
Pix2Text: 强大的图像文本识别与转换工具
在这个信息时代,将图像中的内容转换为可编辑的文本格式已经成为一个日益重要的需求。Pix2Text (P2T) 应运而生,它是一款功能强大的开源Python工具,旨在成为 Mathpix 的免费替代品。P2T 不仅能够识别图像中的文本,还可以处理复杂的版面布局、表格和数学公式,并将所有这些内容无缝地整合到 Markdown 格式中。让我们深入了解这个令人兴奋的项目。
主要功能与特点
Pix2Text 的核心功能包括:
- 版面分析:能够识别和处理复杂的页面布局。
- 表格识别:可以准确地识别和转换表格结构。
- 文本识别:支持80多种语言的文字识别。
- 数学公式识别:可以将图像中的数学公式转换为 LaTeX 格式。
- PDF 转换:支持将整个 PDF 文件(包括扫描图像)转换为 Markdown 格式。
这些功能使 Pix2Text 成为一个全面的图像文本处理解决方案。
技术架构
Pix2Text 集成了多个先进的模型来实现其强大的功能:
- 版面分析模型: breezedeus/pix2text-layout
- 表格识别模型: breezedeus/pix2text-table-rec
- 文本识别引擎: 使用 CnOCR 处理英文和简体中文,使用 EasyOCR 处理其他语言
- 数学公式检测模型 (MFD): breezedeus/pix2text-mfd
- 数学公式识别模型 (MFR): breezedeus/pix2text-mfr
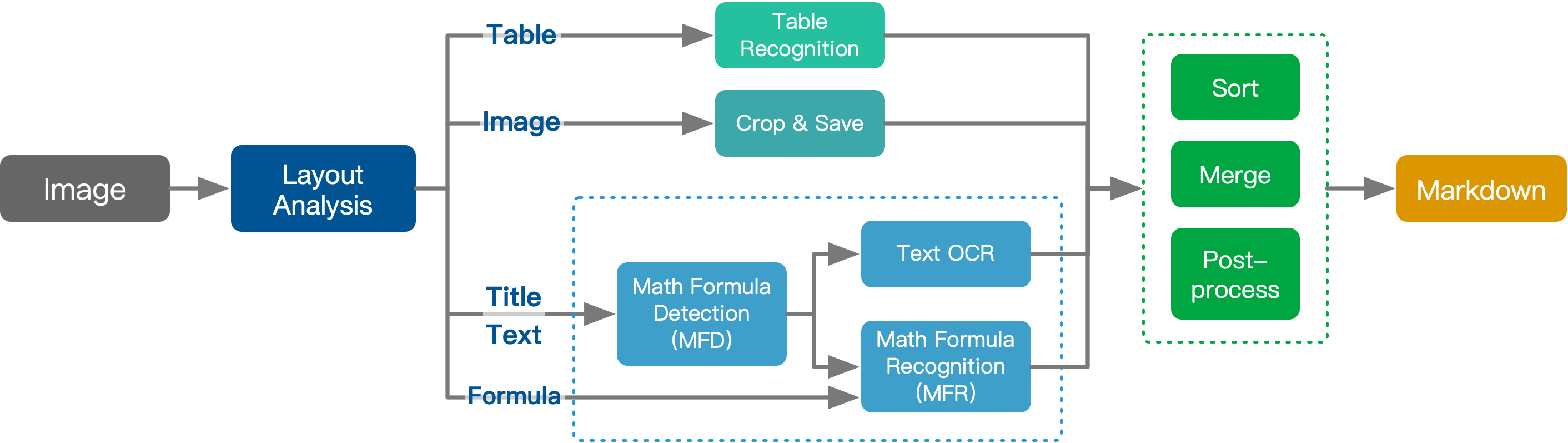
这种模块化的设计使得 Pix2Text 能够灵活地处理各种复杂的图像内容。
语言支持
Pix2Text 的文本识别引擎支持超过80种语言,包括英语、简体中文、繁体中文、越南语等。这种多语言支持使得 Pix2Text 成为一个真正的全球化工具,能够满足不同地区和文化背景用户的需求。
使用方式
尽管 Pix2Text 是一个 Python 工具包,可能对不熟悉 Python 的用户来说不太友好,但开发团队也提供了一个免费的在线服务 P2T Online Web。用户可以直接上传图像并获得解析结果,这大大降低了使用门槛。
对于开发者来说,Pix2Text 的安装和使用非常简单。只需一行命令即可安装:
pip install pix2text
如果需要识别英语和简体中文以外的语言,可以使用以下命令安装额外的包:
pip install pix2text[multilingual]
开源社区与发展
Pix2Text 是一个开源项目,欢迎社区贡献。项目维护者还创建了一个知识星球 "P2T/CnOCR/CnSTD 私密群",用于分享最新的开发进展和研究材料。这种开放的态度不仅促进了项目的快速发展,还为用户提供了及时的支持和交流平台。
最新进展
Pix2Text 持续更新和改进。最新的 V1.1.1 版本(2024年6月18日发布)带来了新的数学公式检测模型,显著提高了公式检测的准确性。而在 V1.1 版本中,添加了版面分析和表格识别模型,支持将复杂布局的图像转换为 Markdown 格式,并增加了对整个 PDF 文件转换为 Markdown 的支持。
应用场景
Pix2Text 的应用场景非常广泛,包括但不限于:
- 学术研究:快速提取和转换学术论文中的文本、公式和表格。
- 文档数字化:将扫描文档转换为可编辑的数字格式。
- 教育领域:教师和学生可以方便地提取和分享教材内容。
- 数据分析:从图像中提取表格数据进行进一步分析。
- 内容创作:作者可以轻松地从图像中提取内容用于写作。
未来展望
随着人工智能和计算机视觉技术的不断进步,Pix2Text 的潜力还远未被完全发掘。未来,我们可以期待:
- 更高的识别准确率
- 支持更多的语言和特殊字符
- 更快的处理速度
- 更智能的版面重构能力
- 与其他工具和平台的深度集成
结语
Pix2Text 代表了图像文本识别和转换领域的一个重要里程碑。作为一个免费、开源的解决方案,它为个人用户和组织提供了强大的工具,帮助他们更有效地处理和利用图像中的信息。随着项目的不断发展和社区的积极参与,Pix2Text 必将在未来发挥更大的作用,推动信息处理和知识共享的进步。
无论您是学生、研究人员、教育工作者还是内容创作者,Pix2Text 都能为您提供valuable的帮助。我们鼓励您尝试使用 Pix2Text,体验它带来的便利,并考虑为这个开源项目做出贡献。让我们共同努力,推动技术的发展,使信息的获取和分享变得更加简单和高效。
如果您觉得 Pix2Text 对您有帮助,不妨考虑为作者买杯咖啡 🥤,支持项目的持续发展。每一份贡献都是对开源精神的支持,也是推动技术进步的动力。让我们一起,为构建一个更加开放、高效的信息世界贡献自己的力量。










