PFLlib:开启个性化联邦学习研究新篇章
联邦学习作为一种保护隐私的分布式机器学习范式,近年来受到了学术界和工业界的广泛关注。然而,由于数据分布的异构性,传统联邦学习方法往往难以在所有客户端上取得理想的性能。为了解决这一问题,个性化联邦学习(Personalized Federated Learning, PFL)应运而生。PFLlib正是一个专注于个性化联邦学习的开源算法库,旨在为研究人员提供一个便捷的实验平台。
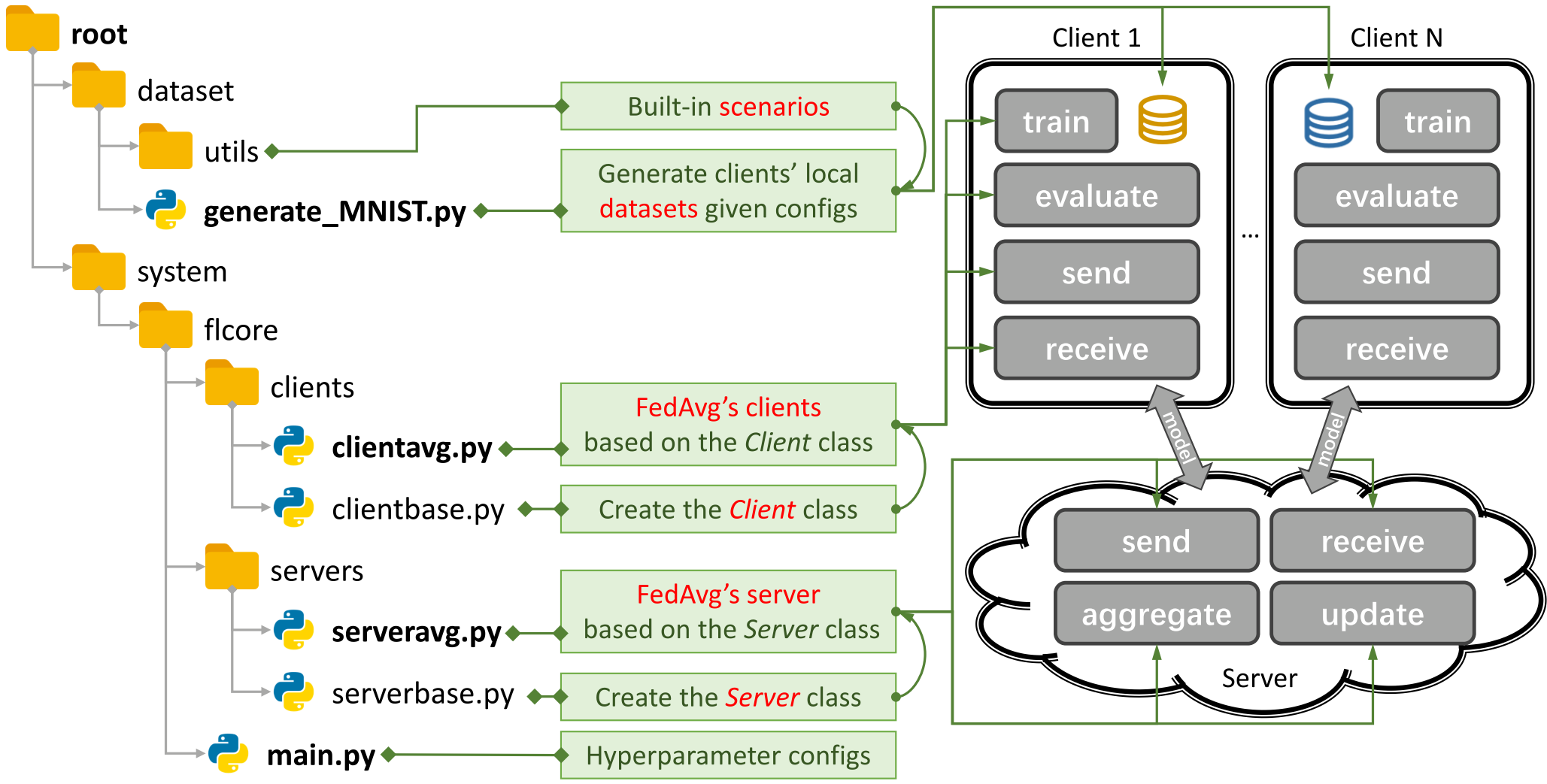
丰富多样的算法支持
PFLlib目前包含37种联邦学习算法,涵盖了传统联邦学习(tFL)和个性化联邦学习(pFL)两大类:
- 传统联邦学习算法:包括FedAvg、SCAFFOLD、FedProx等经典方法。
- 个性化联邦学习算法:包括FedPer、LG-FedAvg、FedRep等前沿算法。
这些算法涉及多种技术路线,如基于正则化、模型分割、知识蒸馏等,为研究人员提供了丰富的比较基准。
多样化的实验场景
PFLlib支持3种典型的联邦学习实验场景:
- 标签偏移(Label Skew):模拟客户端之间类别分布不均衡的情况。
- 特征偏移(Feature Shift):模拟客户端之间特征分布存在差异的情况。
- 真实世界/物联网(IoT)场景:使用自然分割的数据集,更贴近实际应用。
这些场景覆盖了联邦学习中常见的数据异构性问题,有助于全面评估算法性能。
丰富的数据集支持
PFLlib内置了20个广泛使用的数据集,包括:
- 图像分类:MNIST、CIFAR-10/100、Tiny-ImageNet等
- 文本分类:AG News、Sogou News等
- 领域适应:Amazon Review、Digit5、DomainNet等
- 物联网:Omniglot、HAR、PAMAP2等
这些数据集涵盖了不同规模、不同领域的任务,能够满足多样化的实验需求。
易用性和可扩展性
PFLlib的设计注重易用性和可扩展性:
- 提供了详细的使用指南,新手可以快速上手。
- 支持灵活的参数配置,可以模拟客户端掉线、通信延迟等实际情况。
- 代码结构清晰,便于添加新的算法、数据集和模型。
研究人员可以基于PFLlib轻松构建自己的实验平台,专注于算法创新而无需过多关注底层实现细节。
性能与效率
得益于优化的实现,PFLlib在资源利用方面表现出色:
- 可在单张NVIDIA GeForce RTX 3090 GPU上模拟500个客户端的场景
- 仅需5.08GB GPU内存即可运行4层CNN在Cifar100数据集上的实验
这种高效的资源利用使得研究人员能够在有限的硬件条件下进行大规模实验。
未来展望
PFLlib作为一个活跃维护的开源项目,将持续跟进联邦学习领域的最新进展:
- 添加更多前沿算法和数据集
- 优化系统性能,支持更大规模的实验
- 完善文档和教程,降低使用门槛
- 鼓励社区贡献,打造开放共享的研究生态
我们期待PFLlib能够成为推动个性化联邦学习研究的重要工具,为解决实际应用中的数据隐私和性能问题贡献力量。
联邦学习作为一种新兴的机器学习范式,正在快速发展并不断拓展应用领域。PFLlib的出现为研究人员提供了一个强大而灵活的实验平台,有望加速这一领域的创新步伐。无论您是联邦学习领域的新手,还是经验丰富的研究者,PFLlib都能为您的研究工作提供有力支持。让我们携手推动个性化联邦学习的发展,共同探索人工智能的美好未来!









