
Promptify: 让NLP任务变得简单而强大
在人工智能和自然语言处理(NLP)快速发展的今天,如何有效利用大型语言模型(LLM)解决实际NLP问题成为了一个热门话题。Promptify应运而生,它是一个开源项目,旨在简化NLP任务的提示工程过程,让开发者能够轻松驾驭GPT、PaLM等流行的生成模型。
Promptify的核心功能
Promptify提供了一系列强大的功能,使NLP任务的处理变得简单高效:
-
提示生成: 轻松生成和定制适用于最先进生成模型的提示。
-
统一架构: 引入了Prompter、Model和Pipeline解决方案,使整个流程更加流畅。
-
详细输出日志: 在日志文件夹中提供全面的结构化JSON格式输出。
-
广泛的模型支持: 支持来自OpenAI、Azure、Cohere、Anthropic、Huggingface等的模型,堪称通用语言模型适配器。
-
强大的解析器: 能够处理来自任何LLM的不完整或非结构化JSON输出。
-
现成的Jinja模板: 为命名实体识别(NER)、文本分类、问答、关系提取、表格数据等任务提供Jinja提示模板。
-
丰富的自定义选项: 可以根据特定需求(如产品描述、摘要或创意写作)调整提示。
快速上手Promptify
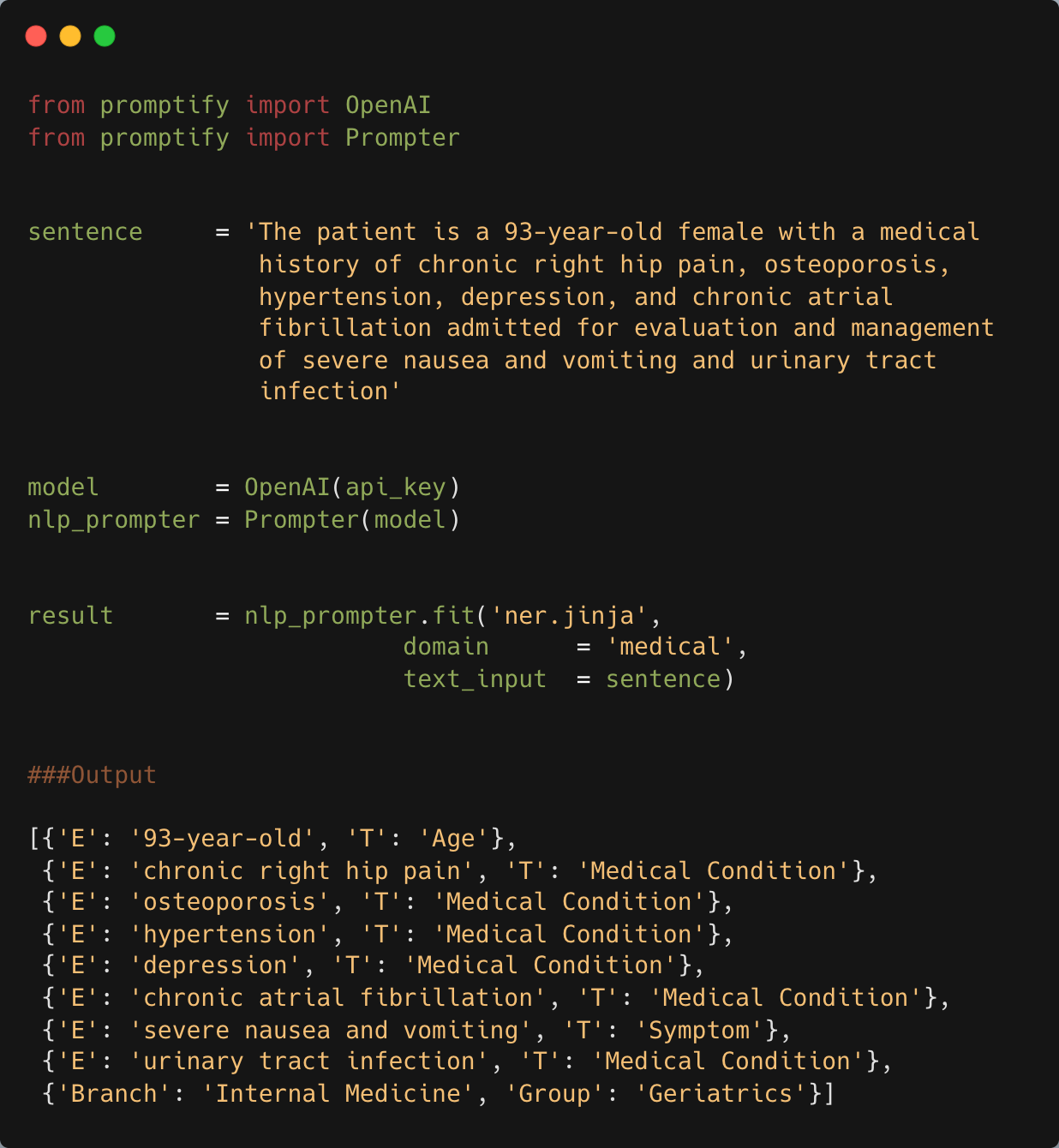
要开始使用Promptify,您只需要几个简单的步骤:
-
安装Promptify:
pip3 install promptify -
导入必要的模块:
from promptify import Prompter, OpenAI, Pipeline -
准备您的文本数据:
sentence = """The patient is a 93-year-old female with a medical history of chronic right hip pain, osteoporosis, hypertension, depression, and chronic atrial fibrillation admitted for evaluation and management of severe nausea and vomiting and urinary tract infection""" -
设置模型和提示器:
model = OpenAI(api_key) # 或使用其他支持的模型 prompter = Prompter('ner.jinja') # 选择模板或提供自定义模板 pipe = Pipeline(prompter, model) -
运行Pipeline并获取结果:
result = pipe.fit(sentence, domain="medical", labels=None)
这个简单的流程就能让您快速开始使用Promptify处理NLP任务。
Promptify支持的NLP任务
Promptify支持广泛的基于提示的NLP任务,包括但不限于:
- 命名实体识别(NER)
- 多标签文本分类
- 多类文本分类
- 二元文本分类
- 问答
- 问答生成
- 关系提取
- 文本摘要
- 解释生成
- SQL语句生成
对于每种任务类型,Promptify都提供了相应的Colab笔记本示例,方便用户快速学习和实践。
为什么选择Promptify?
Promptify不仅仅是一个工具,它是一个全面的解决方案,旨在弥合复杂NLP任务和实际应用之间的鸿沟。通过简化提示生成并提供广泛的定制选项,Promptify使用户能够充分发挥GPT、Claude等生成模型的潜力,使各种文本内容的创建变得快速、高效,并且对所有人都可以轻松上手。
社区与贡献
Promptify是一个开源项目,欢迎社区成员的贡献。如果您对提示工程、LLMs、ChatGPT和其他最新研究感兴趣,可以考虑加入PromptsLab Discord社区。在这里,您可以与其他开发者和研究人员交流想法,分享经验,共同推动NLP技术的发展。
对于希望为Promptify项目做出贡献的开发者,项目维护者欢迎各种形式的贡献,包括新功能、基础设施改进和更全面的文档。您可以查看项目的贡献指南以了解更多详情。
结语
Promptify作为一个强大而灵活的NLP工具,正在为自然语言处理领域带来革命性的变化。它不仅简化了复杂的NLP任务,还为开发者提供了一个探索和创新的平台。无论您是NLP新手还是经验丰富的专家,Promptify都能为您的项目带来价值。立即尝试Promptify,体验它如何改变您的NLP工作流程!











