
MTEB: 大规模文本嵌入基准测试
在自然语言处理领域,文本嵌入技术一直是研究的热点。然而,现有的评估方法往往局限于单一任务或有限的数据集,难以全面衡量嵌入模型的性能。为了解决这个问题,研究人员推出了大规模文本嵌入基准测试(Massive Text Embedding Benchmark, MTEB)。MTEB是一个全面而强大的基准测试框架,旨在评估文本嵌入模型在多种任务和语言上的表现。
MTEB的主要特点
-
全面性: MTEB涵盖了8个嵌入任务,包括双语文本挖掘、分类、聚类、句对分类、重排序、检索、语义文本相似度(STS)和摘要。这些任务涉及58个数据集,横跨112种语言,使MTEB成为目前最全面的文本嵌入基准测试之一。
-
多语言支持: MTEB不仅包含英语数据集,还包括多语言和跨语言任务,能够评估模型在不同语言环境下的性能。
-
可扩展性: MTEB的设计允许轻松添加新的任务、数据集和评估指标,使其能够与时俱进,适应NLP领域的快速发展。
-
开源性: MTEB提供开源代码和公开的排行榜,方便研究人员和开发者使用和贡献。
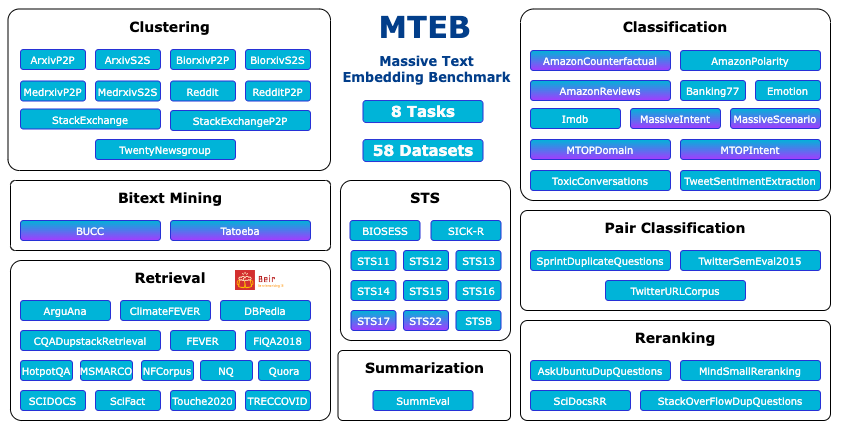
MTEB的工作原理
MTEB通过以下步骤评估文本嵌入模型:
-
任务选择: 用户可以选择特定的任务、语言或数据集类别进行评估。
-
模型编码: 模型将文本输入编码为向量表示。
-
任务评估: 对每个选定的任务,使用编码后的向量进行评估,计算相关的性能指标。
-
结果汇总: 汇总各个任务的评估结果,得出模型的整体性能评分。
使用MTEB进行模型评估
要使用MTEB评估你的模型,只需几个简单的步骤:
- 安装MTEB库:
pip install mteb
- 准备你的模型,确保它实现了
encode方法:
class MyModel:
def encode(self, sentences, **kwargs):
# 实现编码逻辑
pass
- 运行评估:
from mteb import MTEB
evaluation = MTEB(tasks=["Banking77Classification"])
results = evaluation.run(MyModel())
MTEB的影响和意义
MTEB的推出对NLP领域产生了深远的影响:
-
统一评估标准: MTEB为文本嵌入模型提供了一个统一的评估标准,使不同模型之间的比较更加公平和全面。
-
推动技术进步: 通过全面的评估,MTEB帮助研究人员发现模型的优势和不足,从而推动嵌入技术的不断改进。
-
应用场景指导: MTEB的多任务评估结果可以帮助开发者选择最适合特定应用场景的嵌入模型。
-
促进开放合作: 开源的特性使MTEB成为NLP社区合作和交流的平台,推动了领域的共同发展。
结论
MTEB作为一个全面、开放和可扩展的文本嵌入基准测试,为评估和比较不同的嵌入模型提供了宝贵的工具。它不仅帮助研究人员更好地理解现有模型的性能,也为未来嵌入技术的发展指明了方向。随着更多研究者和开发者的参与,MTEB将继续发展和完善,为NLP领域的进步做出重要贡献。
无论你是研究人员、开发者,还是对NLP感兴趣的学习者,MTEB都是一个值得关注和使用的重要资源。通过参与MTEB的评估和贡献,我们可以共同推动文本嵌入技术的发展,为更多智能应用铺平道路。










