
MotionClone:无训练动作克隆技术引领视频生成新时代
在当今数字内容创作的时代,视频生成技术正以惊人的速度发展。然而,如何实现高质量、可控的视频生成一直是业界面临的挑战。近日,一项名为MotionClone的创新技术引起了广泛关注,这种无需训练的动作克隆框架为可控视频生成开辟了新的道路。
MotionClone:突破性的无训练框架
MotionClone是由一群杰出的研究人员开发的开源项目,旨在实现从参考视频中克隆动作,并将其应用于文本到视频的生成过程。这项技术的核心在于其无需训练的特性,这意味着用户可以快速、灵活地应用动作克隆,而无需耗时的模型训练过程。
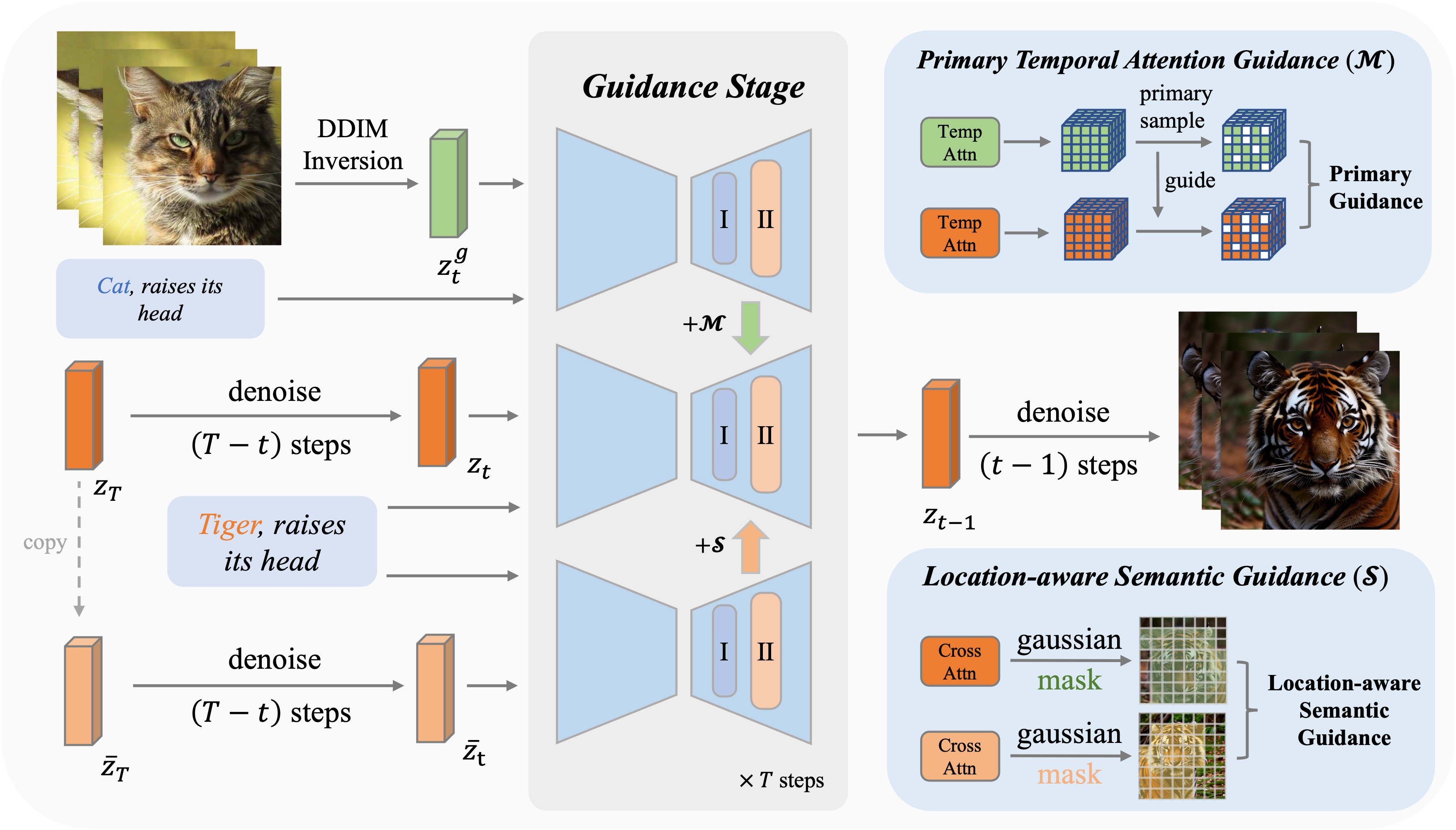
如上图所示,MotionClone的框架包含两个核心组件:主要时间注意力引导(Primary Temporal-Attention Guidance)和位置感知语义引导(Location-Aware Semantic Guidance)。这两个组件协同工作,为可控视频生成提供全面的动作和语义指导。
技术原理深度解析
- 时间注意力在视频反演中的应用
MotionClone利用时间注意力机制来表示参考视频中的动作。这种方法允许系统捕捉视频中的时间动态,从而更准确地克隆复杂的动作序列。
- 主要时间注意力引导
为了解决注意力权重中可能存在的噪声或微妙动作的影响,研究团队引入了主要时间注意力引导机制。这一创新有效地提高了动作克隆的质量和稳定性。
- 位置感知语义引导
为了帮助生成模型合成合理的空间关系并增强其遵循提示的能力,MotionClone采用了位置感知语义引导机制。这一机制利用参考视频中前景的粗略位置和原始的无分类器引导特征来指导视频生成过程。
MotionClone的应用前景
MotionClone的出现为多个领域带来了革命性的变化:
-
电影制作:filmmakers可以轻松地将经典角色的动作应用到新的场景中,创造出令人惊叹的视觉效果。
-
游戏开发:游戏设计师可以快速生成大量的角色动画,大大提高开发效率。
-
虚拟现实:VR内容创作者可以利用MotionClone创造更加真实和沉浸式的体验。
-
教育培训:可以生成各种示范视频,用于技能培训和教学演示。
-
社交媒体:内容创作者可以轻松制作有趣的视频效果,提高内容的吸引力。
使用MotionClone的步骤
要开始使用MotionClone,用户需要遵循以下步骤:
-
环境设置:
git clone https://github.com/Bujiazi/MotionClone.git cd MotionClone conda env create -f environment.yaml conda activate motionclone -
预训练模型准备:
- 下载Stable Diffusion V1.5
- 准备社区模型
- 准备AnimateDiff运动模块
-
执行DDIM反演:
python invert.py --config configs/inference_config/fox.yaml -
执行动作克隆:
python sample.py --config configs/inference_config/fox.yaml
MotionClone的未来发展
虽然MotionClone已经展现出了巨大的潜力,但研究团队并未就此止步。他们计划在未来发布Gradio演示、优化代码,并继续完善这项技术。社区的参与和反馈将在MotionClone的进一步发展中发挥关键作用。

结语
MotionClone的出现无疑为视频生成领域带来了一股新的革命性力量。它不仅简化了复杂的动作克隆过程,还为创作者提供了前所未有的创作自由。随着技术的不断完善和应用范围的扩大,我们可以期待看到更多令人惊叹的视频内容涌现。
对于那些对视频生成和人工智能技术感兴趣的研究者、开发者和创作者来说,MotionClone无疑是一个值得关注和尝试的项目。通过访问MotionClone的GitHub仓库,你可以深入了解这项技术,并为其发展贡献自己的力量。
让我们共同期待MotionClone为视频创作领域带来的无限可能!









