
QiZhenGPT:开源中文医疗大语言模型
QiZhenGPT是一个开源的中文医疗大语言模型项目,旨在提高模型在中文医疗场景下的效果。本文将为大家介绍QiZhenGPT的相关学习资源,帮助读者快速了解和使用这个项目。
项目简介
QiZhenGPT利用启真医学知识库构建了中文医学指令数据集,并基于此在多个基础模型上进行了指令精调,大幅提高了模型在中文医疗场景下的效果。项目目前主要针对药品知识问答进行了优化,后续计划扩展到疾病、手术、检验等多个方面。
模型下载
QiZhenGPT提供了多个版本的模型供下载使用:
- QiZhen-Chinese-LLaMA-7B
- QiZhen-ChatGLM-6B
- QiZhen-CaMA-13B
这些模型的LoRA权重可以在项目的百度网盘下载。
快速使用
以QiZhen-Chinese-LLaMA-7B为例,使用步骤如下:
- 安装环境:
pip install -r requirements.txt
- 获取Chinese-LLaMA-Plus-7B基础模型
- 下载QiZhenGPT的LoRA权重
- 执行merge_llama_plus.sh脚本合并模型
- 修改demo脚本中的模型路径
- 运行demo:
python gradio_chinese-llama_demo.py
其他版本模型的使用方法类似,详见项目README。
训练数据
项目开源了20k条训练数据样本,包括真实医患问答数据和基于知识库构造的指令数据。
评测数据
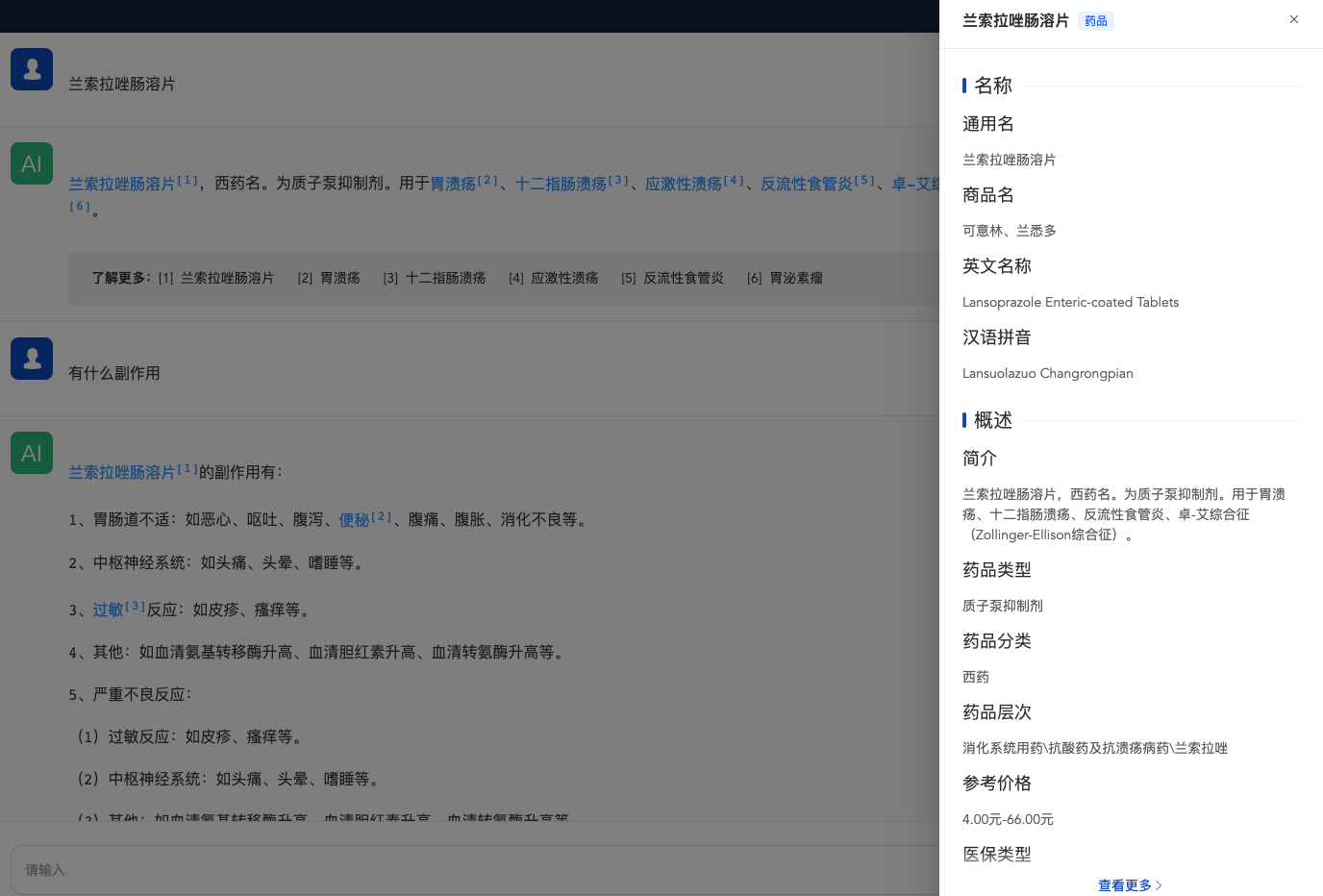
项目提供了药品适应症评测数据集,可用于评估模型在药品知识问答方面的效果。
更多资源
- 项目GitHub仓库:包含完整的代码、数据和文档
- 启真医学知识库:QiZhenGPT使用的医学知识来源
- 相关论文:介绍项目的技术路线和未来规划
QiZhenGPT作为一个开源的中文医疗大语言模型项目,为推动AI技术在医疗领域的应用做出了重要贡献。希望本文的资源汇总能帮助读者更好地了解和使用这个项目,共同促进医疗AI的发展。如有任何问题,欢迎在项目GitHub仓库中提出issue进行讨论。










