
多智能体辩论:探索大语言模型的创新思维能力
在人工智能领域,大语言模型(LLMs)的认知行为一直备受关注。近年来,自反思等概念被证明在解决具有挑战性的自然语言处理任务中非常有效。然而,研究人员发现,自反思容易陷入"思维退化"(Degeneration of Thoughts, DoT)的问题。为了解决这个问题,研究人员提出了多智能体辩论(Multi-Agent Debate, MAD)框架,旨在通过多个大语言模型之间的辩论来激发创新思维,克服单一模型的认知局限性。
MAD框架的提出背景
自反思作为一种内部过程,虽然在解决复杂问题时显示出了强大的潜力,但也存在一些固有的局限性:
-
偏见和扭曲的认知:自我感知可能受到偏见、先入为主的观念和扭曲的思维模式的影响。如果个体的自反思被这些偏见或扭曲的思维所影响,可能会导致不准确的结论,阻碍个人成长。
-
僵化和抗拒变化:自反思通常涉及挑战个人的信念、假设和行为。如果个体抗拒变化或持有僵化的信念,他们可能难以进行有意义的自反思,从而影响个人成长。
-
外部反馈有限:自反思主要是一个内部过程,但外部反馈可以提供宝贵的视角和见解。如果不寻求或考虑外部反馈,个体可能会错过重要的盲点或可以丰富其自反思的替代观点。
为了克服这些局限性,研究人员提出了MAD框架,通过引入多个智能体之间的辩论来激发创新思维。
MAD框架的核心理念
MAD框架的核心理念是让多个大语言模型扮演不同的角色,进行"针锋相对"的辩论。在这个过程中:
- 一个智能体的扭曲思维可以被另一个智能体纠正。
- 一个智能体对变化的抗拒可以被另一个智能体的观点所补充。
- 每个智能体都可以为对方提供外部反馈。
这种设计使得MAD框架不太可能陷入思维退化的问题,并能够更好地发挥大语言模型的潜力。
MAD框架的应用与效果
研究人员在反直觉问答(Counterintuitive QA)和常识机器翻译(Commonsense-MT)等任务上进行了实验,结果显示MAD框架带来了显著且一致的改进。
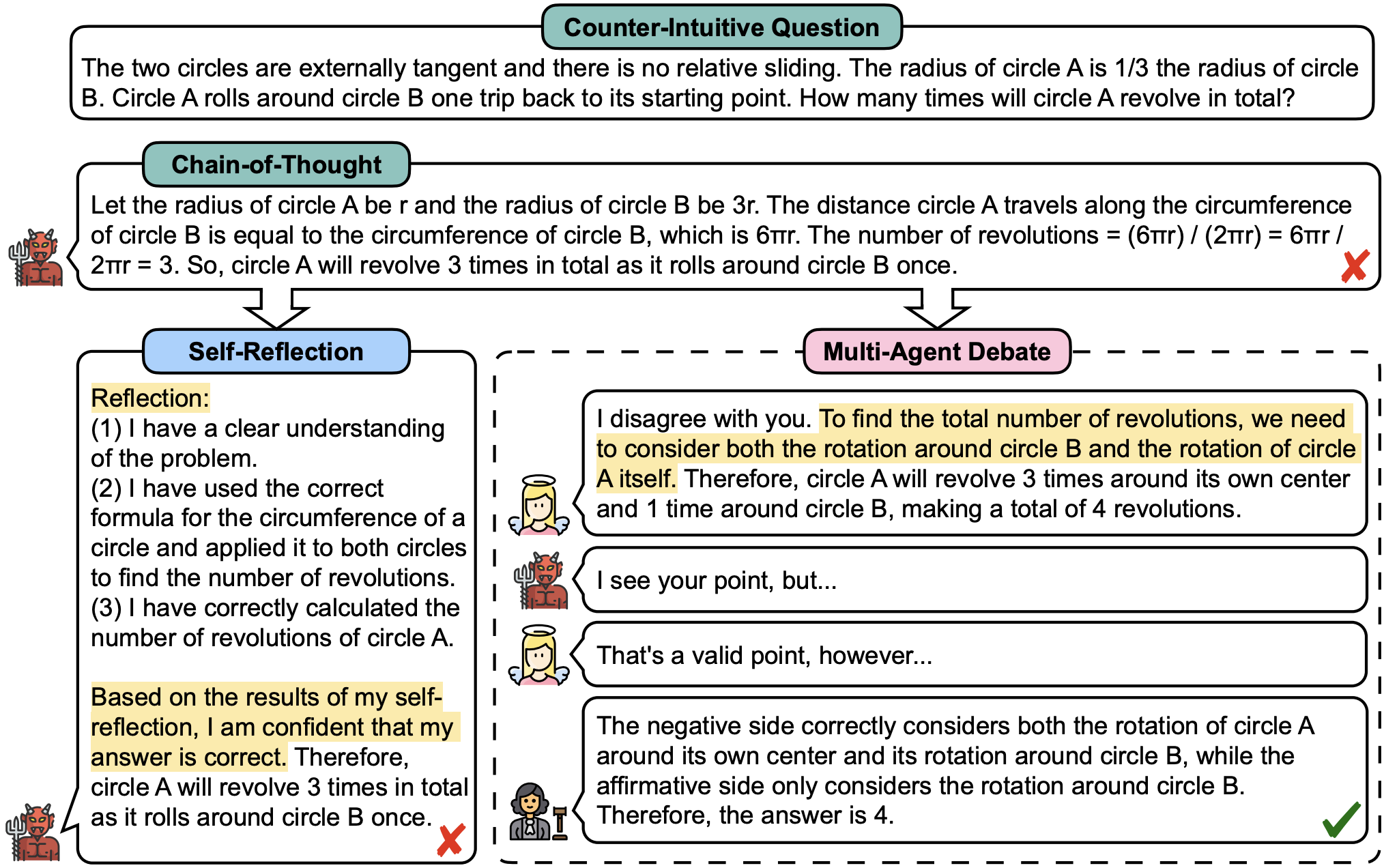
反直觉问答案例
以下是一个反直觉问答的案例,展示了MAD框架如何通过多个智能体的辩论得出正确答案:
问题:当爱丽丝上坡时,她的速度是1米/秒,下坡时速度是3米/秒。那么当爱丽丝上下坡时,她的平均速度是多少?(正确答案:1.5米/秒)

在这个案例中,我们可以看到:
- 第一个智能体(魔鬼)给出了一个直观但错误的答案(2米/秒)。
- 第二个智能体(天使)指出了问题中缺少的关键信息,即上下坡的距离。
- 裁判智能体提供了计算平均速度的正确方法。
- 经过多轮辩论,智能体们最终得出了正确的答案(1.5米/秒)。
这个过程展示了MAD框架如何通过多个智能体之间的辩论,逐步纠正错误,最终得出正确结论。
常识机器翻译案例
MAD框架在机器翻译任务中也展现出了优异的表现。以下是一个中文到英文翻译的案例:
中文句子:"吃掉敌人一个师。"
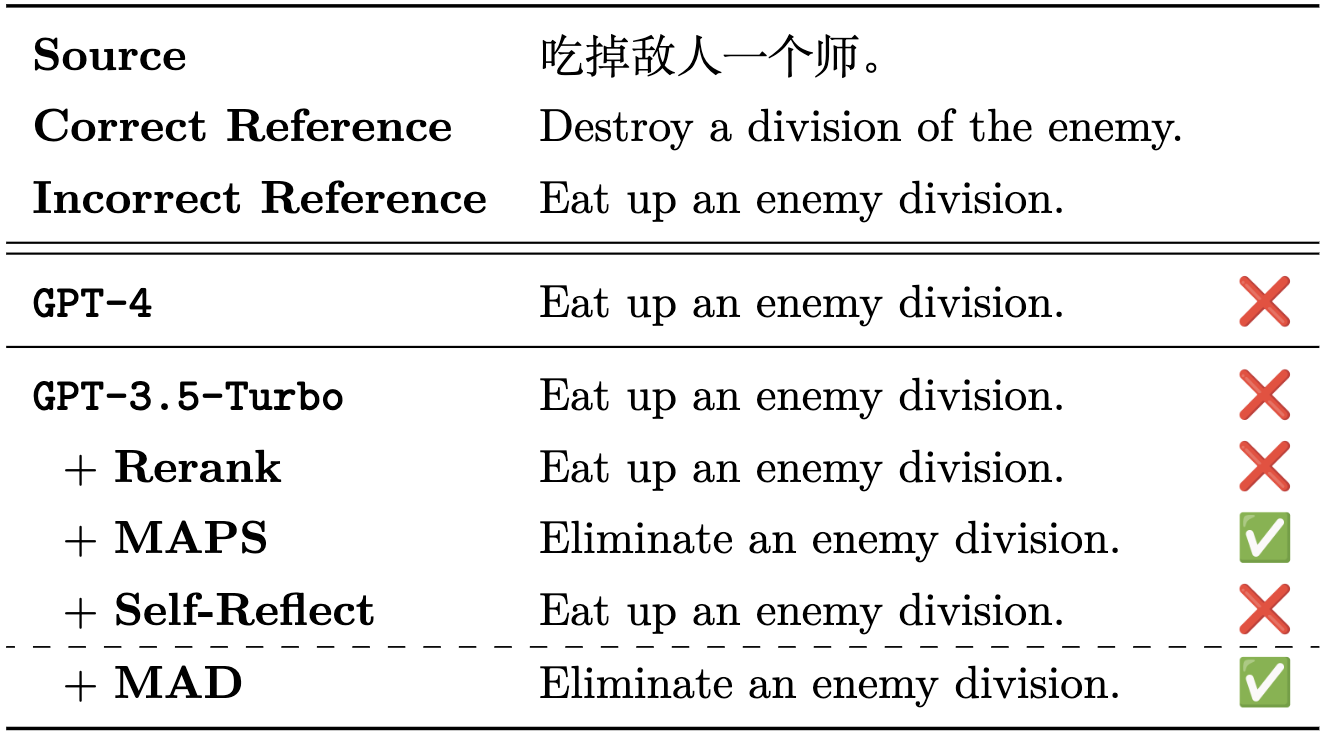
在这个案例中,MAD框架通过多个智能体的辩论,不仅准确理解了原文的军事隐喻,还在翻译中保留了这种修辞手法,最终给出了更加地道和准确的翻译结果。
MAD框架的优势与潜力
-
克服思维局限:通过引入多个智能体的不同视角,MAD框架能够有效克服单一模型的认知偏见和思维局限。
-
促进创新思维:智能体之间的辩论过程可以激发新的想法和观点,促进创新思维的产生。
-
提高问题解决能力:多个智能体的协作可以帮助更全面地分析问题,提高复杂任务的解决能力。
-
模拟人类思维过程:MAD框架的辩论过程在某种程度上模拟了人类的思考和讨论过程,有助于产生更接近人类思维的结果。
-
广泛应用潜力:除了已验证的反直觉问答和机器翻译任务,MAD框架有望在更多领域发挥作用,如决策支持、创意生成等。
结语
多智能体辩论(MAD)框架为探索大语言模型的创新思维能力开辟了一条新的道路。通过引入多个智能体之间的辩论,MAD框架不仅克服了单一模型的认知局限性,还在特定任务中展现出了显著的性能提升。随着研究的深入,我们有理由相信MAD框架将在更多领域发挥重要作用,推动人工智能向着更加智能和创新的方向发展。
正如研究者所说:"真理越辩越明。"通过MAD框架,我们期待看到大语言模型在"辩论"中不断进步,为人工智能的发展注入新的活力。
参考文献
-
Liang, T., He, Z., Jiao, W., Wang, X., Wang, Y., Wang, R., ... & Shi, S. (2023). Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. arXiv preprint arXiv:2305.19118.
-
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E., Le, Q., & Zhou, D. (2022). Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903.
-
Shinn, N., Labash, B., & Gopinath, A. (2023). Reflexion: an autonomous agent with dynamic memory and self-reflection. arXiv preprint arXiv:2303.11366.
-
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., & Zhou, D. (2023). Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
-
Zhang, C., Xiong, D., & Tu, Z. (2023). Exploring Human-Like Translation Strategy with Large Language Models. arXiv preprint arXiv:2305.04118.









