
OpenCLIP简介
OpenCLIP是OpenAI CLIP(Contrastive Language-Image Pre-training)模型的开源实现。CLIP是一种强大的视觉-语言预训练模型,可以通过自然语言描述来理解图像内容。OpenCLIP项目旨在提供CLIP的开源复现,并在此基础上进行改进和扩展。
OpenCLIP的主要特点包括:
-
提供多种预训练模型,包括在LAION-400M、LAION-2B等大规模数据集上训练的模型。
-
支持多种模型架构,如ViT、ResNet等。
-
实现了CLIP的训练和评估代码,支持分布式训练。
-
提供了详细的使用文档和示例代码。
-
支持在自定义数据集上进行微调。
-
实现了一些CLIP的改进版本,如CoCa等。
OpenCLIP为研究人员和开发者提供了一个灵活的CLIP实现,可以用于各种视觉-语言任务。
模型性能
OpenCLIP训练了多个模型,在ImageNet零样本分类任务上取得了优秀的性能。以下是部分模型的性能对比:
| 模型 | 训练数据 | 分辨率 | 样本数 | ImageNet零样本准确率 |
|---|---|---|---|---|
| ConvNext-XXLarge | LAION-2B | 256px | 34B | 79.5% |
| ViT-L/14 | DataComp-1B | 224px | 13B | 79.2% |
| ViT-G/14 | LAION-2B | 224px | 34B | 80.1% |
| ViT-L/14 (原始CLIP) | WIT | 224px | 13B | 75.5% |
可以看到,OpenCLIP训练的模型性能已经超过了原始CLIP模型。
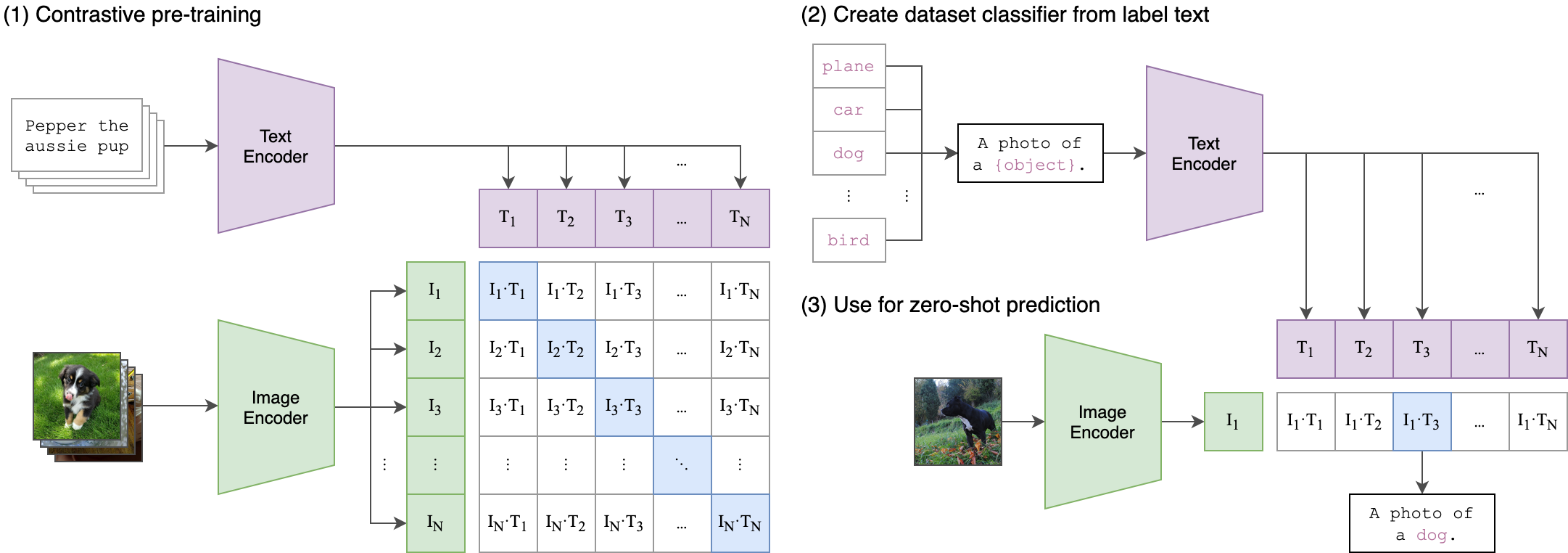
使用方法
安装
可以通过pip安装OpenCLIP:
pip install open_clip_torch
加载预训练模型
使用以下代码可以加载预训练模型:
import open_clip
model, _, preprocess = open_clip.create_model_and_transforms('ViT-B-32', pretrained='laion2b_s34b_b79k')
tokenizer = open_clip.get_tokenizer('ViT-B-32')
图像-文本相似度计算
import torch
from PIL import Image
image = preprocess(Image.open("image.jpg")).unsqueeze(0)
text = tokenizer(["a diagram", "a dog", "a cat"])
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs)
这段代码展示了如何使用OpenCLIP计算图像和文本之间的相似度。
训练技巧
OpenCLIP提供了丰富的训练选项和技巧,以下是一些重要的训练技巧:
-
多GPU训练:支持使用torchrun进行多GPU分布式训练。
-
梯度累积:使用
--accum-freq参数可以模拟更大的batch size。 -
混合精度训练:使用
--precision amp启用混合精度训练。 -
数据并行:支持使用多个数据源进行训练,可以通过
::分隔不同的数据路径。 -
Patch Dropout:可以通过设置
patch_dropout参数来提高训练速度。 -
模型蒸馏:支持从预训练模型进行知识蒸馏。
-
Int8量化:支持Int8训练和推理,可以提高训练速度。
-
远程训练:支持从S3等远程存储加载和保存模型。
CoCa模型
OpenCLIP还实现了CoCa(Contrastive Captioners)模型,这是CLIP的一个改进版本。CoCa在CLIP的基础上增加了一个生成式解码器,可以同时进行对比学习和图像描述生成。
使用CoCa生成图像描述的示例代码:
import open_clip
import torch
from PIL import Image
model, _, transform = open_clip.create_model_and_transforms(
model_name="coca_ViT-L-14",
pretrained="mscoco_finetuned_laion2B-s13B-b90k"
)
im = Image.open("cat.jpg").convert("RGB")
im = transform(im).unsqueeze(0)
with torch.no_grad():
generated = model.generate(im)
print(open_clip.decode(generated[0]).split("<end_of_text>")[0].replace("<start_of_text>",











