PMC-LLaMA: 开源医学语言模型的突破性进展
 Ray
RayPMC-LLaMA: 开源医学语言模型的新纪元
在人工智能迅速发展的今天,大型语言模型(LLM)已经在多个领域展现出惊人的能力。然而,在医疗这样专业性极强、对准确性要求极高的领域,通用型LLM往往力不从心。为了解决这一问题,来自上海交通大学的研究团队开发了PMC-LLaMA,这是一个专门为医学领域设计的开源大型语言模型。🏥💻
创新的训练方法
PMC-LLaMA的训练过程分为两个关键阶段:
-
数据中心知识注入
研究团队使用了大规模的医学文献语料进行预训练,包括480万篇生物医学学术论文和3万本医学教科书。这一阶段让模型获得了丰富的医学专业知识和术语理解能力。 -
医学特定指令微调
研究者创建了一个名为MedC-I的新数据集,包含2.02亿个token,涵盖医学问答对、推理理由和对话。通过在这个数据集上进行微调,PMC-LLaMA学会了如何更准确地回答医学问题并进行专业对话。
优化技术的应用
为了有效处理如此庞大的数据集和模型参数,研究团队采用了多项优化技术:
- AdamW优化器: 结合了Adam优化器的优点和权重衰减,提高了模型的泛化能力。
- 梯度检查点: 通过选择性保存中间激活并在反向传播时重新计算,有效降低了内存占用。
- 全分片数据并行(FSDP): 将模型参数、梯度和优化器状态分布在多个GPU上,实现了并行处理。
- bf16数据格式: 降低了浮点数的精度,在不显著影响准确性的前提下减少了内存使用并提高了计算速度。
这些技术的综合应用使得PMC-LLaMA能够在有限的硬件资源上高效训练,为其他研究者和开发者提供了宝贵的经验。
卓越的性能表现
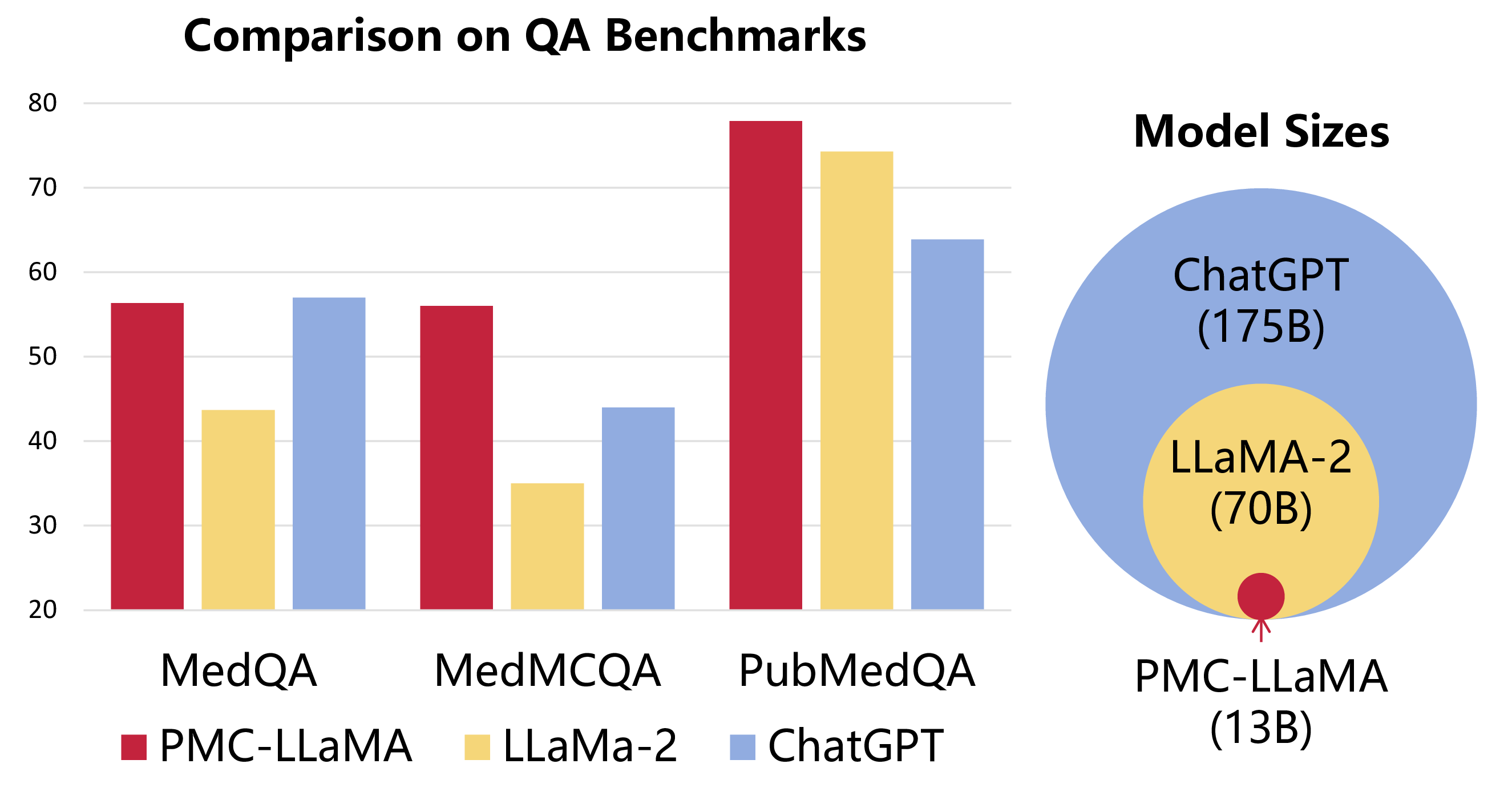
PMC-LLaMA在多个医学问答基准测试中展现出优异的性能:
| 方法 | 模型规模 | USMLE | MedMCQA | PubMedQA |
|---|---|---|---|---|
| 人类(及格线) | - | 50.0 | -- | 60.0 |
| 人类(专家) | - | 87.0 | 90.0 | 78.0 |
| ChatGPT | 175B | 57.0 | 44.7 | 63.9 |
| LLaMA-2 | 13B | 42.73 | 37.41 | 68.0 |
| LLaMA-2 | 70B | 43.68 | 35.02 | 74.3 |
| Med-Alpaca | 13B | 30.85 | 31.13 | 53.2 |
| Chat-Doctor | 7B | 33.93 | 31.10 | 54.3 |
| PMC_LLaMA_13B | 13B | 56.36 | 56.04 | 77.9 |
值得注意的是,PMC-LLaMA_13B在USMLE和MedMCQA测试中甚至超越了拥有175B参数的ChatGPT,这充分证明了领域特定训练的重要性。
零样本学习能力展示
PMC-LLaMA不仅在标准测试中表现出色,在处理领域外的查询时也展现了强大的零样本学习能力。研究团队提供了一系列示例,证明了模型能够理解并回答各种医学相关问题,从常见疾病到复杂的医学概念都能给出准确、专业的解答。

开源精神的践行
PMC-LLaMA项目的一个重要特点是其开源性质。研究团队不仅公开了模型,还分享了详细的训练过程、数据处理方法和评估结果。这种开放态度为整个医疗AI社区带来了巨大价值,使得其他研究者可以:
- 复现研究结果
- 基于PMC-LLaMA进行进一步改进
- 将模型应用于各种医疗场景
项目的GitHub仓库(https://github.com/chaoyi-wu/PMC-LLaMA)提供了详细的使用说明和示例代码,大大降低了其他研究者和开发者的使用门槛。
未来展望
PMC-LLaMA的成功为医疗AI的发展开辟了新的道路。随着模型的不断完善和应用范围的扩大,我们可以期待:
- 更精准的医疗诊断辅助系统
- 智能医学文献检索和总结工具
- 个性化的患者教育和健康管理平台
- 医学研究的加速推进
然而,我们也需要注意到,尽管PMC-LLaMA表现优异,但它仍然是一个辅助工具,不能完全替代医疗专业人员的判断。在实际应用中,应当谨慎使用,并始终将患者安全放在首位。
结语
PMC-LLaMA的出现标志着医疗AI进入了一个新的阶段。它不仅展示了专业领域大型语言模型的潜力,也为开源合作在推动科技进步中的重要作用提供了有力证明。随着更多研究者加入这一领域,我们有理由相信,AI将在改善医疗质量、提高诊断精度和促进医学研究方面发挥越来越重要的作用。🌟🔬
PMC-LLaMA项目为我们展示了一个光明的未来,在这个未来中,先进的AI技术与医学专业知识的结合将为人类健康带来前所未有的进步。让我们共同期待这一令人振奋的发展,并积极参与到这场改变医疗未来的革命中来。💪🌍
编辑推荐精选


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。


TRELLIS
用于可扩展和多功能 3D 生成的结构化 3D 潜在表示
TRELLIS 是一个专注于 3D 生成的项目,它利用结构化 3D 潜在表示技术,实现了可扩展且多功能的 3D 生成。项目提供了多种 3D 生成的方法和工具,包括文本到 3D、图像到 3D 等,并且支持多种输出格式,如 3D 高斯、辐射场和网格等。通过 TRELLIS,用户可以根据文本描述或图像输入快速生成高质量的 3D 资产,适用于游戏开发、动画制作、虚拟现实等多个领域。


ai-agents-for-beginners
10 节课教你开启构建 AI 代理所需的一切知识
AI Agents for Beginners 是一个专为初学者打造的课程项目,提供 10 节课程,涵盖构建 AI 代理的必备知识,支持多种语言,包含规划设计、工具使用、多代理等丰富内容,助您快速入门 AI 代理领域。


AEE
AI Excel全自动制表工具
AEE 在线 AI 全自动 Excel 编辑器,提供智能录入、自动公式、数据整理、图表生成等功能,高效处理 Excel 任务,提升办公效率。支持自动高亮数据、批量计算、不规则数据录入,适用于企业、教育、金融等多场景。


UI-TARS-desktop
基于 UI-TARS 视觉语言模型的桌面应用,可通过自然语言控制计算机进行多模态操作。
UI-TARS-desktop 是一款功能强大的桌面应用,基于 UI-TARS(视觉语言模型)构建。它具备自然语言控制、截图与视觉识别、精确的鼠标键盘控制等功能,支持跨平台使用(Windows/MacOS),能提供实时反馈和状态显示,且数据完全本地处理,保障隐私安全。该应用集成了多种大语言模型和搜索方式,还可进行文件系统操作。适用于需要智能交互和自动化任务的场景,如信息检索、文件管理等。其提供了详细的文档,包括快速启动、部署、贡献指南和 SDK 使用说明等,方便开发者使用和扩展。


Wan2.1
开源且先进的大规模视频生成模型项目
Wan2.1 是一个开源且先进的大规模视频生成模型项目,支持文本到图像、文本到视频、图像到视频等多种生成任务。它具备丰富的配置选项,可调整分辨率、扩散步数等参数,还能对提示词进行增强。使用了多种先进技术和工具,在视频和图像生成领域具有广泛应用前景,适合研究人员和开发者使用。


爱图表
全流程 AI 驱动的数据可视化工具,助力用户轻松创作高颜值图表
爱图表(aitubiao.com)就是AI图表,是由镝数科技推出的一款创新型智能数据可视化平台,专注于为用户提供便捷的图表生成、数据分析和报告撰写服务。爱图表是中国首个在图表场景接入DeepSeek的产品。通过接入前沿的DeepSeek系列AI模型,爱图表结合强大的数据处理能力与智能化功能,致力于帮助职场人士高效处理和表达数据,提升工作效率和报告质量。


Qwen2.5-VL
一款强大的视觉语言模型,支持图像和视频输入
Qwen2.5-VL 是一款强大的视觉语言模型,支持图像和视频输入,可用于多种场景,如商品特点总结、图像文字识别等。项目提供了 OpenAI API 服务、Web UI 示例等部署方式,还包含了视觉处理工具,有助于开发者快速集成和使用,提升工作效率。
推荐工具精选







AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号