
Multimodal-GPT:开启人机多模态对话新纪元
在人工智能快速发展的今天,实现机器与人类之间的自然对话一直是研究人员追求的目标。近日,由OpenMMLab团队开发的Multimodal-GPT模型在这一领域取得了重大突破。这个基于视觉和语言的多模态对话系统,不仅能够理解图像内容,还能与人类进行流畅的多轮对话。让我们一起来深入了解这个令人兴奋的项目。
Multimodal-GPT的核心特性
Multimodal-GPT是一个建立在OpenFlamingo开源多模态模型基础上的创新性项目。它的主要特点包括:
- 支持多种视觉和语言指令数据
- 使用LoRA(Low-Rank Adaptation)进行参数高效微调
- 同时调整视觉和语言模型,实现互补增强
这些特性使得Multimodal-GPT能够理解复杂的视觉场景,并基于图像内容与用户进行自然对话。
模型架构与训练方法
Multimodal-GPT的核心是对OpenFlamingo模型进行了参数高效的微调。研究人员在模型的交叉注意力和自注意力部分都添加了LoRA适配器,这种方法既保持了原始模型的性能,又大大提高了训练效率。
在训练数据方面,研究团队创造性地结合了多种开放数据集,包括:
- VQA(视觉问答)
- 图像描述
- 视觉推理
- 文本OCR
- 视觉对话
除此之外,他们还使用纯语言指令数据训练了OpenFlamingo的语言模型部分。这种视觉和语言指令的联合训练策略显著提升了模型的整体性能。
安装与使用
对于想要尝试Multimodal-GPT的开发者,项目提供了详细的安装说明:
- 克隆项目仓库:
git clone https://github.com/open-mmlab/Multimodal-GPT.git
cd Multimodal-GPT
- 安装依赖:
pip install -r requirements.txt
pip install -v -e .
或者创建新的conda环境:
conda env create -f environment.yml
- 下载预训练权重
项目使用了多个预训练模型,包括LLaMA、OpenFlamingo以及Multimodal-GPT的LoRA权重。开发者需要按照指引下载这些模型并放置在正确的目录中。
应用示例
Multimodal-GPT展示了令人印象深刻的多模态对话能力。以下是几个典型的应用场景:
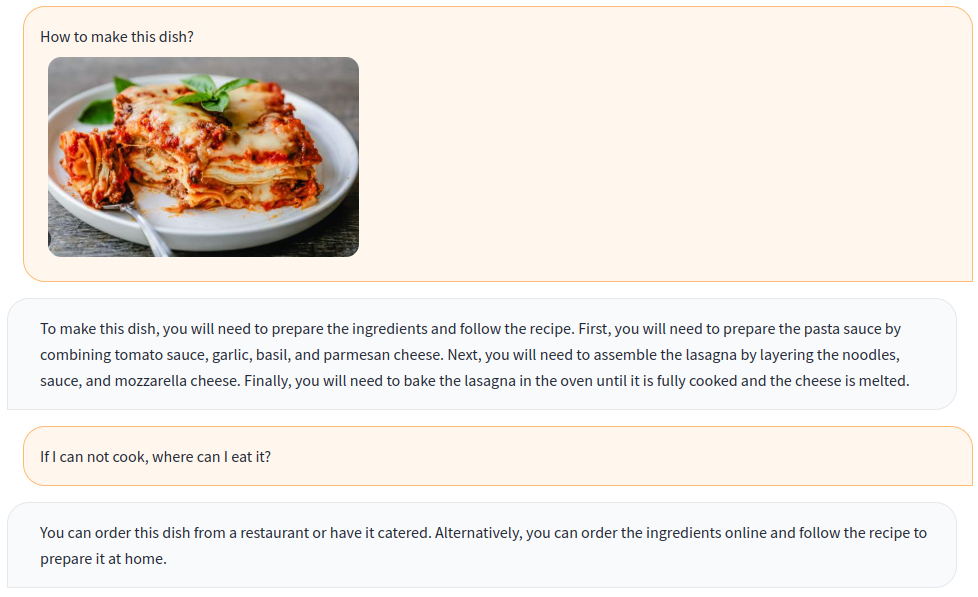
-
菜谱生成 用户可以上传一张食物图片,Multimodal-GPT能够识别图中的食材,并生成相应的菜谱。
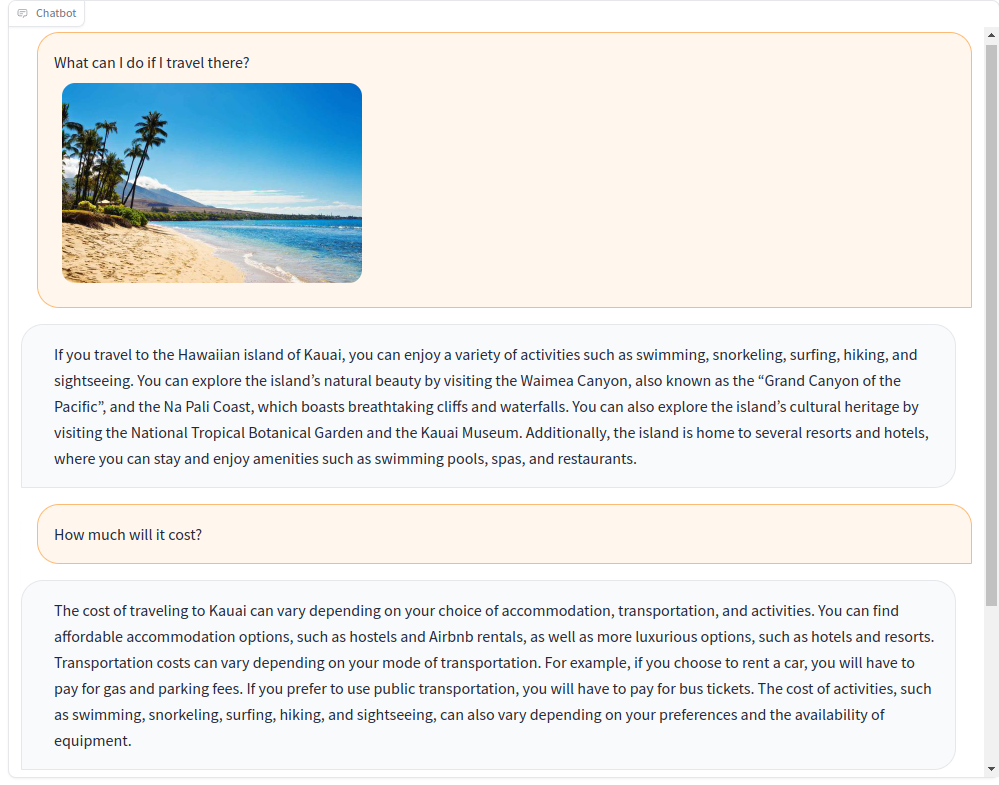
-
旅行计划 基于景点照片,模型可以推荐详细的旅行计划,包括景点介绍、游览时间等。
-
电影分析 通过电影海报或场景截图,Multimodal-GPT能够分析电影类型、主题,甚至推测剧情。
-
名人识别 模型可以识别图片中的名人,并提供相关背景信息。
这些示例充分展示了Multimodal-GPT在理解视觉内容和生成相关文本方面的强大能力。
模型微调
对于希望进一步提升模型性能或适应特定领域的研究者,Multimodal-GPT提供了详细的微调指南。项目支持多个数据集,包括A-OKVQA、COCO Caption、OCR VQA等。研究者可以根据需求选择合适的数据集进行微调。
微调命令示例:
torchrun --nproc_per_node=8 mmgpt/train/instruction_finetune.py \
--lm_path checkpoints/llama-7b_hf \
--tokenizer_path checkpoints/llama-7b_hf \
--pretrained_path checkpoints/OpenFlamingo-9B/checkpoint.pt \
--run_name train-my-gpt4 \
--learning_rate 1e-5 \
--lr_scheduler cosine \
--batch_size 1 \
--tuning_config configs/lora_config.py \
--dataset_config configs/dataset_config.py \
--report_to_wandb
这种灵活的微调能力使得Multimodal-GPT可以适应各种特定场景的需求。
项目影响与未来展望
Multimodal-GPT的出现标志着多模态人工智能领域的一个重要里程碑。它不仅展示了将大型语言模型与视觉理解相结合的可能性,还为未来更加智能的人机交互系统铺平了道路。
随着技术的不断进步,我们可以期待Multimodal-GPT在以下方面有更多突破:
- 更强的跨模态理解能力
- 支持更多类型的多模态输入(如音频、视频)
- 更自然、更具情感的对话能力
- 在特定领域(如医疗、教育)的深度应用
Multimodal-GPT项目的开源性质也为整个AI社区带来了宝贵的资源。研究者和开发者可以基于这个项目进行进一步的创新和应用开发,推动多模态AI技术的整体进步。
结语
Multimodal-GPT的出现无疑为人工智能领域带来了新的可能性。它不仅展示了多模态模型的强大潜力,也为未来更智能、更自然的人机交互系统指明了方向。随着技术的不断发展和完善,我们有理由相信,像Multimodal-GPT这样的系统将在不久的将来改变我们与技术交互的方式,为人类社会带来更多便利和创新。
对于有兴趣深入了解或参与Multimodal-GPT项目的读者,可以访问项目的GitHub仓库获取更多信息。让我们共同期待Multimodal-GPT及类似技术在未来带来的无限可能!










