OpenPrompt简介
OpenPrompt是一个开源的提示学习(Prompt-learning)框架,旨在为自然语言处理(NLP)任务提供标准、灵活和可扩展的工具。它允许研究人员和开发者轻松地将预训练语言模型(PLMs)应用于下游NLP任务,通过修改输入文本和使用文本模板来实现。
主要特性
OpenPrompt具有以下主要特性:
- 支持多种预训练语言模型,如BERT、RoBERTa、GPT等
- 提供灵活的模板(Template)和词语器(Verbalizer)定义方式
- 实现了多种提示学习方法,包括手动提示、自动提示等
- 支持分类、生成等多种NLP任务
- 提供了丰富的教程和示例代码
安装使用
可以通过pip安装OpenPrompt:
pip install openprompt
或者从源码安装:
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py install
快速上手
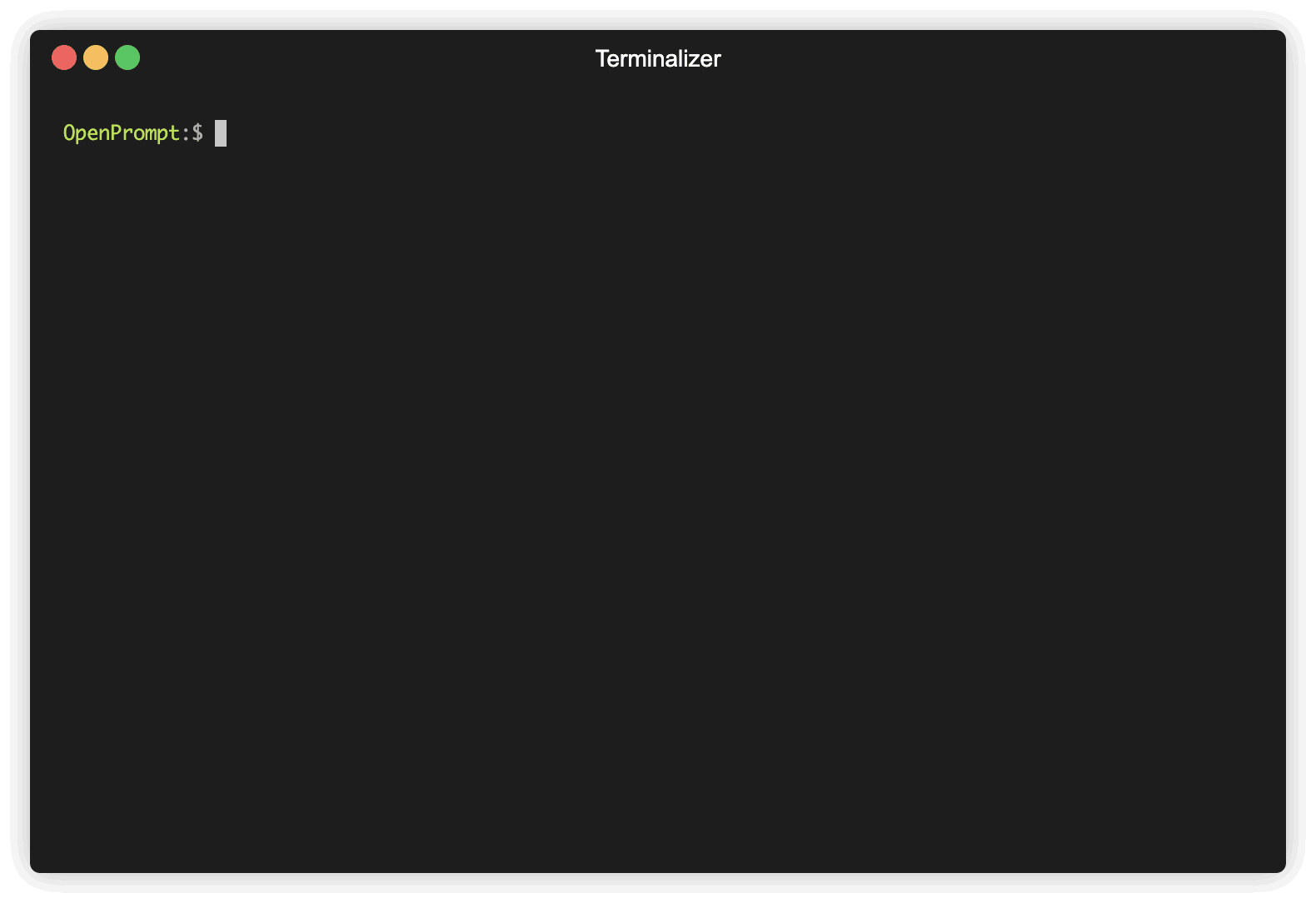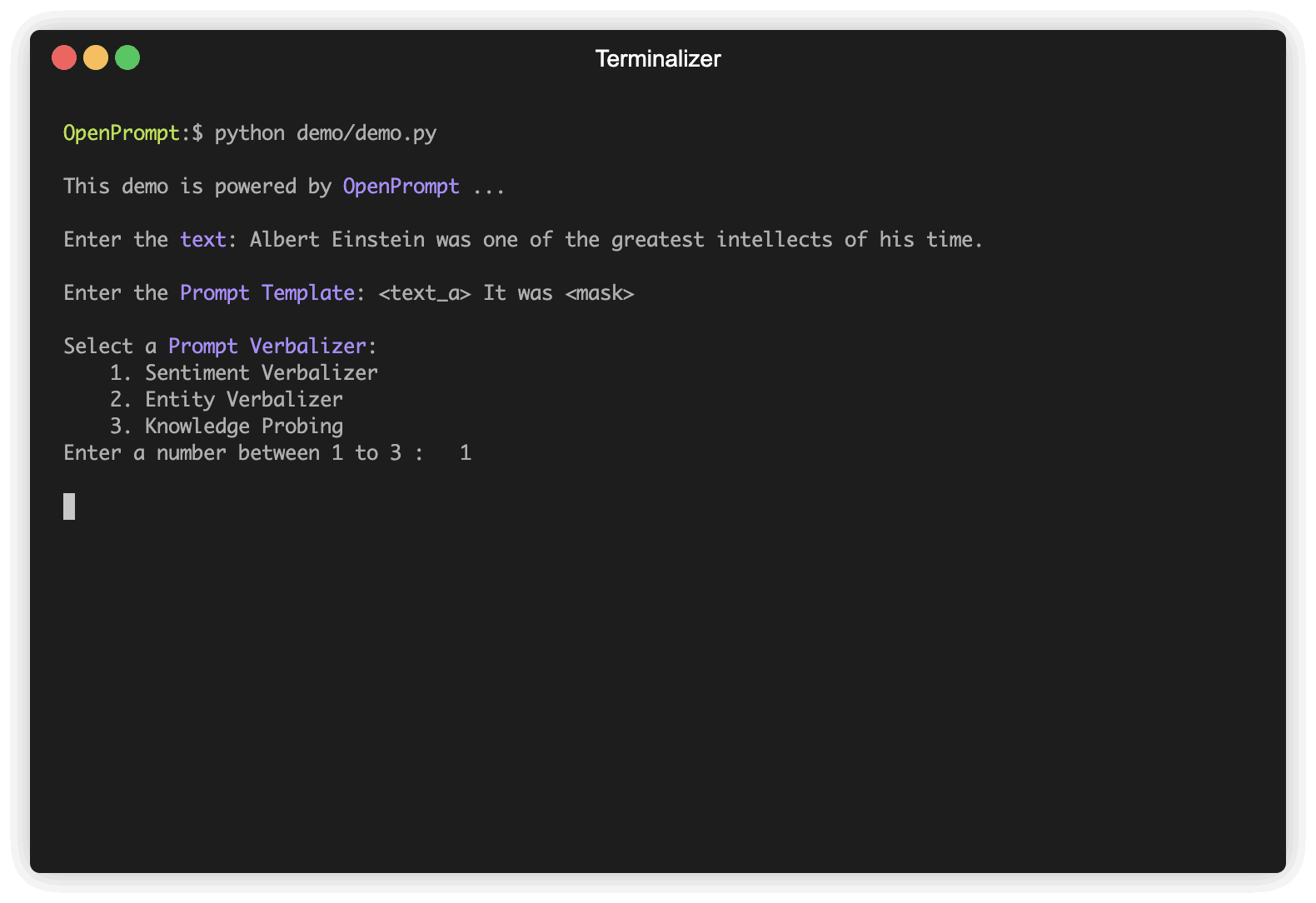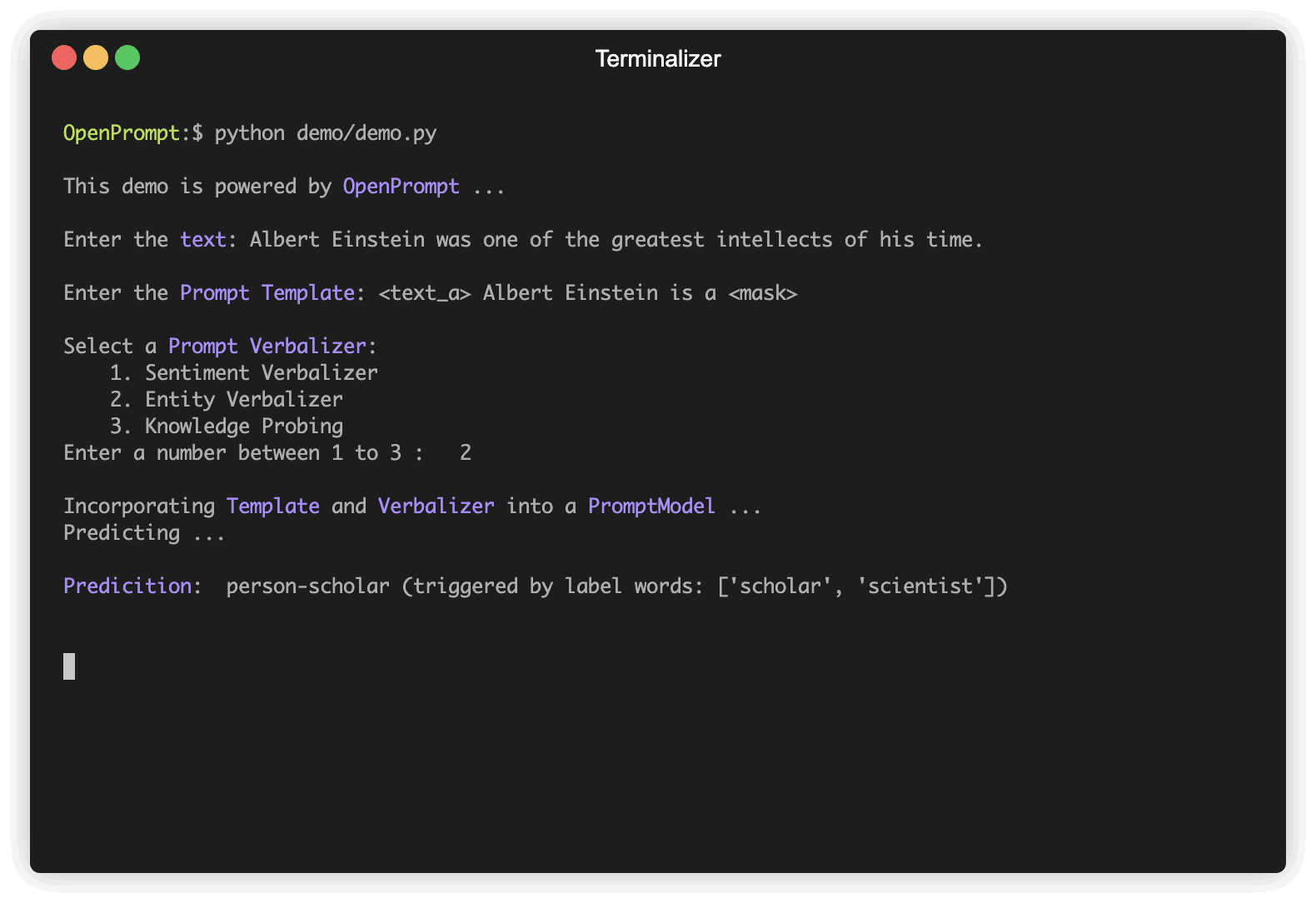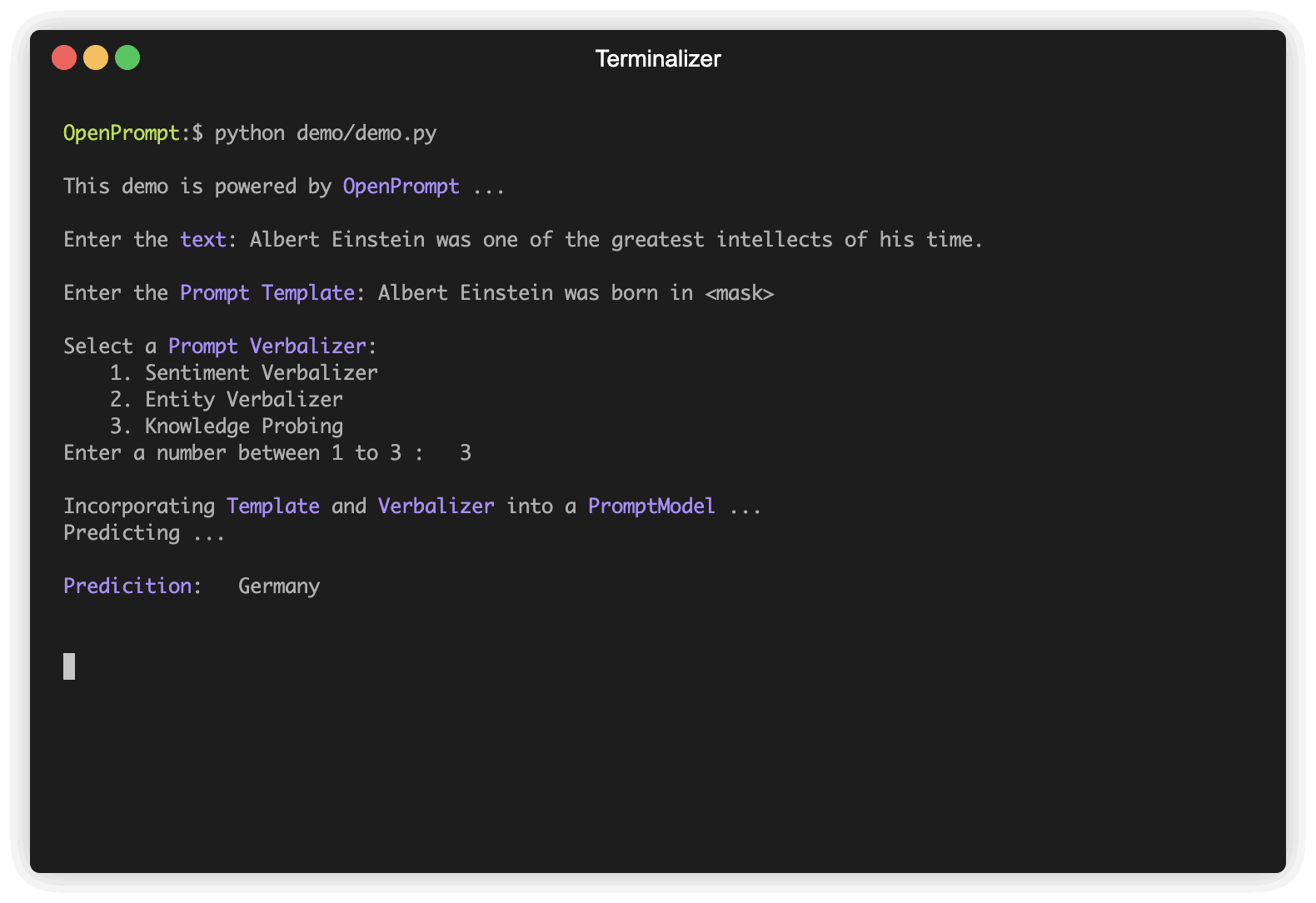
以下是一个使用OpenPrompt进行情感分析的简单示例:
from openprompt.data_utils import InputExample
from openprompt.plms import load_plm
from openprompt.prompts import ManualTemplate, ManualVerbalizer
from openprompt import PromptForClassification, PromptDataLoader
# 1. 加载PLM
plm, tokenizer, model_config, WrapperClass = load_plm("bert", "bert-base-cased")
# 2. 定义数据集
dataset = [
InputExample(text_a="I love this movie.", label=1),
InputExample(text_a="This is a terrible film.", label=0)
]
# 3. 定义模板
template = ManualTemplate(
text = '{"placeholder":"text_a"} It was {"mask"}',
tokenizer = tokenizer,
)
# 4. 定义词语器
verbalizer = ManualVerbalizer(
classes = ["negative", "positive"],
label_words = {
"negative": ["bad"],
"positive": ["good", "great", "wonderful"],
},
tokenizer = tokenizer,
)
# 5. 构建PromptModel
prompt_model = PromptForClassification(
template = template,
plm = plm,
verbalizer = verbalizer,
)
# 6. 定义数据加载器
data_loader = PromptDataLoader(
dataset = dataset,
tokenizer = tokenizer,
template = template,
tokenizer_wrapper_class=WrapperClass,
)
# 7. 训练和推理
prompt_model.eval()
for batch in data_loader:
logits = prompt_model(batch)
preds = torch.argmax(logits, dim = -1)
print(preds)
学习资源
-
官方文档: OpenPrompt Documentation
-
GitHub仓库: thunlp/OpenPrompt
-
教程示例: OpenPrompt Tutorials
-
论文: OpenPrompt: An Open-source Framework for Prompt-learning
-
API参考: OpenPrompt API Reference
-
常见问题: OpenPrompt FAQ
总结
OpenPrompt为NLP研究人员和开发者提供了一个强大而灵活的工具,可以快速实现和测试各种提示学习方法。通过学习和使用OpenPrompt,你可以更好地理解和应用提示学习范式,为你的NLP项目带来新的可能性。无论你是刚接触提示学习的新手,还是希望在此基础上进行深入研究的专家,OpenPrompt都是一个值得深入探索的优秀框架。













