
PPO-PyTorch:简单而强大的强化学习算法实现
近端策略优化(Proximal Policy Optimization, PPO)是近年来广受欢迎的强化学习算法之一。PPO-PyTorch项目为我们提供了一个使用PyTorch框架实现PPO算法的最小化版本,让我们能够快速上手并理解这一强大的算法。本文将详细介绍PPO-PyTorch项目的特点、使用方法以及其在多个强化学习环境中的表现。
PPO算法简介
PPO算法是由OpenAI于2017年提出的一种基于策略梯度的强化学习算法。它的主要思想是在每次策略更新时,限制新旧策略之间的差异,从而实现稳定高效的策略优化。PPO算法具有以下几个主要优点:
- 实现简单,易于调试
- 采样效率高,能够有效利用收集到的样本数据
- 训练稳定性好,不易出现策略崩溃的情况
- 适用于连续和离散动作空间
正是由于这些优点,PPO算法在许多强化学习任务中都表现出色,成为了研究人员和工程师的首选算法之一。
PPO-PyTorch项目特点
PPO-PyTorch项目是由Nikhil Barhate开发的一个最小化PPO算法实现。该项目的主要特点包括:
- 使用PyTorch框架实现,代码简洁易懂
- 支持OpenAI Gym环境,可以方便地在各种强化学习任务上进行测试
- 同时支持离散和连续动作空间
- 提供了详细的使用说明和示例代码
- 包含了多个预训练模型,可以直接用于测试和演示
该项目的实现保持了简洁性,同时又不失功能完整性。为了保持代码的简单性,作者做了以下几点设计:
- 对于连续动作空间,使用固定的标准差作为输出动作分布的参数,而不是将其作为可训练参数。
- 使用简单的蒙特卡洛估计来计算优势函数,而不是更复杂的广义优势估计(GAE)。
- 采用单线程实现,只使用一个工作进程来收集经验数据。
这些设计选择使得代码更加易于理解和修改,非常适合初学者学习PPO算法的原理和实现细节。
使用方法
使用PPO-PyTorch项目非常简单,主要包括以下几个步骤:
- 训练新模型:运行
train.py文件 - 测试预训练模型:运行
test.py文件 - 绘制训练曲线:运行
plot_graph.py文件 - 生成演示GIF:运行
make_gif.py文件
所有的参数和超参数都可以在相应的Python文件中进行调整。此外,项目还提供了一个PPO_colab.ipynb文件,将所有功能集成在一个Jupyter notebook中,方便在Google Colab等平台上运行。
值得注意的是,如果环境在CPU上运行(如Box-2d和Roboschool),建议使用CPU作为训练设备,以获得更快的训练速度。这是因为在GPU上训练这些环境会导致频繁的CPU和GPU之间的数据传输,从而降低训练效率。
项目性能展示
PPO-PyTorch项目在多个经典的强化学习环境中都展现出了优秀的性能。以下是一些典型环境中的训练结果:
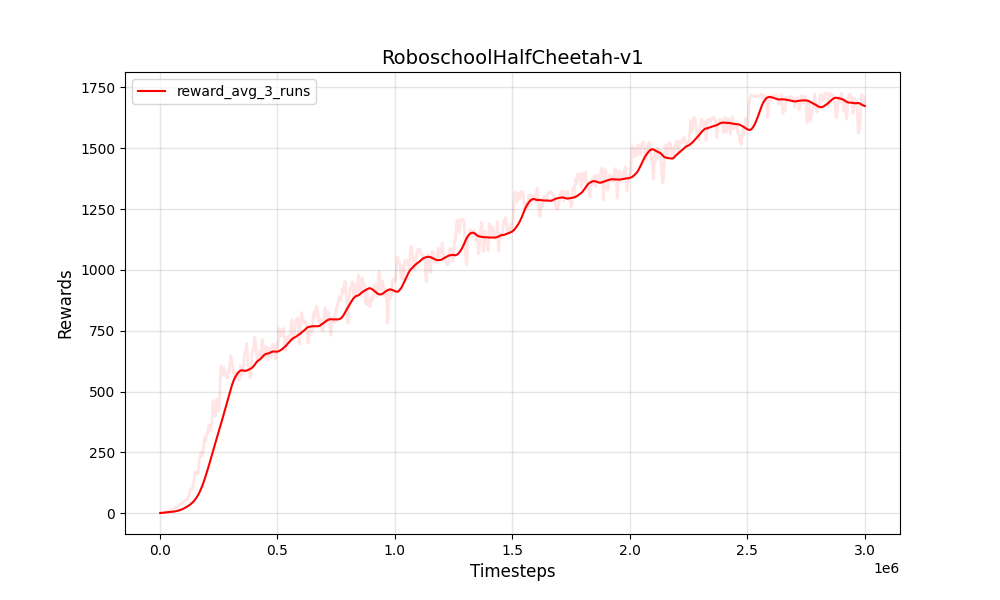
- RoboschoolHalfCheetah-v1 (连续动作空间)

- BipedalWalker-v2 (连续动作空间)

- CartPole-v1 (离散动作空间)

从这些演示中可以看出,PPO-PyTorch项目在各种类型的环境中都能学习到有效的策略,展现出了PPO算法的强大性能和通用性。
项目依赖
要运行PPO-PyTorch项目,需要安装以下依赖:
- Python 3
- PyTorch
- NumPy
- OpenAI Gym
对于特定的训练环境,还可能需要安装:
- Box-2d
- Roboschool
- PyBullet
此外,如果需要绘制图表和生成GIF,还需要安装:
- Pandas
- Matplotlib
- Pillow
深入理解PPO算法
虽然PPO-PyTorch项目提供了一个简化版的PPO实现,但要真正掌握PPO算法,还需要深入理解其背后的原理。PPO算法的核心思想是通过限制每次策略更新的幅度来提高训练的稳定性。具体来说,PPO算法引入了一个裁剪项,用于限制新旧策略之间的比率:
ratio = new_policy / old_policy
clipped_ratio = torch.clamp(ratio, 1-epsilon, 1+epsilon)
loss = -torch.min(ratio * advantages, clipped_ratio * advantages).mean()
这个裁剪机制确保了策略更新不会过大,从而避免了策略崩溃的问题。同时,PPO算法还采用了多个小批量数据进行多轮更新的方式,提高了样本利用效率。
扩展和改进
尽管PPO-PyTorch项目提供了一个功能完整的PPO实现,但仍有一些可以改进和扩展的方向:
- 实现并行数据收集,提高采样效率
- 添加广义优势估计(GAE),可能提高性能
- 实现自适应的KL散度惩罚项,进一步提高训练稳定性
- 集成更多的环境和任务,如Atari游戏或机器人控制任务
- 添加更多的可视化和分析工具,方便理解算法行为
这些改进可以进一步增强PPO-PyTorch项目的功能和性能,使其更适合于复杂的强化学习任务和研究需求。
结论
PPO-PyTorch项目为我们提供了一个简单而强大的PPO算法实现。通过这个项目,我们可以快速上手PPO算法,并在各种强化学习任务中应用它。无论是对于初学者还是经验丰富的研究人员,PPO-PyTorch都是一个值得学习和使用的工具。
随着强化学习技术的不断发展,像PPO这样的算法正在越来越多地应用于现实世界的问题中,如机器人控制、自动驾驶、游戏AI等领域。通过学习和使用PPO-PyTorch项目,我们可以更好地理解这些先进算法的工作原理,为未来的研究和应用奠定基础。
如果你对强化学习感兴趣,不妨尝试使用PPO-PyTorch项目,亲自体验PPO算法的魅力。同时,也欢迎为这个开源项目做出贡献,帮助它变得更加强大和易用。让我们一起推动强化学习技术的发展,创造更加智能的AI系统! 🚀🤖
参考资料
希望这篇文章能够帮助你更好地理解PPO算法和PPO-PyTorch项目。如果你有任何问题或想法,欢迎在评论中讨论!









