
PARL简介
PARL(PaddlePaddle Reinforcement Learning)是由百度开源的一个高性能分布式强化学习框架。它旨在为强化学习研究和应用提供灵活、高效的开发工具,帮助用户快速实现和优化各种强化学习算法。

核心特性
PARL具有以下几个突出特点:
-
可复现性强: PARL提供了多种经典强化学习算法的稳定实现,能够可靠地复现出这些算法的效果。这对于研究人员验证和比较不同算法非常有帮助。
-
大规模并行: 支持使用数千个CPU和多GPU进行高性能的并行训练,可以显著加速大规模强化学习任务的训练过程。
-
易于复用: 框架中的算法实现可以通过定义一个前向网络,直接适配到新的任务中,训练机制会自动构建。这大大提高了算法的复用效率。
-
易于扩展: 用户可以通过继承框架中的抽象类,快速构建新的算法。这种设计使得PARL具有很好的扩展性。
核心抽象
PARL引入了三个核心抽象概念来构建强化学习智能体:
-
Model: 用于构建策略网络或价值网络等前向网络,定义了给定状态输入后的网络结构。
-
Algorithm: 描述了如何更新Model中的参数,通常包含至少一个模型。
-
Agent: 作为环境和算法之间的数据桥梁,负责与外部环境交互,并在将数据输入训练过程前进行预处理。
这种抽象设计使得PARL能够灵活地支持各种强化学习算法的实现。
并行化能力
PARL提供了简洁的分布式训练API,只需添加一个装饰器,就可以将代码转换为并行版本。例如:
@parl.remote_class
class Agent(object):
def say_hello(self):
print("Hello World!")
def sum(self, a, b):
return a+b
parl.connect('localhost:8037')
agent = Agent()
agent.say_hello()
ans = agent.sum(1,5) # 在远程执行,不消耗本地计算资源
通过这种方式,用户可以轻松地利用外部计算资源,实现大规模并行训练。PARL的并行化设计如下图所示:
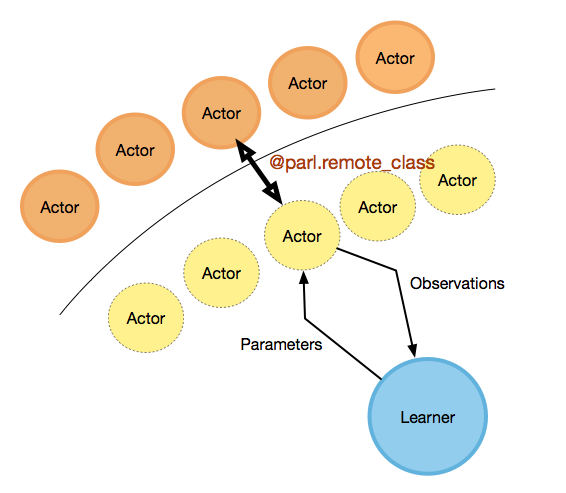
真实的Actor(橙色圆圈)在CPU集群上运行,而Learner(蓝色圆圈)在本地GPU上运行,同时还有几个远程Actor(黄色虚线圆圈)。对于用户来说,他们可以像编写多线程代码一样简单地编写代码,但Actor实际上是消耗远程资源的。
安装与使用
安装依赖
PARL需要Python 3.6+环境(推荐Python 3.8+以获得更好的分布式训练支持)。如果需要使用与PaddlePaddle相关的功能,还需要安装paddlepaddle>=2.3.1。
快速入门
PARL提供了丰富的教程和示例来帮助用户快速上手:
对于强化学习初学者,PARL还提供了入门课程,包括视频教程和配套代码。
算法示例
PARL实现了多种经典和前沿的强化学习算法,包括:
这些算法实现不仅可以作为学习参考,也可以直接应用于实际问题中。
实际应用案例
PARL在多个国际强化学习竞赛中取得了优异成绩,展示了其在复杂任务中的实际应用能力:
- NIPS 2018 AI for Prosthetics Challenge 冠军解决方案
- NIPS 2019 Learn to Move Challenge 冠军解决方案
- NIPS 2020 Learning to Run a Power Network Challenge 冠军解决方案
这些成功案例证明了PARL在处理高度复杂的强化学习任务时的有效性和可靠性。
总结
PARL作为一个高性能的分布式强化学习框架,为研究人员和开发者提供了强大的工具支持。它的核心优势包括:
- 提供可靠的算法实现,保证实验结果的可复现性
- 支持大规模并行训练,显著提升训练效率
- 灵活的抽象设计,便于算法的快速实现和扩展
- 丰富的示例和文档,降低学习门槛
无论是强化学习研究还是实际应用开发,PARL都是一个值得考虑的优秀框架选择。随着PARL的不断发展和完善,相信它将为强化学习领域的进步做出更大的贡献。
🔗 更多信息请访问PARL GitHub仓库和官方文档。









