prometheus-eval学习资料汇总 - 专用于评估语言模型的开源框架
prometheus-eval是一个专门用于评估大型语言模型(LLM)生成能力的开源框架。它提供了简单易用的接口,可以方便地对指令-回复对进行评分和反馈。本文将为大家介绍prometheus-eval项目的主要特点,并汇总相关学习资源,帮助读者快速上手使用这个强大的评估工具。
项目简介
prometheus-eval是一个开源的语言模型评估框架,主要包含以下组件:
- prometheus-eval Python包:提供了使用Prometheus模型评估指令-回复对的简单接口
- 用于训练和评估Prometheus模型的评估数据集
- 训练Prometheus模型或在自定义数据集上微调的脚本
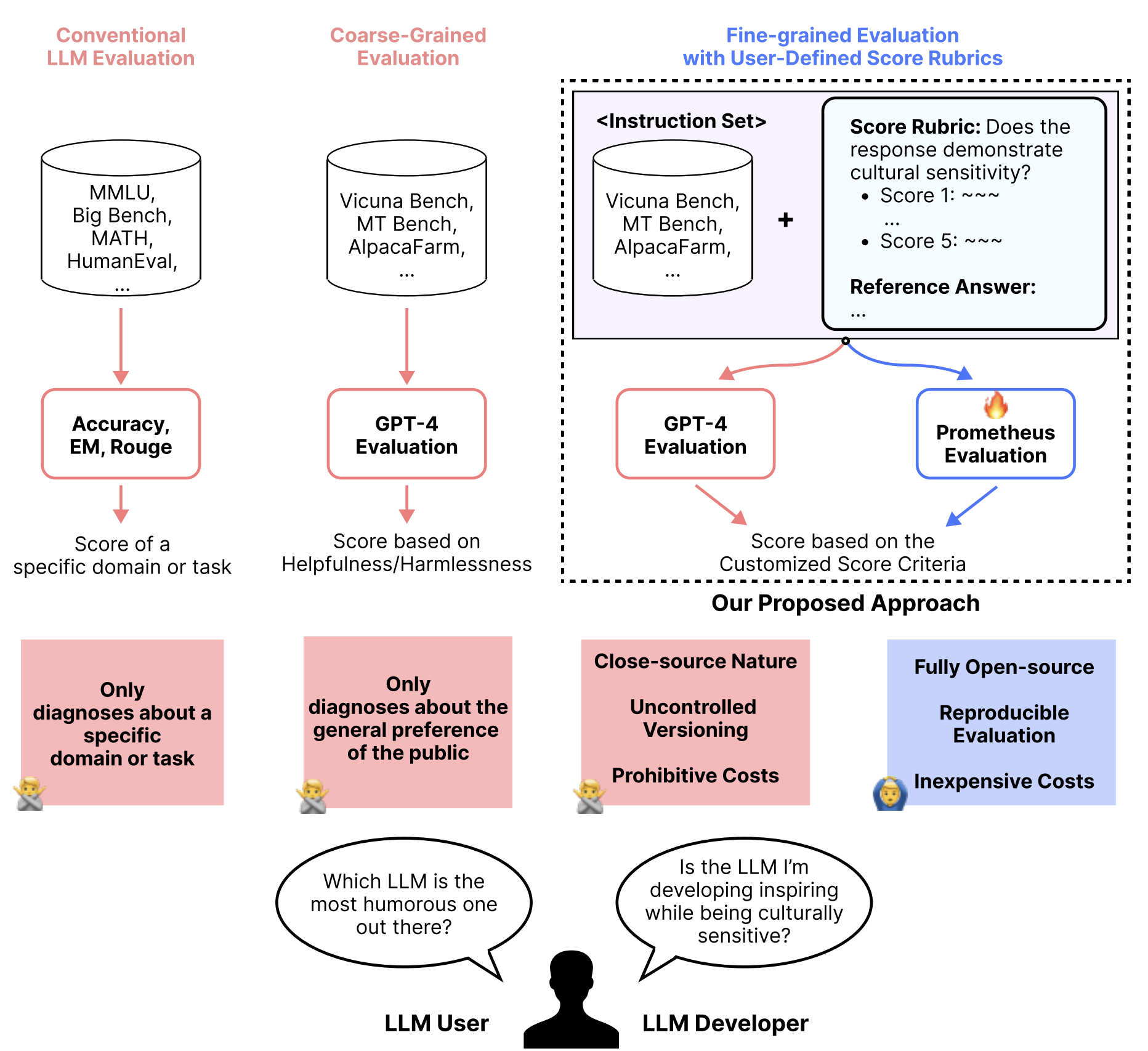
该项目的核心是Prometheus系列模型,这是一组专门用于评估其他语言模型的开源语言模型。通过有效模拟人类判断和专有LM评估,Prometheus旨在解决以下问题:
- 公平性:不依赖闭源模型进行评估
- 可控性:无需担心GPT版本更新或将私有数据发送给OpenAI
- 经济性:如果已有GPU,使用是免费的
主要特点
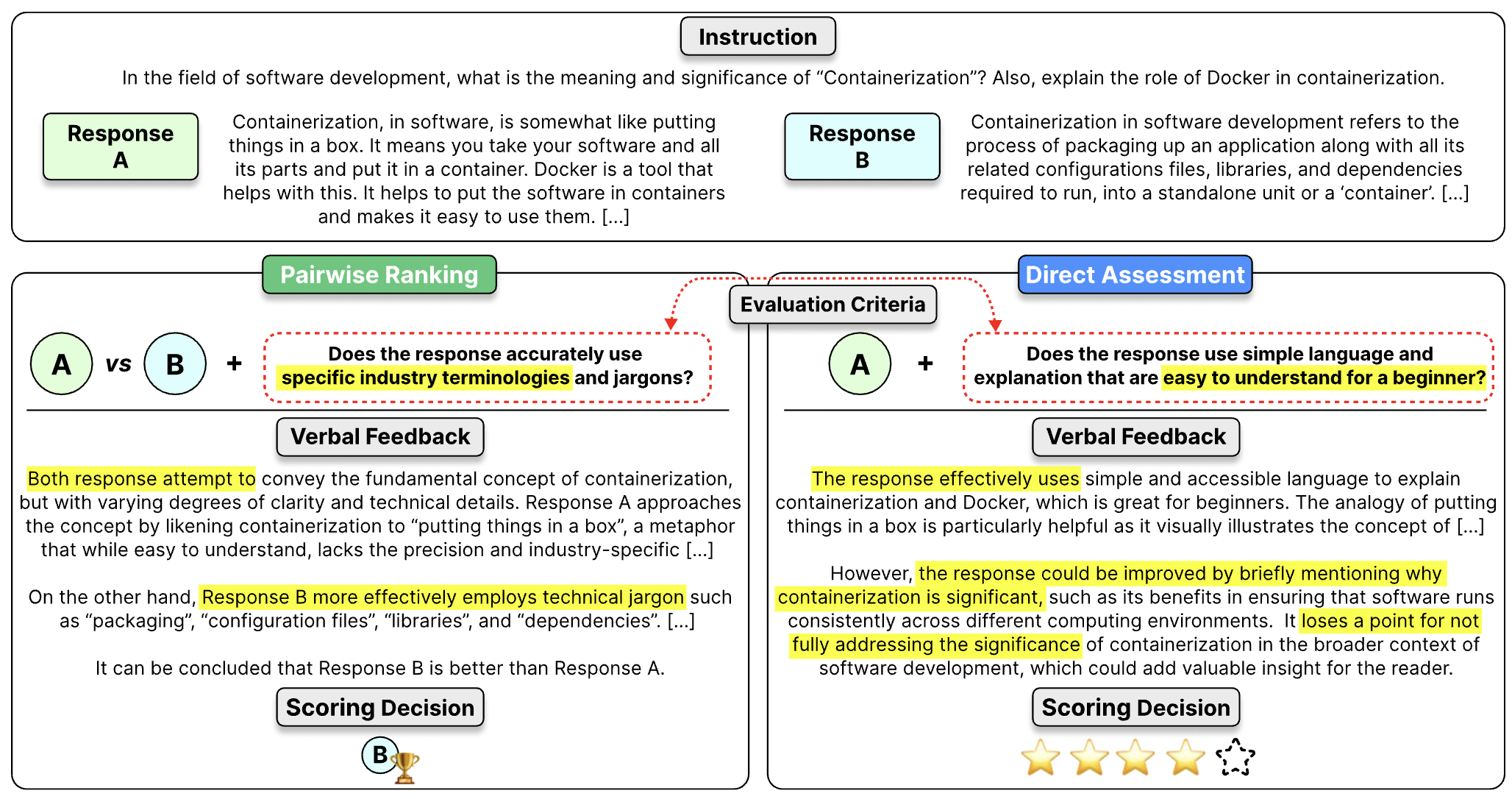
与Prometheus 1相比,Prometheus 2模型支持:
- 直接评估(绝对评分)
- 成对排序(相对评分)
用户可以通过提供不同的输入提示格式和系统提示来切换模式。在提示中,用户需要填写指令、回复、评分标准等数据。还可以选择添加参考答案以获得更好的性能。
安装使用
可以通过pip安装prometheus-eval:
pip install prometheus-eval
prometheus-eval支持通过vllm进行本地推理,也可以通过litellm使用LLM API进行推理。
基本使用示例:
from prometheus_eval.vllm import VLLM
from prometheus_eval import PrometheusEval
from prometheus_eval.prompts import ABSOLUTE_PROMPT, SCORE_RUBRIC_TEMPLATE
model = VLLM(model="prometheus-eval/prometheus-7b-v2.0")
judge = PrometheusEval(model=model, absolute_grade_template=ABSOLUTE_PROMPT)
feedback, score = judge.single_absolute_grade(
instruction=instruction,
response=response,
rubric=score_rubric,
reference_answer=reference_answer
)
print("Feedback:", feedback)
print("Score:", score)
学习资源
-
GitHub 仓库:包含完整的代码、文档和示例
-
BiGGen-Bench 评估:介绍如何使用BiGGen-Bench评估您的语言模型
-
训练 Prometheus:复现Prometheus 2模型的说明
-
作为数据质量过滤器:使用Prometheus 2作为合成数据生成中的质量过滤器
-
在RAG中使用:在RAG应用中使用Prometheus 2的教程
-
论文:详细介绍Prometheus 2的技术细节
-
Hugging Face模型:可以直接下载使用的模型权重
prometheus-eval为评估大型语言模型提供了一个强大而灵活的开源解决方案。通过学习和使用这个框架,研究人员和开发者可以更好地理解和改进他们的语言模型。希望这份学习资料汇总能帮助您快速上手prometheus-eval,充分发挥其潜力。