
Multi-Modality Arena:大型视觉语言模型的评估平台 🚀
Multi-Modality Arena 是一个专门用于评估大型多模态模型的综合评估平台。该平台遵循 Fastchat 的理念,通过并排比较两个匿名模型在视觉问答任务上的表现来进行评估。目前,平台已经发布了在线演示,欢迎大家参与到这项评估工作中来。
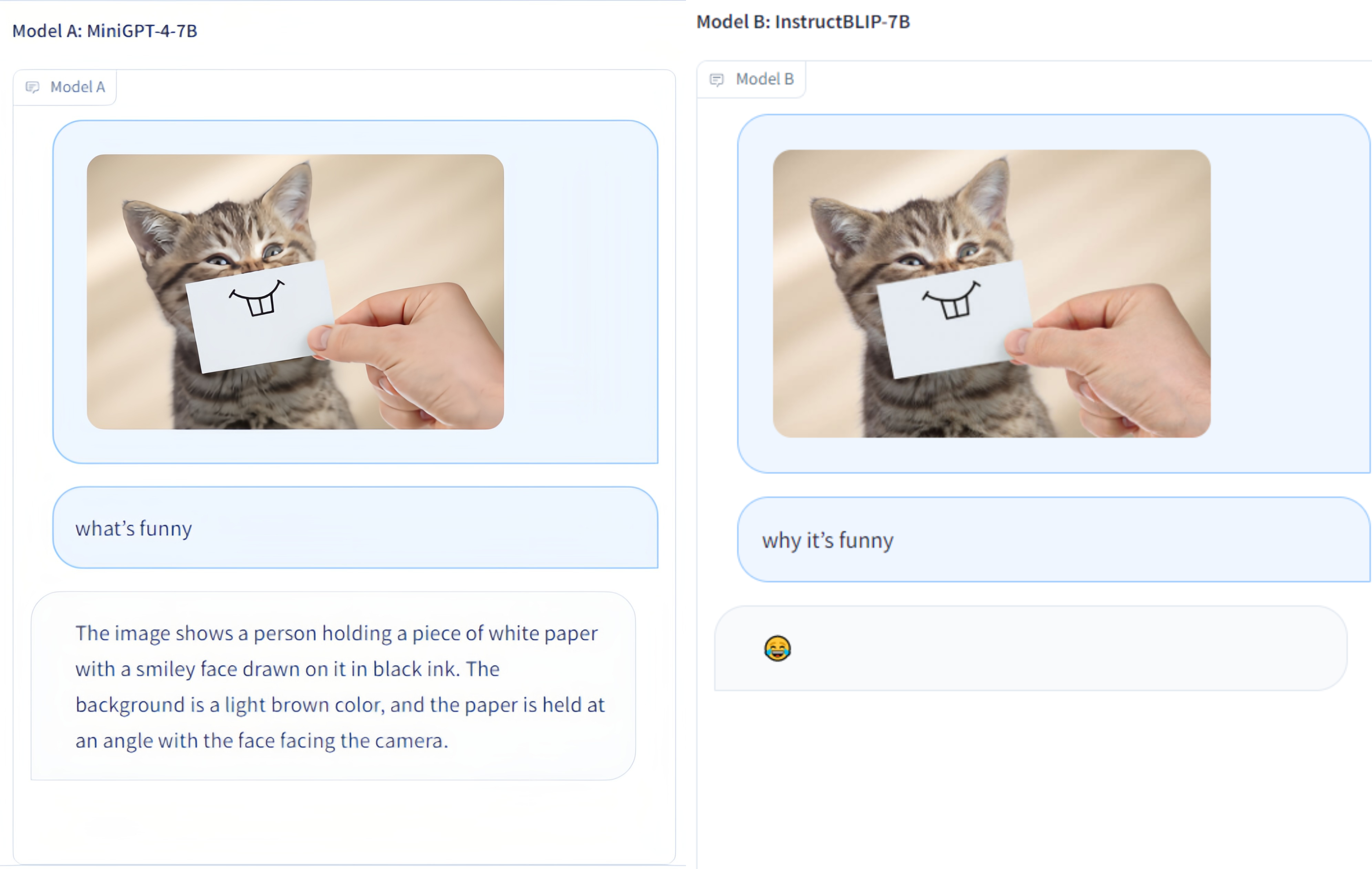
大型多模态模型的全面评估
OmniMedVQA:面向医学大型视觉语言模型的新型大规模综合评估基准
- OmniMedVQA 数据集:包含 118,010 张图像和 127,995 个问答项,涵盖 12 种不同的医学成像模态,涉及 20 多个人体解剖区域。数据集可以从这里下载。
- 评估模型:包括 8 个通用领域的大型视觉语言模型和 4 个专门针对医学领域的大型视觉语言模型。
Tiny LVLM-eHub:与 Bard 的早期多模态实验
- 小型数据集:每个数据集仅随机选择 50 个样本,共包括 42 个文本相关的视觉基准测试,总计 2.1K 个样本,便于使用。
- 更多模型:新增 4 个模型,总计 12 个模型,包括 Google Bard。
- ChatGPT 集成评估:相比之前的词匹配方法,与人工评估的一致性有所提高。
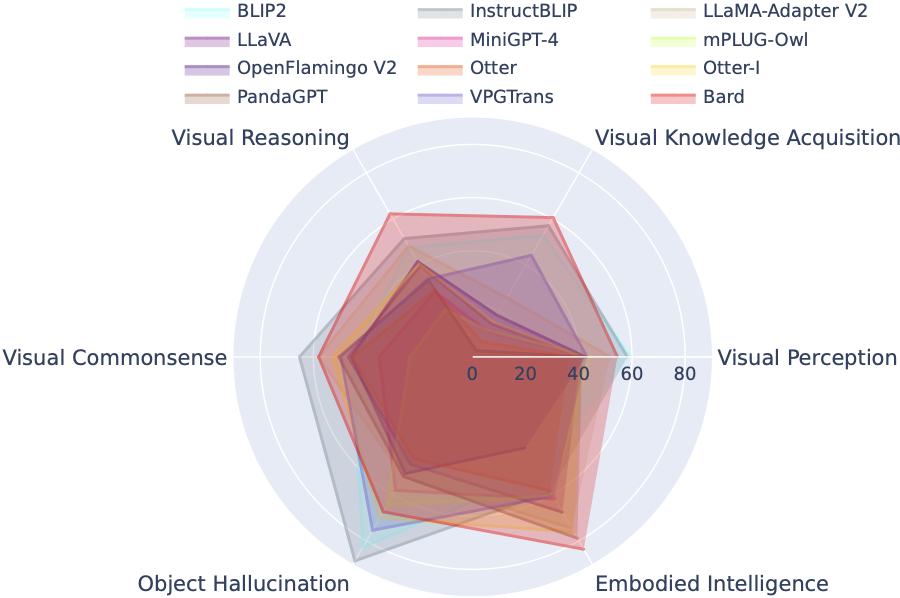
LVLM-eHub:大型视觉语言模型的评估基准 🚀
LVLM-eHub 是一个针对公开可用的大型多模态模型(LVLM)的综合评估基准。它通过 47 个数据集和 1 个在线竞技场平台,从 6 个类别的多模态能力方面对 8 个 LVLM 进行了广泛评估。
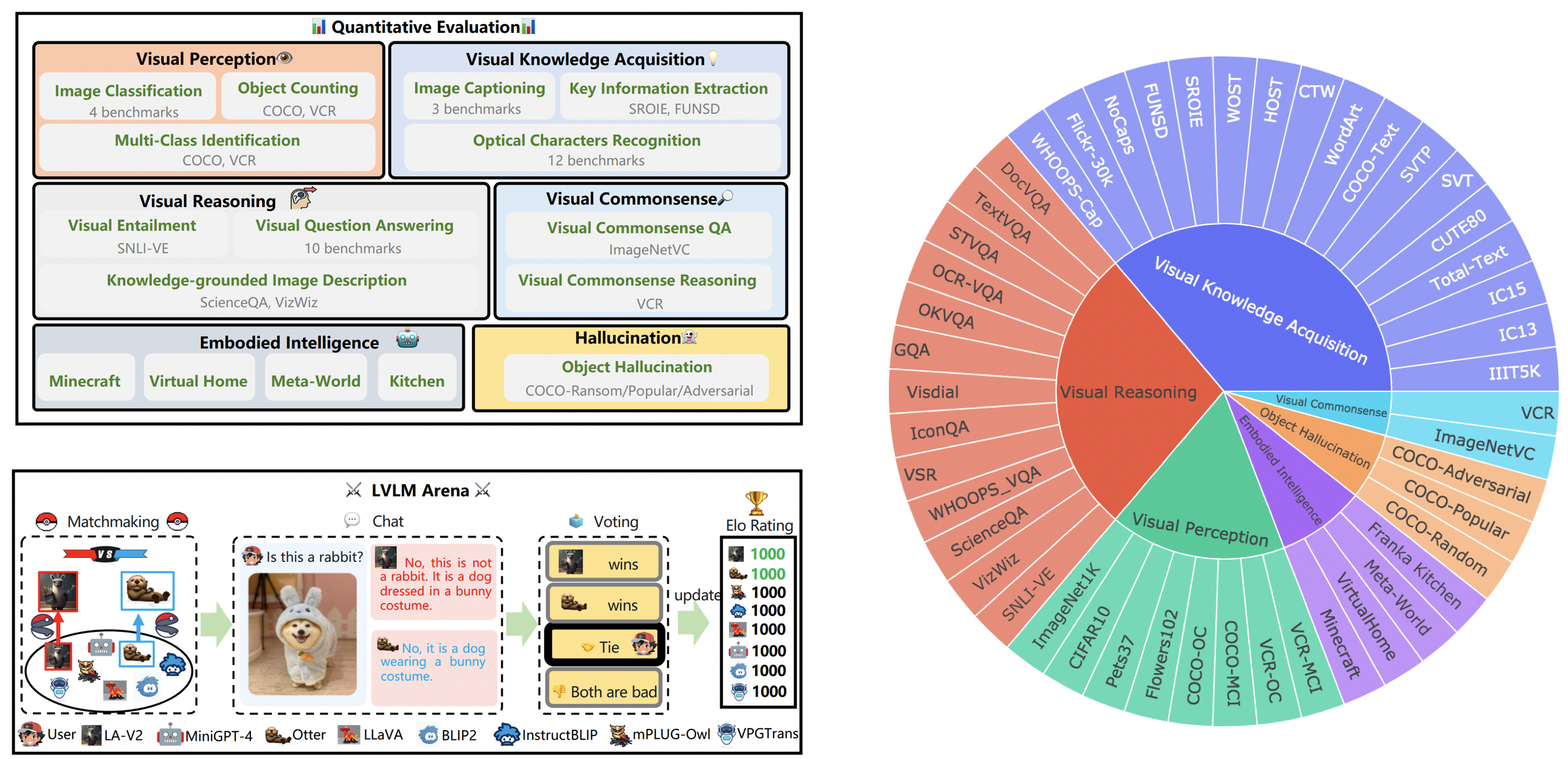
LVLM 排行榜
LVLM 排行榜根据 Tiny LVLM 评估中的数据集,系统地将其分类为视觉感知、视觉推理、视觉常识、视觉知识获取和物体幻觉等特定目标能力。该排行榜还包括了最近发布的模型,以增强其全面性。
以下是部分模型的排名情况:
- 🏅️ InternVL (InternVL-Chat): 327.61 分
- 🥈 InternLM-XComposer-VL (InternLM-XComposer-VL-7B): 322.51 分
- 🥉 Bard (Bard): 319.59 分
- Qwen-VL-Chat (Qwen-VL-Chat): 316.81 分
- LLaVA-1.5 (Vicuna-7B): 307.17 分
支持的多模态模型
目前,以下模型参与随机对战:
- KAUST/MiniGPT-4
- Salesforce/BLIP2
- Salesforce/InstructBLIP
- DAMO Academy/mPLUG-Owl
- NTU/Otter
- University of Wisconsin-Madison/LLaVA
- Shanghai AI Lab/llama_adapter_v2
- NUS/VPGTrans
关于这些模型的更多详细信息可以在 ./model_detail/.model.jpg 中找到。我们将努力安排计算资源,以在竞技场中托管更多的多模态模型。
安装与使用
- 创建 conda 环境:
conda create -n arena python=3.10
conda activate arena
- 安装运行控制器和服务器所需的包:
pip install numpy gradio uvicorn fastapi
- 对于每个模型,由于它们可能需要冲突的 Python 包版本,我们建议根据其 GitHub 仓库为每个模型创建一个特定的环境。
启动演示
要使用 Web UI 提供服务,您需要三个主要组件:与用户交互的 Web 服务器、托管两个或多个模型的模型工作器,以及协调 Web 服务器和模型工作器的控制器。
- 启动控制器
- 启动模型工作器
- 启动 Gradio Web 服务器
按照这些步骤,您将能够使用 Web UI 提供模型服务。现在,您可以打开浏览器并与模型进行对话。如果模型没有显示,请尝试重新启动 Gradio Web 服务器。
贡献指南
我们非常重视所有旨在提高评估质量的贡献。本节包括两个关键部分:"对 LVLM 评估的贡献"和"对 LVLM 竞技场的贡献"。
对 LVLM 评估的贡献
您可以在 LVLM_evaluation 文件夹中访问我们最新版本的评估代码。该目录包括一套全面的评估代码,以及必要的数据集。如果您热衷于参与评估过程,请随时通过电子邮件 xupeng@pjlab.org.cn 与我们分享您的评估结果或模型推理 API。
对 LVLM 竞技场的贡献
我们感谢您有兴趣将您的模型整合到我们的 LVLM 竞技场中!如果您希望将您的模型纳入我们的竞技场,请按照指定的结构准备一个模型测试器。此外,我们也欢迎在线模型推理链接,例如 Gradio 等平台提供的链接。我们衷心感谢您的贡献。
致谢
我们要感谢 ChatBot Arena 团队及其论文 "Judging LLM-as-a-judge" 的出色工作,这为我们的 LVLM 评估工作提供了灵感。我们还要向 LVLM 提供者表示诚挚的感谢,他们的宝贵贡献极大地促进了大型视觉语言模型的进步和发展。最后,我们感谢 LVLM-eHub 中使用的数据集的提供者。
使用条款
该项目是一个仅用于非商业目的的实验性研究工具。它具有有限的安全保障,可能会生成不适当的内容。不得将其用于任何非法、有害、暴力、种族主义或色情的用途。
Multi-Modality Arena 为研究人员和开发者提供了一个强大的平台,用于评估和比较各种大型视觉语言模型的性能。通过其全面的评估基准、排行榜和在线竞技场,该项目为推动多模态 AI 技术的发展做出了重要贡献。随着更多模型和数据集的加入,Multi-Modality Arena 将继续发挥重要作用,帮助我们更好地理解和改进大型视觉语言模型的能力。









