
nlp-hanzi-similar:为汉字相似度计算开辟新途径
在自然语言处理(NLP)领域,汉字相似度计算一直是一个具有挑战性的课题。与拉丁文字不同,汉字具有独特的结构和书写特点,这使得传统的字符串相似度算法难以应用。为了解决这个问题,GitHub用户houbb开发了一个名为nlp-hanzi-similar的开源工具,为汉字相似度计算开辟了新的途径。
项目背景与意义
nlp-hanzi-similar项目的诞生源于一个真实的需求。一位从事语言认知科学研究的学者在阅读了作者之前发表的一篇关于中文形近字相似度计算的文章后,希望能够获得相关的源代码和资料。然而,作者发现国内外在这方面的开源工具和文献都十分匮乏。这促使他决定将自己之前的算法整理成开源项目,以填补这一领域的空白。
这个项目的重要性不言而喻。在中文信息处理中,汉字相似度计算有着广泛的应用前景,例如:
- 手写汉字识别与纠错
- 文本混淆生成
- 模糊搜索优化
- 文字游戏开发
- 语言学习辅助工具
通过提供一个基础的、可扩展的相似度计算框架,nlp-hanzi-similar为进一步的研究和应用奠定了基础。
核心特性与实现原理
nlp-hanzi-similar采用了多维度的分析方法来计算汉字相似度,主要包括以下几个方面:
- 四角编码:利用汉字笔画特征进行编码比较
- 拼音:考虑发音的相似性
- 汉字结构:分析汉字的整体结构特征
- 偏旁部首:比较汉字的构件相似性
- 笔画数:考虑书写复杂度的差异
- 拆字:将汉字拆解为更小的组成部分进行比较
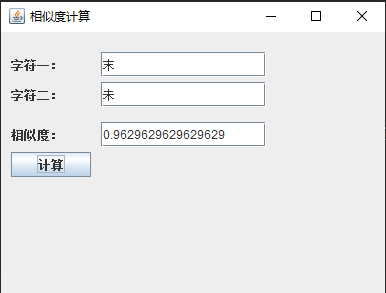
这种多角度的分析方法使得相似度计算更加全面和准确。例如,在比较"末"和"未"这两个字时,系统会综合考虑它们在各个维度上的相似程度,得出一个综合的相似度分数。
灵活的配置与扩展性
nlp-hanzi-similar的一大特色是其高度的可配置性和扩展性。用户可以根据自己的需求调整各个维度的权重,甚至可以添加新的相似度计算维度。这种灵活性使得该工具能够适应不同的应用场景和研究需求。
例如,用户可以通过以下代码自定义权重:
double rate = HanziSimilarBs.newInstance()
.jiegouRate(10)
.sijiaoRate(8)
.bushouRate(6)
.bihuashuRate(2)
.pinyinRate(1)
.chaiziRate(8)
.init()
.similar('末', '未');
此外,项目还支持用户自定义相似度数据,这对于处理特殊字符或领域特定的相似度计算非常有用。
多语言支持与快速体验
考虑到NLP社区中Python使用者众多,作者还提供了一个Python版本的简化实现。这不仅方便了Python用户的使用,也为其他编程语言的移植提供了参考。
为了让更多人能够快速体验这个工具,作者还提供了一个可执行文件版本。用户只需下载并解压,就能通过一个简单的图形界面来测试汉字相似度计算功能。
开源社区与未来展望
nlp-hanzi-similar采用开源模式发展,这为项目的持续改进和创新提供了可能。作者鼓励社区成员通过fork和star来支持项目,同时也欢迎贡献代码和提出改进建议。
展望未来,项目计划在以下几个方面继续努力:
- 丰富相似度计算策略
- 优化默认权重设置
- 改进用户界面
- 扩展到更多编程语言
此外,作者还计划引入拆字字典,以更细致地比较汉字的组成部分,进一步提高相似度计算的精确度。
结语
nlp-hanzi-similar项目为中文NLP领域提供了一个创新的工具,填补了汉字相似度计算这一重要但长期被忽视的领域的空白。通过开源的方式,它不仅为研究者和开发者提供了宝贵的资源,也为汉字信息处理技术的发展注入了新的动力。
随着项目的不断完善和社区的积极参与,我们有理由相信,nlp-hanzi-similar将在中文自然语言处理、文字识别、语言学习等多个领域发挥越来越重要的作用,为中文信息化和数字人文研究做出重要贡献。









