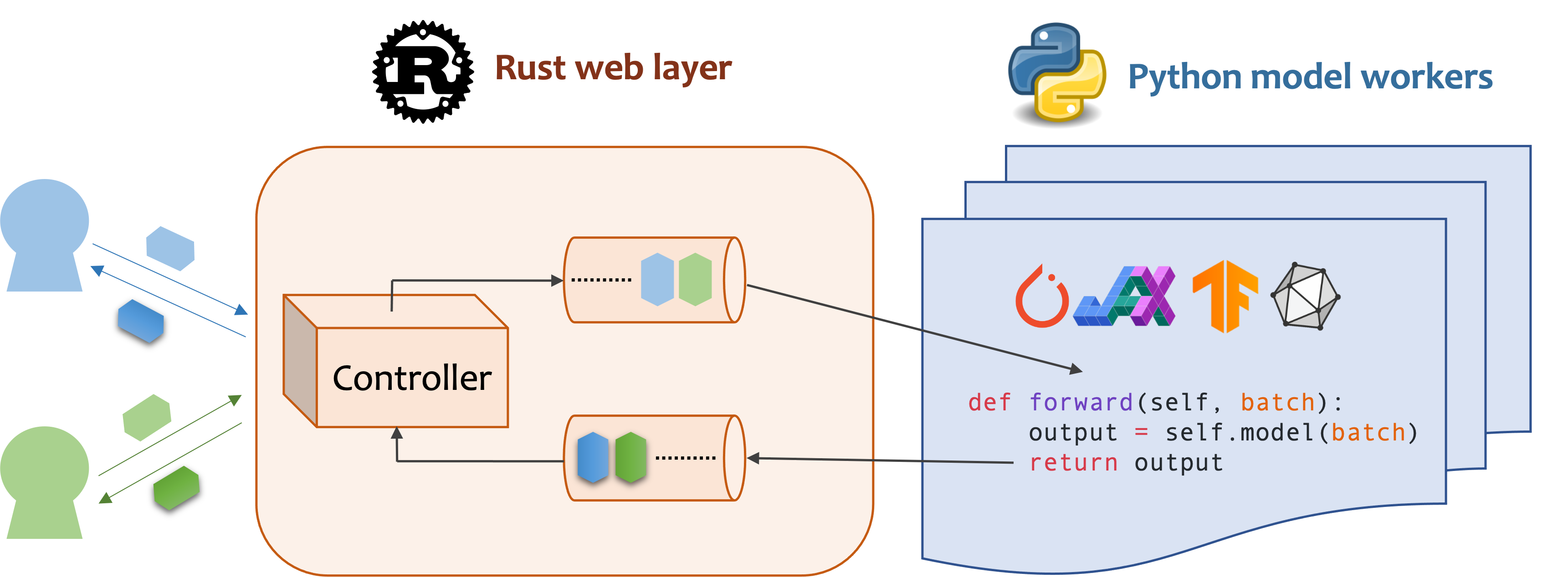
MOSEC简介
MOSEC(Model Serving made Efficient in the Cloud)是一个专为云环境设计的高性能机器学习模型服务框架。它旨在弥合刚刚训练完成的机器学习模型与高效在线服务API之间的鸿沟,让开发者能够轻松地将模型部署为生产级服务。

MOSEC具有以下主要特点:
-
高性能:Web层和任务协调使用Rust构建,提供极快的速度。异步I/O技术实现了高效的CPU利用率。
-
易用性:用户界面完全使用Python,开发者可以使用与离线测试相同的代码来部署模型,无需关心具体的ML框架。
-
动态批处理:自动聚合来自不同用户的请求进行批量推理,并将结果分发回去。
-
流水线处理:可以为流水线的不同阶段生成多个进程,以处理CPU/GPU/IO混合工作负载。
-
云友好:专为云环境设计,支持模型预热、优雅关闭和Prometheus监控指标,易于被Kubernetes等容器编排系统管理。
-
专注性:专注于在线服务部分,让用户可以将注意力集中在模型优化和业务逻辑上。
安装与使用
MOSEC要求Python 3.7或更高版本。可以通过pip安装最新的PyPI包:
pip install -U mosec
或者使用conda安装:
conda install conda-forge::mosec
下面我们通过一个示例来展示如何使用MOSEC托管一个预训练的Stable Diffusion模型作为服务。首先需要安装一些依赖:
pip install --upgrade diffusers[torch] transformers
编写服务器代码
以下是一个简单的服务器实现:
from io import BytesIO
from typing import List
import torch
from diffusers import StableDiffusionPipeline
from mosec import Server, Worker, get_logger
from mosec.mixin import MsgpackMixin
logger = get_logger()
class StableDiffusion(MsgpackMixin, Worker):
def __init__(self):
self.pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
)
device = "cuda" if torch.cuda.is_available() else "cpu"
self.pipe = self.pipe.to(device)
self.example = ["useless example prompt"] * 4 # warmup (batch_size=4)
def forward(self, data: List[str]) -> List[memoryview]:
logger.debug("generate images for %s", data)
res = self.pipe(data)
logger.debug("NSFW: %s", res[1])
images = []
for img in res[0]:
dummy_file = BytesIO()
img.save(dummy_file, format="JPEG")
images.append(dummy_file.getbuffer())
return images
if __name__ == "__main__":
server = Server()
server.append_worker(StableDiffusion, num=1, max_batch_size=4, max_wait_time=10)
server.run()
这段代码定义了一个StableDiffusion类,继承自Worker和MsgpackMixin。在__init__方法中,我们初始化了Stable Diffusion模型并将其移动到适当的设备上。forward方法定义了服务的核心逻辑,接收文本提示并生成相应的图像。
运行服务器
保存上述代码后,可以通过以下命令启动服务器:
python server.py --log-level debug --timeout 30000
服务器启动后,可以在浏览器中打开http://127.0.0.1:8000/openapi/swagger/查看OpenAPI文档。
高级特性
MOSEC提供了许多高级特性,使其成为一个强大的模型服务框架:
-
动态批处理:通过配置
max_batch_size和max_wait_time,MOSEC可以自动聚合请求进行批量推理,提高系统吞吐量。 -
多阶段流水线:可以将推理过程拆分为多个阶段,如预处理、模型推理和后处理,形成数据流水线,提高GPU利用率。
-
自定义指标:MOSEC允许用户定义和收集自定义指标,方便监控和优化服务性能。
-
共享内存IPC:对于多阶段服务,MOSEC支持使用共享内存进行进程间通信,potentially减少延迟。
-
GPU分配:可以为不同的工作进程分配不同的GPU,实现更灵活的资源利用。
性能调优
为了获得最佳性能,MOSEC提供了一些调优建议:
-
找出最佳的
max_batch_size和max_wait_time。可以通过监控指标来调整这两个参数。 -
尝试将推理过程拆分为独立的CPU和GPU阶段,充分利用硬件资源。
-
调整每个阶段的工作进程数量,以平衡各阶段的处理能力。
-
对于多阶段服务,考虑使用共享内存IPC来减少数据传输开销。
-
选择合适的序列化/反序列化方法。对于图像和嵌入等数据,考虑使用msgpack而不是JSON。
-
配置OpenBLAS或MKL的线程数,以优化CPU使用。
部署注意事项
在部署MOSEC服务时,需要注意以下几点:
-
MOSEC官方提供了预装框架的GPU基础镜像
mosecorg/mosec。 -
MOSEC服务应该作为容器中的PID 1进程运行,因为它需要控制多个子进程。
-
记得收集和监控服务指标,如批处理大小分布、处理时间等。
-
使用
SIGINT或SIGTERM信号来优雅地停止服务。
结语
MOSEC作为一个高性能的机器学习模型服务框架,为开发者提供了一种简单而强大的方式来部署和管理ML模型服务。通过其动态批处理、多阶段流水线等特性,MOSEC能够充分利用硬件资源,提供高效的推理服务。无论是对于个人开发者还是大型企业,MOSEC都是一个值得考虑的选择,可以帮助他们快速将ML模型转化为生产级服务。
随着机器学习技术的不断发展和应用场景的日益广泛,像MOSEC这样的工具将在未来扮演越来越重要的角色,推动AI技术的落地和产业化进程。我们期待看到MOSEC在未来的发展中为更多的开发者和企业带来价值,共同推动机器学习服务化的进步。