
plotly-resampler: 高效可视化大规模时间序列数据的强大工具
在数据分析和可视化领域,处理和展示大规模时间序列数据一直是一个具有挑战性的问题。随着物联网、金融交易和各种传感器数据的激增,分析师和数据科学家经常需要处理包含数百万甚至数十亿个数据点的时间序列。传统的可视化工具在面对如此庞大的数据集时往往力不从心,导致图表渲染缓慢、交互卡顿,严重影响分析效率和用户体验。为了解决这一问题,plotly-resampler应运而生,为大规模时间序列数据的可视化提供了一个高效而强大的解决方案。
plotly-resampler的核心理念
plotly-resampler是一个基于流行的Plotly可视化库开发的Python工具包,其核心理念是通过动态数据聚合来实现大规模时间序列数据的高效可视化。与传统方法不同,plotly-resampler不会一次性加载和渲染所有数据点,而是根据当前视图动态地对数据进行聚合和重采样。这种方法使得用户可以流畅地浏览和交互超大规模的时间序列数据,而不会感受到明显的性能下降。
主要特性和优势
-
动态数据聚合:plotly-resampler能够根据当前图表视图动态地聚合时间序列数据。这意味着无论用户如何缩放或平移图表,都能看到适当聚合级别的数据,既保证了视觉上的准确性,又确保了交互的流畅性。
-
高度可扩展性:该库能够处理包含数百万甚至上亿个数据点的时间序列,而不会导致浏览器崩溃或性能严重下降。这使得分析师可以轻松处理来自高频传感器、金融交易或物联网设备的大规模数据集。
-
与Plotly无缝集成:plotly-resampler被设计为Plotly库的扩展,因此用户可以继续使用他们熟悉的Plotly API来创建图表,只需添加少量代码就能启用动态重采样功能。
-
多种聚合算法:库提供了多种数据点选择算法,默认使用MinMaxLTTB(Largest-Triangle-Three-Buckets)方法,能在保留数据关键特征的同时大幅减少需要渲染的点数。
-
环境独立性:plotly-resampler可以在多种环境中使用,包括Jupyter Notebook、VSCode、PyCharm、Google Colab等,甚至可以在服务器上作为独立应用程序运行。
工作原理
plotly-resampler的核心工作原理可以概括为以下几个步骤:
-
数据包装:用户首先将原始的Plotly图表对象用plotly-resampler提供的包装器(如FigureResampler或FigureWidgetResampler)进行封装。
-
动态聚合:当用户与图表交互(如缩放或平移)时,包装器会捕获这些事件,并根据当前视图范围动态计算需要显示的数据点。
-
数据选择:使用高效的数据点选择算法(如MinMaxLTTB)从原始数据中选择最具代表性的点,以反映当前视图下的数据特征。
-
渲染更新:选择的数据点被发送到前端进行渲染,更新图表显示,整个过程几乎是实时的,用户感受不到明显的延迟。
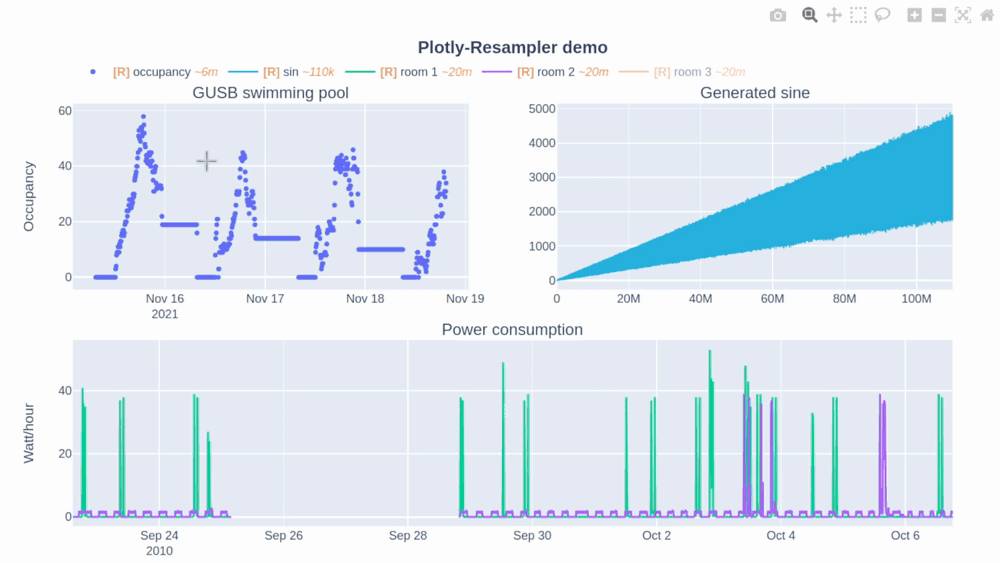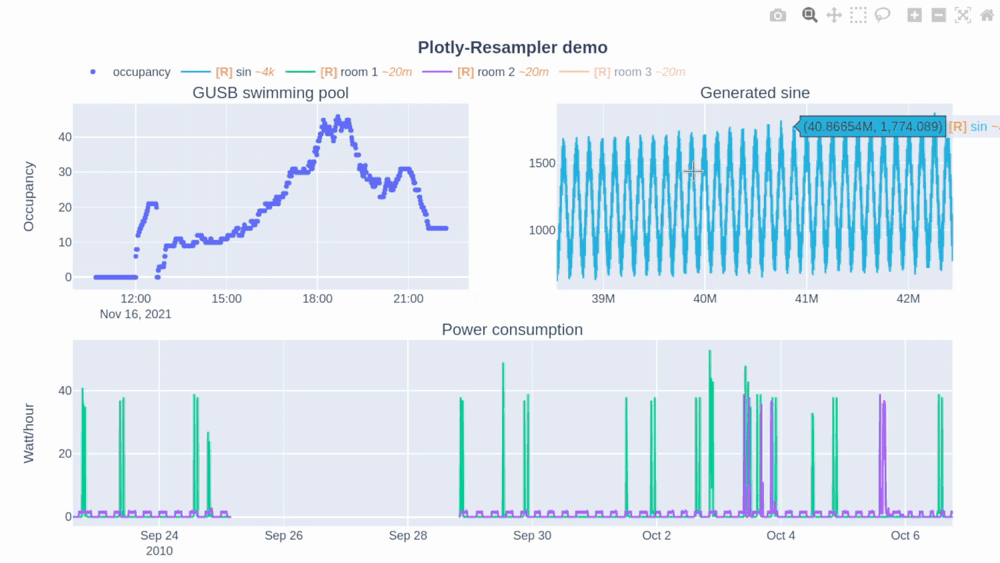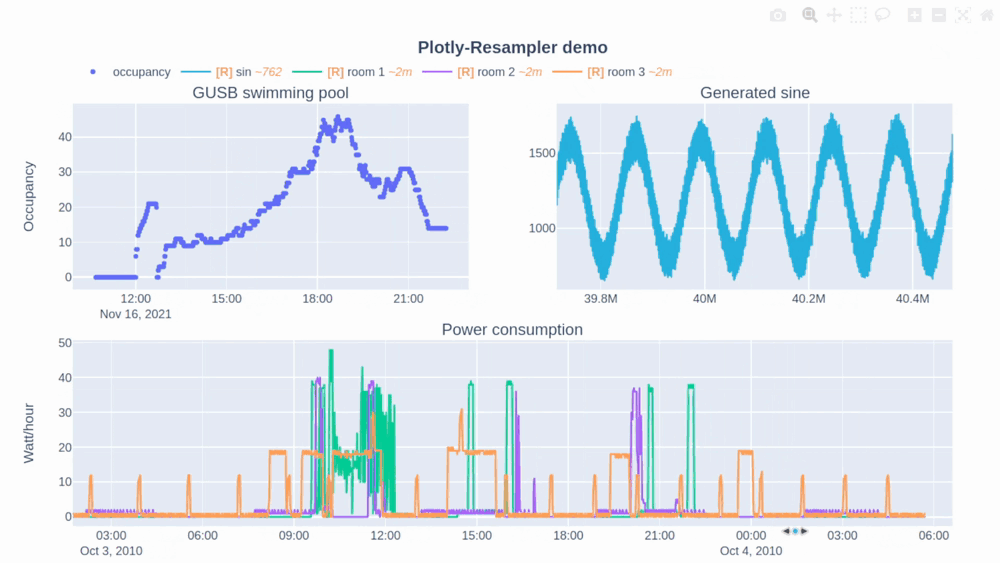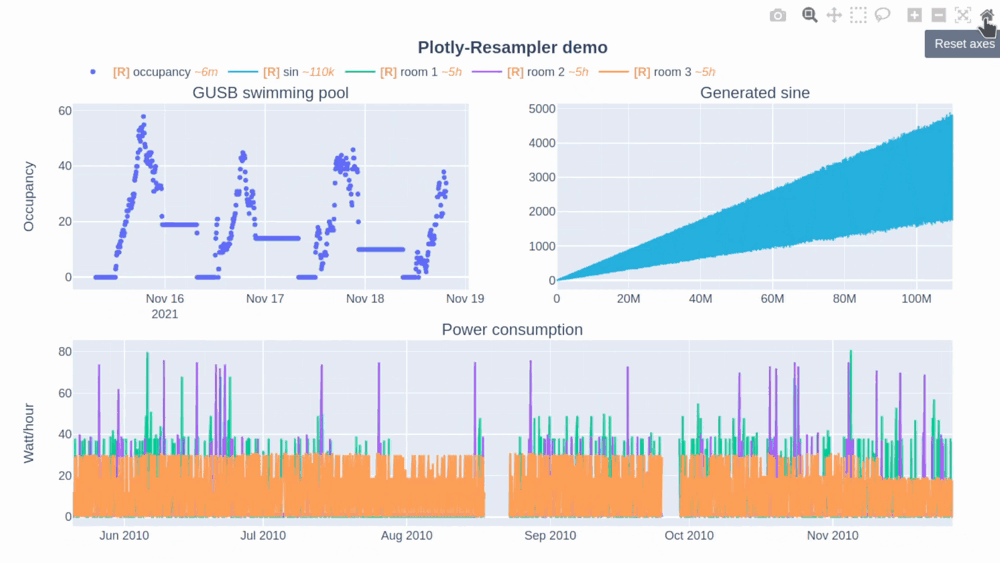
使用方法
使用plotly-resampler非常简单,主要有两种方式:
- 自动模式:使用
register_plotly_resampler函数,这将自动为所有Plotly图表添加动态聚合功能。
import plotly.graph_objects as go
import numpy as np
from plotly_resampler import register_plotly_resampler
# 注册plotly-resampler
register_plotly_resampler(mode='auto')
# 创建大规模时间序列数据
x = np.arange(1_000_000)
noisy_sin = (3 + np.sin(x / 200) + np.random.randn(len(x)) / 10) * x / 1_000
# 创建并显示图表
fig = go.Figure()
fig.add_trace({"y": noisy_sin, "name": "noisy sine"})
fig.show()
- 手动模式:使用
FigureResampler或FigureWidgetResampler包装器,这种方式提供了更多的配置选项。
from plotly_resampler import FigureResampler
# 创建FigureResampler对象
fig = FigureResampler(go.Figure())
fig.add_trace(go.Scattergl(name='noisy sine'), hf_x=x, hf_y=noisy_sin)
# 显示交互式Dash应用
fig.show_dash(mode='inline')
性能优化和注意事项
虽然plotly-resampler大大提高了大规模时间序列数据的可视化性能,但在使用时仍需注意以下几点:
-
初始加载优化:对于特别大的数据集,建议在添加trace时使用
hf_x和hf_y参数,这可以显著加快初始加载速度。 -
降采样效应:使用动态聚合可能会导致一些细微的数据失真,特别是在高度缩小视图时。图例中的"[R]"标记表示该trace正在被重采样。
-
自动缩放行为:plotly-resampler重新定义了双击图表的行为,使其执行"自动缩放"而非"重置坐标轴",这与原生Plotly的行为有所不同。
-
服务器部署注意事项:在服务器上运行时,需要正确转发
FigureResampler.show_dash()方法的端口到本地机器。
未来发展与社区贡献
plotly-resampler作为一个开源项目,欢迎社区贡献。未来的发展方向可能包括:
- 支持更多类型的图表和数据结构
- 进一步优化聚合算法,提高性能和数据表现力
- 增强与其他数据分析和可视化工具的集成
- 改进文档和教程,使更多用户能够轻松上手
对于有兴趣参与项目开发的开发者,可以通过GitHub仓库提交问题、建议或Pull Request。
结论
plotly-resampler为大规模时间序列数据的可视化提供了一个强大而灵活的解决方案。通过巧妙的动态数据聚合和重采样技术,它使得分析师和数据科学家能够轻松处理和探索包含数百万个数据点的时间序列,而不会牺牲交互性能。无论是金融分析、传感器数据监控还是科学研究,plotly-resampler都为处理大规模时间序列数据提供了一个值得信赖的工具。随着数据规模的不断增长,这样的工具将在数据可视化和分析领域扮演越来越重要的角色。
![]()









