
Petals:开启AI民主化的新纪元
在人工智能技术飞速发展的今天,大型语言模型(LLM)无疑是最令人瞩目的突破之一。然而,运行这些模型所需的硬件资源往往令普通用户望而却步。Petals项目应运而生,它采用创新的分布式方法,让任何人都能在家庭设备上运行和微调大型语言模型,开启了AI民主化的新纪元。
Petals的创新之处
Petals的核心理念是将大型语言模型分解成小块,并将这些块分布存储在全球各地的普通计算机上。这种方法类似于BitTorrent文件共享系统,但用于AI模型的运行。通过这种分布式架构,Petals实现了以下突破:
-
硬件门槛大幅降低:即使是消费级GPU或Google Colab的免费版本也能参与运行最先进的AI模型。
-
快速响应:单批次推理速度可达到6个token/秒(Llama 2 70B模型)或4个token/秒(Falcon 180B模型),足以支持聊天机器人等交互式应用。
-
灵活性:用户可以像使用PyTorch和Hugging Face Transformers库一样灵活地操作模型,进行微调、自定义采样等高级操作。
-
开放性:Petals支持多种开源大模型,如LLaMA、BLOOM、Falcon等,为研究人员和开发者提供了广阔的实验平台。
-
可扩展性:网络中的参与者越多,整体性能就越强大,形成良性循环。
Petals的工作原理
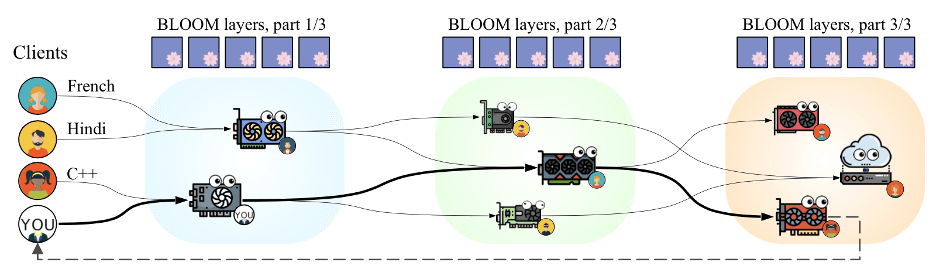
Petals的运作机制可以概括为以下几个步骤:
-
模型分割:大型语言模型被分割成多个"块"(layers)。
-
分布式存储:这些块被分散存储在网络中的不同服务器(普通用户的设备)上。
-
动态路由:当用户发送请求时,系统会构建一个最优的服务器链,以最小化总体前向传递时间。
-
容错机制:系统会存储中间激活值,以应对可能的服务器断开情况。
-
适配器插入:用户可以在模型层之间插入特定任务的适配器,实现轻量级微调。
这种分布式方法不仅降低了硬件要求,还提高了整体系统的可靠性和效率。
Petals的实际应用
Petals为AI爱好者、研究人员和开发者提供了前所未有的机会。以下是一些Petals的典型应用场景:
-
聊天机器人开发:利用Petals提供的WebSocket API,开发者可以轻松创建响应迅速的聊天机器人。
-
模型微调:研究人员可以在不改变预训练模型的情况下,通过插入适配器来进行特定任务的微调。
-
零样本学习:开发者可以使用Petals来探索大型语言模型在零样本学习任务中的表现。
-
文本生成:作家和内容创作者可以利用Petals来辅助创作,生成长篇文章或故事。
-
AI教育:教育工作者可以利用Petals为学生提供实践机会,让他们亲身体验最先进的AI技术。
Petals的性能评估
Petals团队进行了详细的性能测试,将其与常见的模型加载方法进行比较。结果显示,Petals在交互式场景下表现出色,延迟比传统的卸载方法低3-25倍。
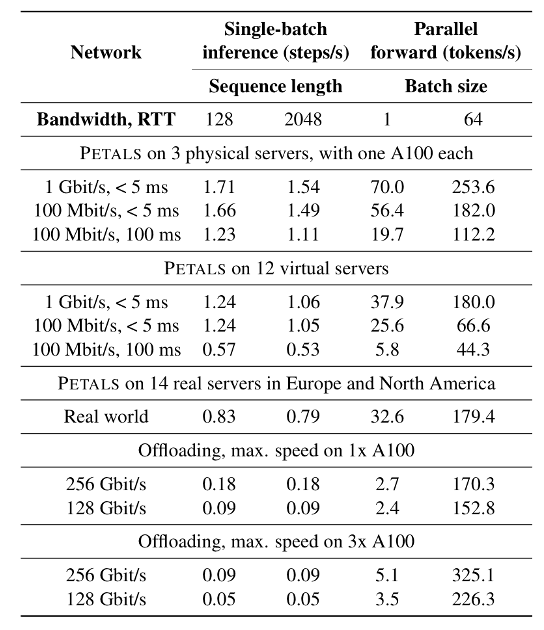
这意味着使用Petals进行推理(有时甚至是微调)的速度要快得多,尽管我们使用的是分布式模型而不是本地模型。
Petals的未来展望
Petals的出现标志着AI技术正在向更加开放、民主的方向发展。随着项目的不断完善和社区的壮大,我们可以期待以下发展:
-
更多模型支持:未来可能会支持更多种类的大型语言模型,甚至是多模态模型。
-
性能提升:随着参与者增多和算法优化,系统的整体性能有望进一步提升。
-
应用生态系统:围绕Petals可能会形成丰富的应用生态系统,涵盖各种AI应用场景。
-
区块链集成:未来可能会引入基于区块链的激励机制,鼓励更多用户贡献计算资源。
-
硬件无关的AI:Petals有潜力实现真正的硬件无关AI,让任何设备都能参与AI的进步。
结语
Petals项目代表了AI技术发展的一个重要方向 - 去中心化和民主化。它不仅让普通用户能够接触到最先进的AI技术,还为AI研究和应用开辟了新的可能性。随着项目的不断发展和完善,我们有理由相信,Petals将在推动AI技术的普及和创新方面发挥越来越重要的作用。
无论你是AI研究人员、开发者,还是对AI技术感兴趣的普通用户,Petals都为你提供了一个绝佳的机会,让你能够亲身参与到AI技术的最前沿。让我们一起期待Petals带来的AI民主化革命,共同探索人工智能的无限可能!









