
paperetl:让医学和科学论文数据处理变得简单
在当今数据驱动的科研环境中,高效处理和分析大量学术文献数据变得越来越重要。paperetl应运而生,它是一个专门为医学和科学论文设计的ETL(提取、转换、加载)库,旨在简化文献数据的处理流程,为研究人员和数据科学家提供强大的支持。
paperetl的核心功能
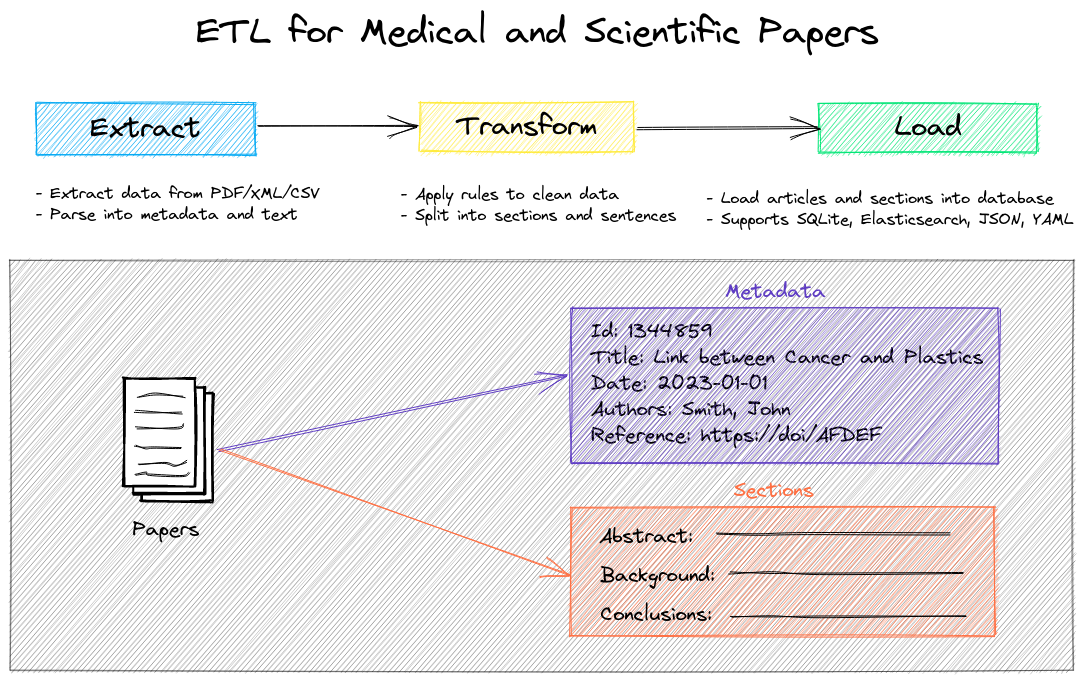
paperetl的主要功能是将各种格式的医学和科学论文转换成结构化的数据,以便于后续的分析和研究。它支持多种输入源,包括:
- PDF文件
- XML文件(支持arXiv、PubMed和TEI格式)
- CSV文件
- COVID-19研究数据集(CORD-19) 同时,paperetl还提供了多种输出选项,可以将处理后的数据存储为:
- SQLite数据库
- Elasticsearch索引
- JSON文件
- YAML文件
这种灵活的输入输出支持,使得paperetl能够适应各种不同的研究需求和数据处理场景。
安装和使用
paperetl的安装非常简单,支持Python 3.8及以上版本。推荐使用Python虚拟环境进行安装:
pip install paperetl
如果想要使用最新的开发版本,也可以直接从GitHub安装:
pip install git+https://github.com/neuml/paperetl
需要注意的是,如果要处理PDF文件,需要额外安装和配置GROBID服务。GROBID是一个强大的文献解析工具,能够从PDF中提取结构化信息。
实际应用示例
下面通过几个具体的例子来展示paperetl的强大功能:
- 将文章加载到SQLite数据库:
python -m paperetl.file paperetl/data paperetl/models
这个命令会将paperetl/data目录下的所有文章处理后存入paperetl/models/articles.sqlite数据库中。
2. 将文章加载到Elasticsearch:
python -m paperetl.file paperetl/data http://localhost:9200
这个命令会将处理后的文章数据存入本地运行的Elasticsearch实例中。 3. 将文章转换为JSON或YAML格式:
python -m paperetl.file paperetl/data json://paperetl/json
python -m paperetl.file paperetl/data yaml://paperetl/yaml
这两个命令分别将文章转换为JSON和YAML格式,并存储在指定目录中。 4. 处理CORD-19数据集:
scripts/getcord19.sh cord19/data
python -m paperetl.cord19.entry cord19/data
python -m paperetl.cord19 cord19/data cord19/models
这组命令演示了如何下载、处理CORD-19数据集,并将其存入SQLite数据库。
paperetl的优势
- 多样化的输入支持: paperetl能够处理多种常见的文献格式,特别是对PDF的支持,大大简化了文献数据的获取过程。
- 灵活的输出选项: 用户可以根据自己的需求选择最适合的输出格式,无论是需要关系型数据库、全文搜索引擎,还是简单的文件存储。
- 专注于医学和科学文献: paperetl针对医学和科学文献的特点进行了优化,能够更准确地提取和结构化相关信息。
- 可扩展性: 作为一个开源项目,paperetl允许用户根据自己的需求进行定制和扩展。
- 与其他工具的集成: paperetl可以轻松地集成到现有的数据处理流程中,为更复杂的分析任务提供基础数据支持。
性能和效率
paperetl在处理大规模文献数据时表现出色。以CORD-19数据集为例,它能够高效地处理数十万篇文献,将其转换为结构化的数据格式。这种高效率源于paperetl的优化设计和对并行处理的支持。
社区支持和持续发展
作为一个活跃的开源项目,paperetl拥有一个不断增长的用户社区。项目在GitHub上持续更新,定期发布新版本,修复bug并添加新功能。用户可以通过GitHub Issues提出问题或建议,参与到项目的改进中来。
未来展望
随着人工智能和机器学习在科研领域的广泛应用,paperetl也在不断探索如何更好地支持这些新兴技术。未来,我们可能会看到paperetl集成更多的自然语言处理功能,如自动摘要生成、关键词提取等,进一步提升其在学术研究中的价值。
结语
paperetl为医学和科学文献的数据处理提供了一个强大而灵活的解决方案。无论是个人研究者还是大型研究机构,都能从这个工具中受益,更高效地管理和分析海量的学术文献。随着科研数据量的不断增长,paperetl这样的工具将在推动科学研究和知识发现中发挥越来越重要的作用。 如果你正在寻找一个能够简化文献数据处理流程的工具,不妨尝试一下paperetl。它不仅能够节省你的时间和精力,还能帮助你更好地组织和利用宝贵的研究资料。让我们一起拥抱数据驱动的科研时代,用技术的力量推动学术进步! 🚀📚 访问paperetl GitHub仓库









