
PatrickStar: 开启AI大模型训练的新纪元
在人工智能和自然语言处理(NLP)领域,预训练模型(PTM)已成为研究和应用的热点。然而,训练这些庞大的模型需要巨大的硬件资源,这使得只有少数人能够参与其中。现在,腾讯开源的PatrickStar框架正在改变这一现状,让更多人能够接触和训练大规模语言模型。
突破内存瓶颈,实现更大规模模型训练
PatrickStar的核心优势在于其创新的内存管理方案。传统的模型训练常常面临显存不足的问题,而PatrickStar通过异构训练技术,充分利用了CPU和GPU的内存资源。这种方法不仅解决了内存不足的困扰,还显著提高了训练效率。

PatrickStar采用了动态内存调度策略,配合基于块的内存管理模块,能够灵活地将模型数据在CPU和GPU之间进行调度。这种设计使得PatrickStar可以在有限的GPU资源下训练更大规模的模型,为研究人员和开发者提供了前所未有的可能性。
卓越的性能表现
在实际测试中,PatrickStar展现出了令人瞩目的性能。以下是一些关键的性能指标:
- 在8块Tesla V100 GPU和240GB GPU内存的环境下,PatrickStar v0.4.3能够训练180亿参数的模型。
- 在相同规模的模型训练中,PatrickStar的性能优于DeepSpeed。
- 在单节点A100 SuperPod上,PatrickStar v0.4.3可以训练680亿参数的模型,是DeepSpeed v0.5.7的6倍以上。
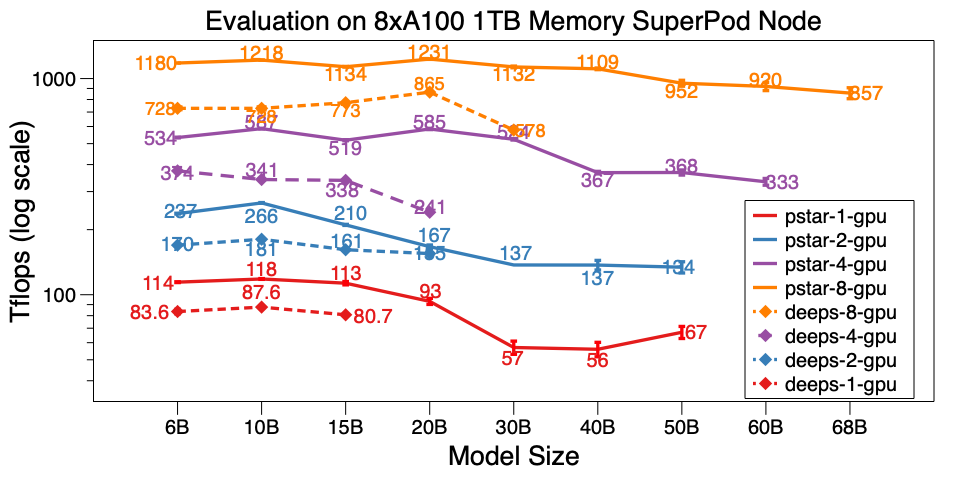
更令人振奋的是,PatrickStar在多机扩展性方面也取得了突破性进展。研究团队成功地在32个GPU上训练了GPT3-175B模型,这是首次在如此小规模的GPU集群上运行如此大规模的模型。这一成就大大降低了训练和微调超大规模模型的门槛,为AI研究和应用开辟了新的可能性。
易用性和灵活性
PatrickStar不仅性能卓越,还注重用户体验。它基于PyTorch构建,使得现有的PyTorch项目可以轻松迁移。框架提供了简洁的API,使用户能够快速上手并定制自己的训练流程。
以下是一个简单的使用示例:
from patrickstar.runtime import initialize_engine
config = {
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.001,
"betas": (0.9, 0.999),
"eps": 1e-6,
"weight_decay": 0,
"use_hybrid_adam": True,
},
},
"fp16": {
"enabled": True,
"loss_scale": 0,
"initial_scale_power": 2 ** 3,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1,
},
"default_chunk_size": 64 * 1024 * 1024,
"release_after_init": True,
"use_cpu_embedding": False,
"client": {
"mem_tracer": {
"use_async_mem_monitor": True,
}
},
}
def model_func():
return MyModel(...)
model, optimizer = initialize_engine(model_func=model_func, local_rank=0, config=config)
# 训练循环
for data in dataloader:
optimizer.zero_grad()
loss = model(data)
model.backward(loss)
optimizer.step()
这个示例展示了如何使用PatrickStar初始化模型和优化器,并进行基本的训练循环。框架的配置选项丰富,可以根据具体需求进行调整,以获得最佳性能。
广泛的应用前景
PatrickStar的出现为NLP领域带来了新的机遇。它不仅可以用于训练通用的大规模语言模型,还可以应用于各种特定领域的模型训练。例如,研究团队已经使用PatrickStar成功训练了CLUE-GPT2模型,展现了框架在中文NLP任务中的潜力。
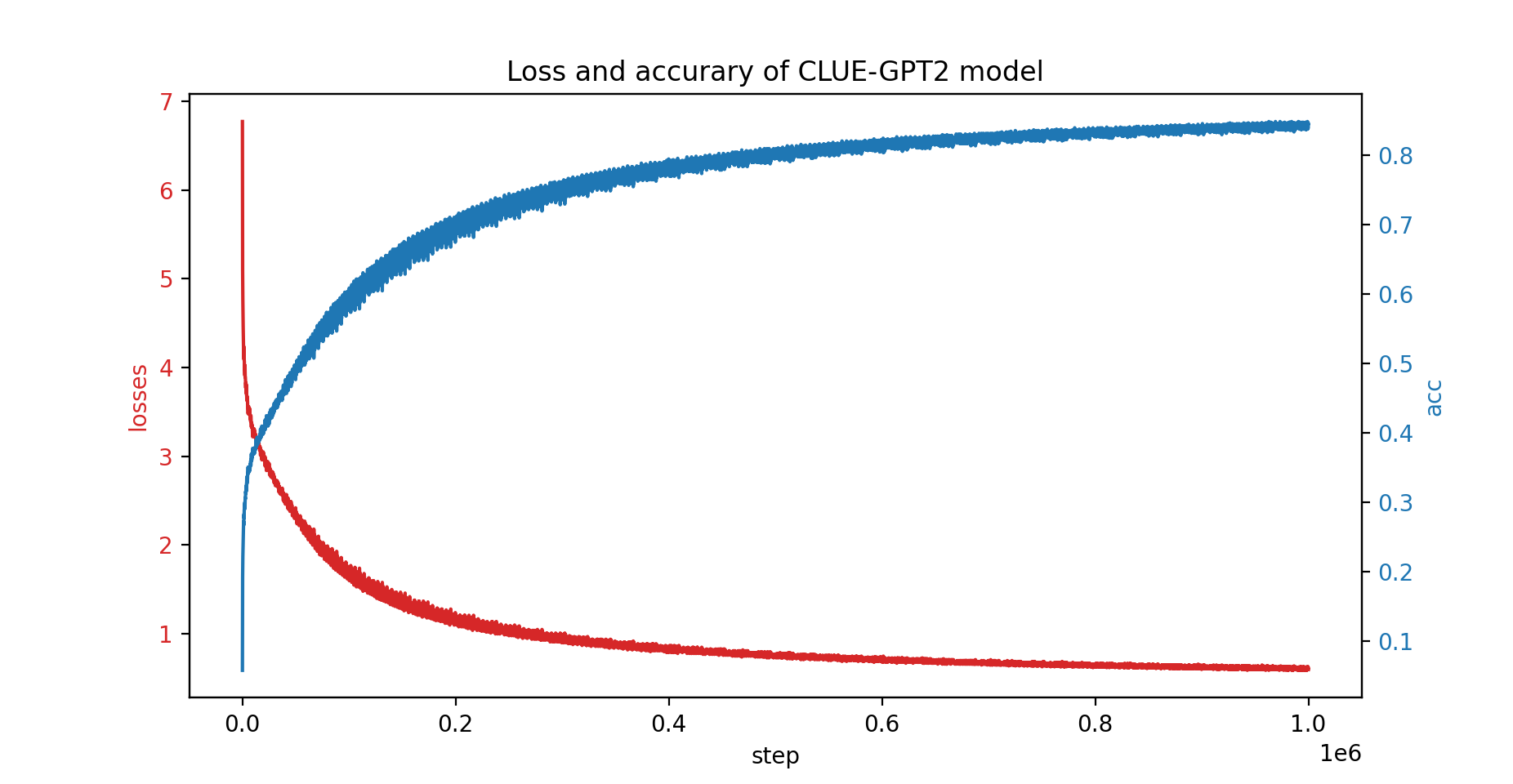
这个成功案例表明,PatrickStar不仅适用于英语模型,也能很好地支持其他语言的模型训练,为多语言NLP研究提供了强大工具。
开源社区和持续发展
PatrickStar采用BSD 3-Clause许可证开源,欢迎社区贡献。项目在GitHub上持续更新,研究团队定期发布新版本,不断优化性能和功能。感兴趣的开发者和研究者可以通过以下链接了解更多信息:
结语
PatrickStar的出现无疑是NLP领域的一个重要里程碑。它不仅突破了大规模模型训练的硬件限制,还通过优秀的性能和易用性,为更多研究者和开发者提供了接触和探索大规模AI模型的机会。随着PatrickStar的不断发展和完善,我们有理由相信,它将在推动NLP技术民主化和加速AI创新方面发挥越来越重要的作用。
无论你是正在进行尖端NLP研究的学者,还是希望在实际应用中部署大规模语言模型的工程师,PatrickStar都为你提供了一个强大而灵活的工具。让我们共同期待PatrickStar带来的更多可能性,一起推动NLP技术的边界!
🚀💡🌟 PatrickStar正在重塑AI大模型训练的未来,你准备好加入这场革命了吗?










