
MyScaleDB:为AI应用打造的开源SQL向量数据库
在人工智能和机器学习技术快速发展的今天,如何高效管理和处理海量的结构化数据和非结构化数据,成为了许多开发者面临的一大挑战。为了解决这一问题,MyScale团队推出了开源的SQL向量数据库MyScaleDB,旨在让每个开发者都能使用熟悉的SQL构建生产级别的AI应用。
MyScaleDB的核心优势
MyScaleDB是一个基于ClickHouse构建的开源SQL向量数据库,专为AI应用和解决方案进行了优化。它具有以下几个核心优势:
- 完全兼容SQL
MyScaleDB提供快速、强大和高效的向量搜索、过滤搜索和SQL-向量联合查询功能。开发者可以使用带有向量相关函数的SQL与MyScaleDB进行交互,无需学习复杂的新工具或框架,只需使用熟悉的SQL即可。
- 为AI应用生产环境做好准备
MyScaleDB提供了一个统一的平台来管理和处理结构化数据、文本、向量、JSON、地理空间和时间序列数据等。通过将向量与丰富的元数据结合,并执行高精度、高效率的过滤搜索,MyScaleDB可以显著提高RAG(检索增强生成)的准确性。
- 卓越的性能和可扩展性
MyScaleDB利用先进的OLAP数据库架构和高级向量算法,实现了闪电般快速的向量操作。随着数据量的增长,开发者可以轻松且经济高效地扩展应用程序。
为什么选择MyScaleDB?
与使用自定义API的专用向量数据库相比,MyScaleDB在保持简单易用的同时,提供了更强大、更高性能和更具成本效益的解决方案。这使得它适用于更广泛的程序员群体。此外,与集成了向量功能的PostgreSQL(pgvector)或ElasticSearch等数据库相比,MyScaleDB在结构化和向量联合查询(如过滤搜索)方面消耗更少的资源,同时实现了更好的准确性和速度。
MyScaleDB的独特之处在于它将SQL数据库/数据仓库、向量数据库以及全文搜索引擎这三个系统高效地统一到了一个系统中。这不仅节省了基础设施和维护成本,还实现了联合数据查询和分析。
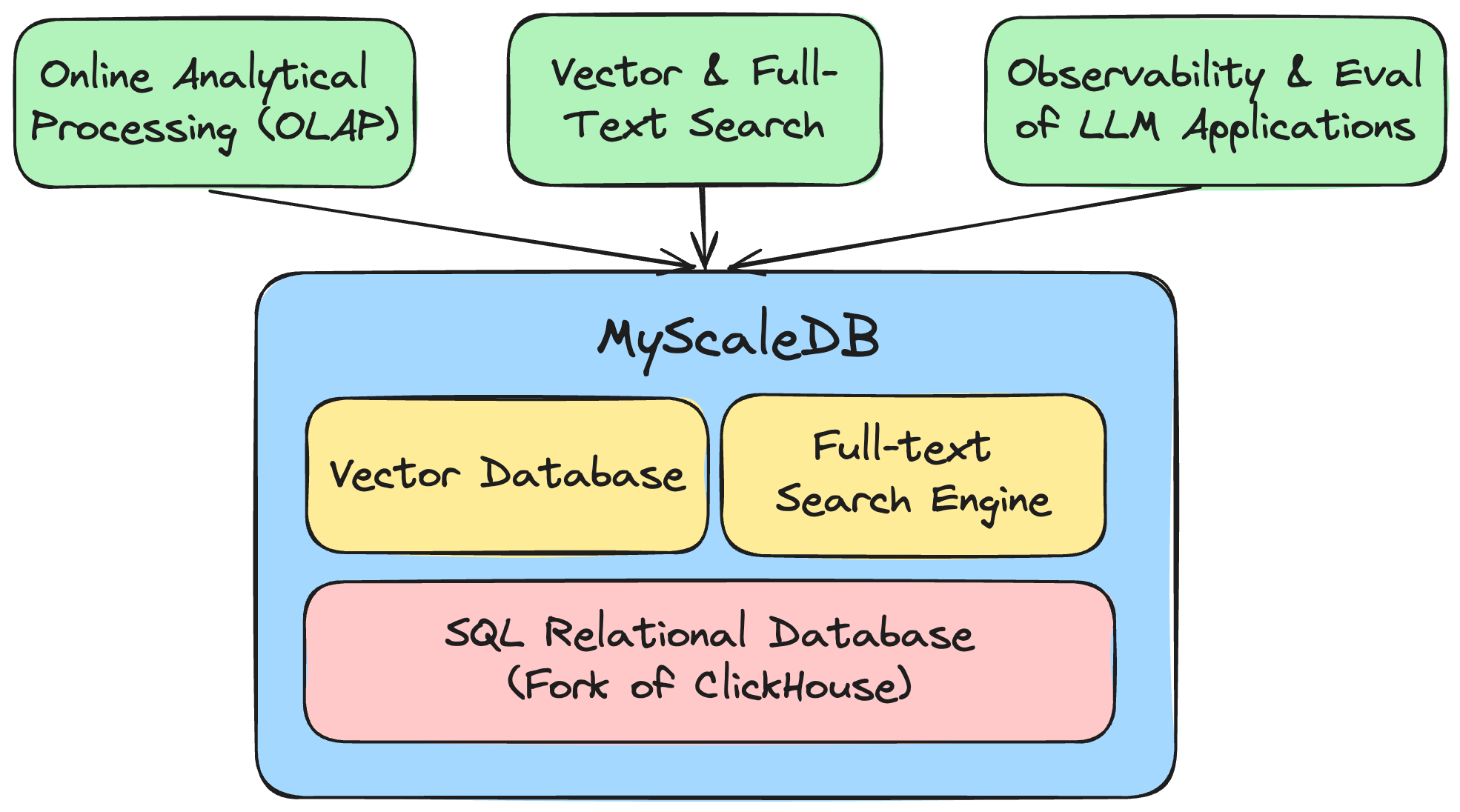
为什么基于ClickHouse构建MyScaleDB?
ClickHouse是一个流行的开源分析型数据库,凭借其列式存储、高级压缩、跳跃索引和SIMD处理等特性,在大数据处理和分析方面表现出色。与使用行存储并主要针对事务处理进行优化的PostgreSQL和MySQL等事务型数据库不同,ClickHouse在分析和数据扫描速度方面明显更快。
在结合结构化和向量搜索时,一个关键操作是过滤搜索,即先按其他属性进行过滤,然后对剩余数据执行向量搜索。列式存储和预过滤对于确保过滤搜索的高准确性和高性能至关重要,这也是我们选择在ClickHouse基础上构建MyScaleDB的原因。
快速开始使用MyScaleDB
开始使用MyScaleDB的最简单方法是在MyScale Cloud服务上创建一个实例。您可以从支持500万个768维向量的免费实例开始。只需在MyScale官网注册,然后查看MyScaleDB快速入门指南获取更多说明。
对于希望自行部署的用户,MyScaleDB提供了Docker镜像,可以通过以下命令快速启动一个MyScaleDB实例:
docker run --name myscaledb --net=host myscale/myscaledb:1.6.4
这将启动一个默认用户为default且无密码的MyScaleDB实例。然后,您可以使用clickhouse-client连接到数据库:
docker exec -it myscaledb clickhouse-client
创建带有向量列的表
以下是创建一个包含384维向量列的表的示例:
CREATE TABLE default.wiki_abstract
(
`id` UInt64,
`body` String,
`title` String,
`url` String,
`body_vector` Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 384
)
ENGINE = MergeTree
ORDER BY id;
创建向量索引
创建表后,您可以为向量列添加索引以加速查询:
ALTER TABLE default.wiki_abstract ADD VECTOR INDEX vec_idx body_vector TYPE SCANN('metric_type=Cosine');
执行向量搜索
创建索引后,您就可以执行向量搜索了:
SELECT
id,
title,
distance(body_vector, [-0.052, -0.0146, -0.0677, ...]) AS distance
FROM default.wiki_abstract
ORDER BY distance
LIMIT 5;
这个查询将返回与给定向量最相似的前5个结果。
结语
MyScaleDB作为一个开源的SQL向量数据库,为AI应用开发者提供了一个强大而灵活的工具。它不仅保留了传统SQL数据库的易用性,还融合了向量数据库的高效搜索能力和全文搜索引擎的功能。无论您是在构建下一代AI应用,还是在优化现有的数据处理流程,MyScaleDB都能为您提供所需的性能、可扩展性和灵活性。
随着AI技术的不断发展,数据管理的需求也在不断增长和变化。MyScaleDB团队将继续致力于提供最先进的解决方案,帮助开发者应对这些挑战。我们期待看到更多创新的AI应用借助MyScaleDB的力量得以实现。
如果您对MyScaleDB感兴趣,欢迎访问GitHub仓库了解更多信息,或加入我们的Discord社区与其他开发者交流讨论。让我们一起探索AI应用开发的无限可能!










