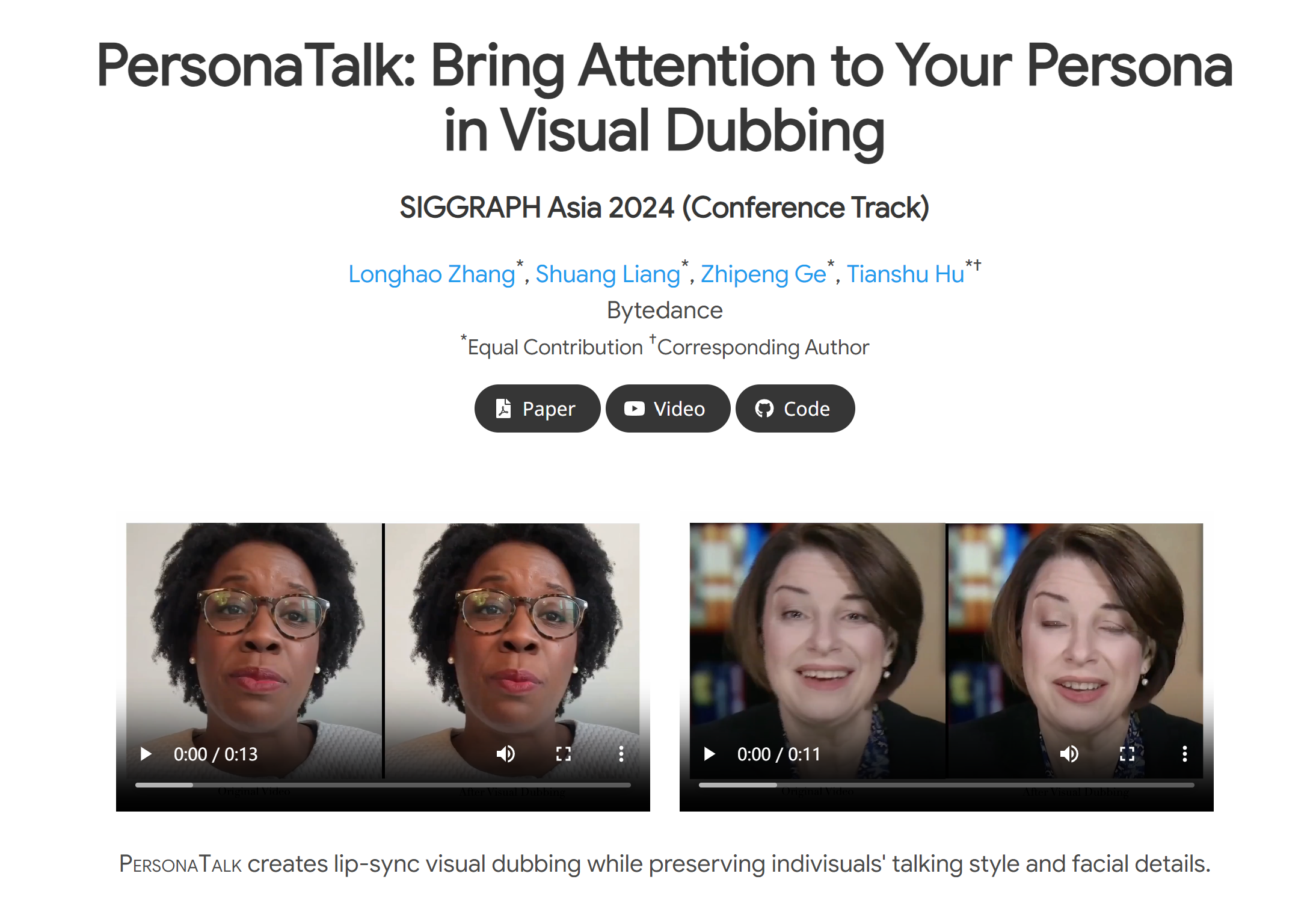
PersonaTalk是字节跳动搞出来的一个技术框架,专门用来给视频里的人物做AI配音的。就像给视频里的角色穿上声音的衣服,让他们说出我们想要的话,而且嘴巴的动作和声音还能完美匹配,保持角色的个性特征,比如他们独特的说话风格和面部细节。
技术大招:PersonaTalk的核心能力
声音同步嘴型:让视频中的人物嘴巴动作与新语音的口型完全匹配。
保留人物特点:在生成新视频时,保留人物原本的说话方式、脸型、表情等细节。
主要功能:PersonaTalk的特色
音频驱动的个性化视觉配音:根据输入的音频和参考视频生成同步的视觉配音,保留说话者的个性特点。
风格感知的唇形同步:在生成唇部动作时,将说话者的独特说话风格加入音频特征中。
双重注意力面部渲染:通过“双重注意力”机制,分别处理唇部和面部的纹理,确保每个细节都能真实呈现。
多样化和一致性生成:根据不同的参考帧动态选择合适的画面,保证视频中的说话者动作一致性,同时展现多样性。
无需个性化微调的通用框架:可以在不同说话者之间直接应用,不需要额外的个性化调整。
应用场景:PersonaTalk的舞台
视频翻译:将视频内容翻译成不同语言并同步口型。
虚拟教师:创建虚拟教师进行课程讲解。
AIGC创作:用于生成高质量的数字人视频和口播内容。
娱乐和广告:在娱乐和广告行业中实现个性化和互动式用户体验。
总的来说,PersonaTalk就像是视频界的变声器,但不仅仅是变声,还能变脸,让视频里的人物说出我们想要的话,同时保持他们的个性和风格。这项技术未来肯定能在视频制作、教育、娱乐等领域大放异彩!









