
NVIDIA Transformer Engine简介
NVIDIA Transformer Engine (TE) 是NVIDIA公司推出的一个专门用于加速Transformer模型的库。随着Transformer模型在自然语言处理、计算机视觉等领域的广泛应用,如何高效训练和部署这些大规模模型成为了一个重要挑战。Transformer Engine正是为了解决这一问题而生,它通过一系列优化技术,特别是支持8位浮点(FP8)精度,大大提升了模型的训练和推理性能。
Transformer Engine的主要特性
-
支持多种精度:除了常见的FP32、FP16和BF16外,Transformer Engine还支持FP8精度,这在Hopper和Ada架构的GPU上尤其有效。
-
自动混合精度:提供类似自动混合精度的API,使用户能够轻松集成到现有的框架特定代码中。
-
高度优化的核心组件:包含了构建Transformer层的高度优化模块。
-
跨框架支持:提供了一个框架无关的C++ API,可以与其他深度学习库集成,实现FP8支持。
-
性能提升:通过使用FP8精度和其他优化,可以显著提高训练和推理速度,同时降低内存使用。
Transformer Engine的工作原理
Transformer Engine的核心思想是通过降低计算精度来提高性能,同时保持模型的准确性。这主要通过以下几个方面实现:
-
FP8精度支持:FP8是一种新的浮点格式,相比FP16和BF16,它能进一步减少内存带宽和存储需求,同时在许多情况下不会显著影响模型精度。
-
动态缩放:Transformer Engine内部维护缩放因子和其他必要的值,以确保FP8训练的稳定性和准确性。
-
融合内核:提供针对Transformer模型优化的融合操作,减少内存访问和kernel启动开销。
-
自动混合精度:类似于PyTorch的autocast,TE提供了fp8_autocast上下文管理器,允许用户轻松控制何时使用FP8精度。
使用Transformer Engine
安装
Transformer Engine可以通过多种方式安装:
- 使用Docker镜像:
docker run --gpus all -it --rm nvcr.io/nvidia/pytorch:23.10-py3
2. 通过pip安装:
pip install git+https://github.com/NVIDIA/TransformerEngine.git@stable
3. 从源代码编译安装(适用于高级用户)
### 基本使用示例
以下是一个使用PyTorch的简单示例:
```python
import torch
import transformer_engine.pytorch as te
from transformer_engine.common import recipe
# 设置维度
in_features = 768
out_features = 3072
hidden_size = 2048
# 初始化模型和输入
model = te.Linear(in_features, out_features, bias=True)
inp = torch.randn(hidden_size, in_features, device="cuda")
# 创建FP8 recipe
fp8_recipe = recipe.DelayedScaling(margin=0, fp8_format=recipe.Format.E4M3)
# 启用FP8自动转换
with te.fp8_autocast(enabled=True, fp8_recipe=fp8_recipe):
out = model(inp)
loss = out.sum()
loss.backward()
这个例子展示了如何使用Transformer Engine的Linear层和FP8自动转换功能。
Transformer Engine的性能优势
Transformer Engine在多个方面带来了显著的性能提升:
-
训练速度:通过使用FP8精度,可以减少内存带宽需求,从而加快训练速度。
-
内存使用:FP8格式可以显著降低模型参数和激活值的存储需求,使得在有限的GPU内存中训练更大的模型成为可能。
-
推理性能:FP8同样可以提高推理速度,特别是在需要低延迟的场景中。
-
大规模模型支持:通过降低精度和优化的内存使用,Transformer Engine使得训练和部署更大规模的Transformer模型变得更加可行。
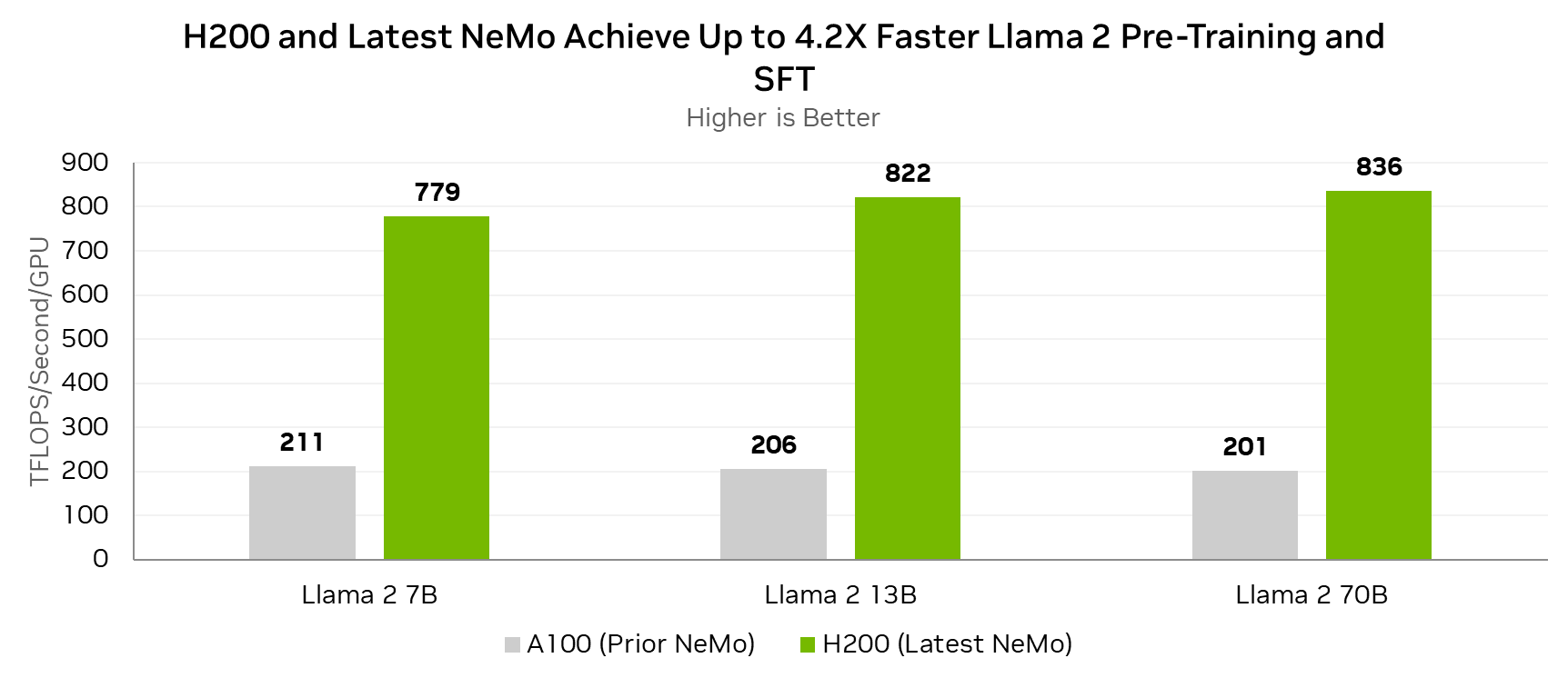
上图展示了使用NVIDIA H200 GPU和Transformer Engine在不同规模的模型上的性能提升。
Transformer Engine的应用场景
Transformer Engine在多个领域和框架中得到了广泛应用:
-
大语言模型(LLM):如GPT、T5、BERT等模型的训练和推理。
-
计算机视觉:在vision transformer等模型中的应用。
-
多模态模型:结合文本和图像的大规模模型训练。
-
高性能计算:在需要极致性能的科学计算和AI研究中的应用。
与其他框架的集成
Transformer Engine已经与多个流行的深度学习框架和工具集成:
- DeepSpeed
- Hugging Face Accelerate
- Lightning
- MosaicML Composer
- NVIDIA JAX Toolbox
- NVIDIA Megatron-LM
- NVIDIA NeMo Framework
- Amazon SageMaker Model Parallel Library
这些集成使得开发者可以在自己熟悉的环境中轻松使用Transformer Engine的功能。
FP8训练的收敛性
一个常见的担忧是使用低精度(如FP8)是否会影响模型的收敛性和最终精度。NVIDIA进行了广泛的测试,结果表明FP8训练与BF16训练的损失曲线没有显著差异。以下是一些经过验证的模型:
- T5-770M (JAX/T5x)
- MPT-1.3B (Mosaic Composer)
- GPT-5B (JAX/Paxml和NeMo Framework)
- LLama2-7B (Alibaba Pai)
- T5-11B (JAX/T5x)
- MPT-13B (Mosaic Composer)
- GPT-22B (NeMo Framework)
- LLama2-70B (Alibaba Pai)
- GPT-175B (JAX/Paxml)
这些结果表明,Transformer Engine不仅提供了性能优势,还保持了模型训练的稳定性和准确性。
Transformer Engine的未来发展
随着AI模型规模的不断增长和应用场景的扩展,Transformer Engine的重要性也在不断提升。未来,我们可以期待以下几个方面的发展:
-
更广泛的硬件支持:除了当前支持的Hopper和Ada架构,未来可能会扩展到更多的GPU架构。
-
更深入的框架集成:与更多深度学习框架的原生集成,提供更无缝的用户体验。
-
更多的优化技术:除了FP8,可能会引入更多的精度和内存优化技术。
-
对新兴AI模型的支持:随着AI模型架构的演进,Transformer Engine也将不断适应新的模型结构和计算需求。
结论
NVIDIA Transformer Engine作为一个专门针对Transformer模型优化的库,在提高训练和推理性能方面发挥了重要作用。通过支持FP8精度、提供优化的核心组件和易用的API,它使得开发者能够更高效地训练和部署大规模AI模型。随着AI技术的不断发展,Transformer Engine将继续在推动AI模型规模化和性能优化方面发挥关键作用。
对于那些正在处理大规模Transformer模型的研究人员和工程师来说,Transformer Engine无疑是一个值得关注和使用的工具。它不仅能够提高训练效率,还能够降低硬件成本,为AI的进一步发展铺平道路。随着更多的优化和功能的加入,我们可以期待Transformer Engine在未来为AI领域带来更多的突破和创新。









