
NeMo-Curator简介
NeMo-Curator是NVIDIA开发的一个开源Python库,专门用于大语言模型(LLM)数据集的快速、可扩展准备和处理。它利用GPU加速和分布式计算技术,大大提高了数据处理的效率。
主要特点包括:
- 利用GPU和分布式计算加速数据处理
- 提供模块化和可定制的数据处理pipeline
- 支持多种数据处理任务,如文本提取、质量过滤、去重等
- 适用于模型预训练、领域自适应预训练、监督微调等多种LLM场景
官方资源
博客文章
NVIDIA开发者博客上有几篇介绍NeMo-Curator的文章:
- Curating Trillion-Token Datasets: Introducing NVIDIA NeMo Data Curator
- Scale and Curate High-Quality Datasets for LLM Training with NVIDIA NeMo Curator
- Curating Custom Datasets for LLM Training with NVIDIA NeMo Curator
- Curating Custom Datasets for LLM Parameter-Efficient Fine-Tuning with NVIDIA NeMo Curator
这些文章深入介绍了NeMo-Curator的使用场景和方法。
安装
NeMo-Curator可以通过以下方式安装:
- 通过PyPI安装:
pip install cython
pip install nemo-curator
- 从源码安装:
git clone https://github.com/NVIDIA/NeMo-Curator.git
cd NeMo-Curator
pip install cython
pip install .
- 使用NVIDIA NGC容器(预装NeMo-Curator)
详细的安装说明可以参考GitHub README。
快速上手
以下代码片段展示了如何创建一个简单的数据处理pipeline:
# 下载数据集
dataset = download_common_crawl("/datasets/common_crawl/", "2021-04", "2021-10", url_limit=10)
# 构建处理pipeline
curation_pipeline = Sequential([
# 修复unicode
Modify(UnicodeReformatter()),
# 过滤短文本
ScoreFilter(WordCountFilter(min_words=80)),
# 过滤低质量文本
ScoreFilter(FastTextQualityFilter(model_path="model.bin")),
# 去除评估数据集中的样本
TaskDecontamination([Winogrande(), Squad(), TriviaQA()])
])
# 执行pipeline
curated_dataset = curation_pipeline(dataset)
更多使用示例可以参考官方教程。
性能表现
NeMo-Curator利用GPU加速可以大幅提升数据处理效率。例如,使用64个NVIDIA A100 GPU,可以在1.8小时内完成1.1万亿token的Red Pajama数据集去重。
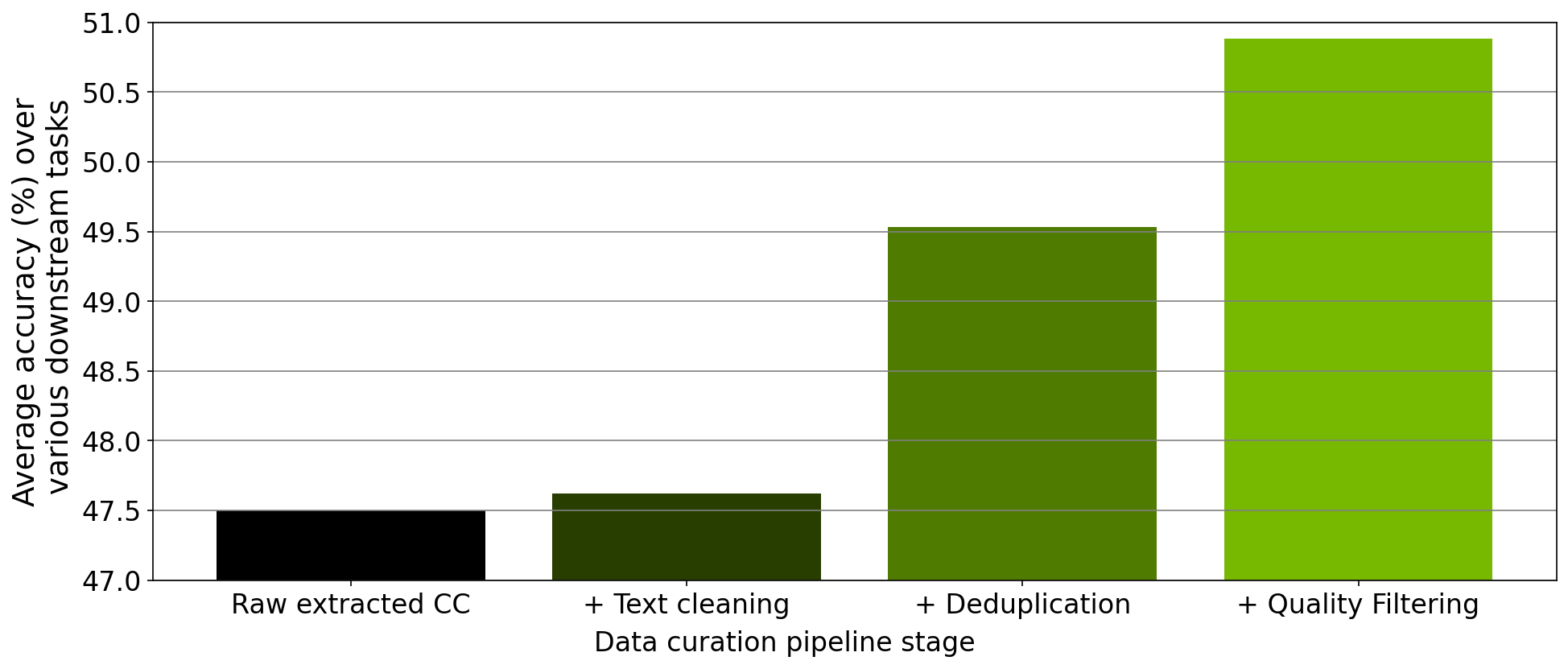
上图展示了使用NeMo-Curator处理的数据对模型zero-shot性能的提升。
总结
NeMo-Curator为LLM数据处理提供了高效的解决方案。通过学习和使用这个工具,可以大大提高数据准备的效率,从而加速LLM的开发和训练过程。欢迎大家尝试使用并为项目贡献代码!










