
RAG Fusion: 检索增强生成的革命性突破
在人工智能和自然语言处理领域的最新进展中,RAG Fusion 技术的出现标志着检索增强生成(Retrieval Augmented Generation, RAG)进入了一个新的发展阶段。这项创新技术通过结合多查询生成和检索结果重排序等方法,有效解决了传统 RAG 模型面临的诸多挑战,为 AI 系统提供了更加智能和精准的信息检索能力。
RAG Fusion 的核心理念
RAG Fusion 的核心思想是通过生成多个相关查询并对检索结果进行智能重排,来弥合用户输入查询与其真实意图之间的差距。这种方法不仅提高了检索的全面性,还能更好地捕捉查询的潜在语境和含义。
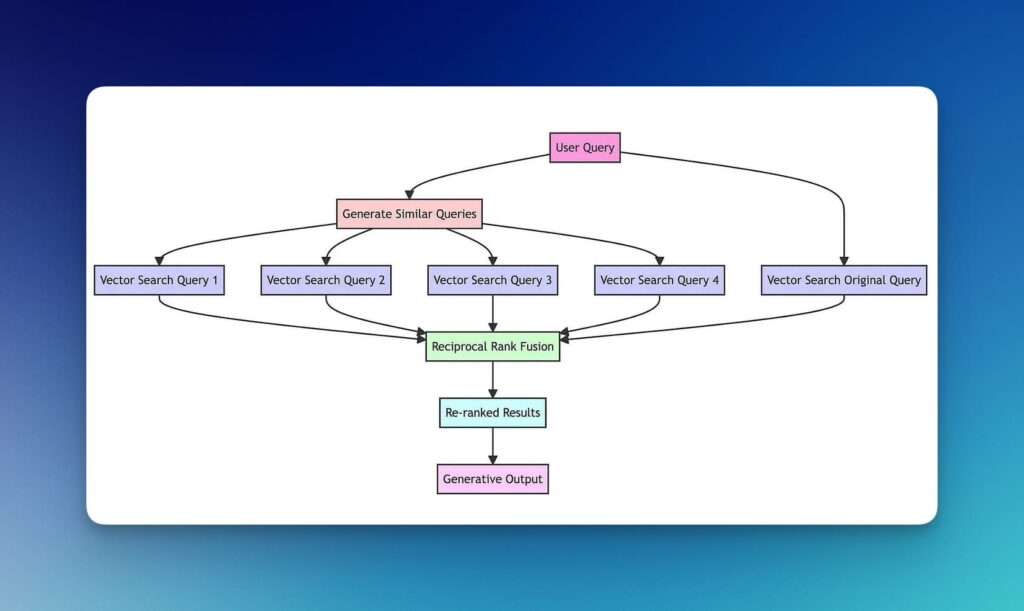
技术原理与实现
-
多查询生成:利用大型语言模型(如 GPT)将用户的原始查询转化为多个相关但不同的查询变体。这一步骤扩大了搜索范围,提高了检索到相关信息的概率。
-
向量搜索:对每个生成的查询进行向量化搜索,从预定义的文档集合中检索相关内容。
-
倒数排名融合(Reciprocal Rank Fusion, RRF):应用 RRF 算法对检索到的文档进行重新排序。这种方法综合考虑了文档在多个查询结果中的排名,有效提升了最终结果的相关性。
-
结果整合与输出:将重排序后的文档列表作为最终输出,为后续的生成任务提供高质量的上下文信息。
RAG Fusion 的优势
相比传统的 RAG 方法,RAG Fusion 具有以下显著优势:
-
提高检索质量:通过多查询策略,RAG Fusion 能够更全面地覆盖用户查询的不同方面,大大提高了相关信息的召回率。
-
增强语境理解:多查询生成过程实际上是对原始查询进行了语义扩展,有助于捕捉更丰富的语境信息。
-
改善排序效果:RRF 算法的应用确保了最相关的文档能够被优先考虑,提升了检索结果的整体质量。
-
减少模型幻觉:通过提供更加准确和全面的检索结果,RAG Fusion 能够有效减少 AI 模型产生不实信息的可能性。
-
适应复杂查询:对于结构复杂或措辞模糊的查询,RAG Fusion 表现出色,能够更好地理解和响应用户意图。
应用场景
RAG Fusion 技术在多个领域都展现出巨大的应用潜力:
-
智能客服系统:能够更准确地理解和回答用户的复杂问题,提供全面的技术支持。
-
医疗咨询:帮助医疗 AI 系统更精准地检索和整合相关医学文献,为诊断和治疗提供支持。
-
学术研究:辅助研究人员快速定位和综合分析跨学科的相关文献。
-
法律咨询:提升法律 AI 系统检索相关案例和法规的能力,为法律分析提供更全面的参考。
-
个性化推荐系统:通过更深入理解用户需求,提供更加精准的产品或内容推荐。
实现 RAG Fusion
要实现 RAG Fusion,开发者需要结合多种技术和工具:
-
大型语言模型:如 OpenAI 的 GPT 系列,用于生成多样化的查询变体。
-
向量数据库:如 Elasticsearch 或 Pinecone,用于高效的向量搜索。
-
编程语言:Python 是实现 RAG Fusion 的常用语言,配合 LangChain 等框架可以简化开发流程。
-
RRF 算法实现:需要编写代码来实现倒数排名融合算法,用于结果重排序。
以下是一个简化的 RAG Fusion 实现示例:
import openai
from langchain import OpenAI, PromptTemplate
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
# 初始化必要的组件
llm = OpenAI(temperature=0)
embeddings = OpenAIEmbeddings()
vectorstore = Chroma("your_data", embeddings)
# 多查询生成
def generate_queries(original_query):
prompt = PromptTemplate(
input_variables=["query"],
template="Generate 3 different versions of the following query:\n{query}"
)
response = llm(prompt.format(query=original_query))
return response.split("\n")
# 向量搜索
def vector_search(queries, top_k=5):
results = []
for query in queries:
results.extend(vectorstore.similarity_search(query, k=top_k))
return results
# RRF 重排序
def rrf_rerank(results, k=60):
scores = {}
for rank, doc in enumerate(results):
if doc not in scores:
scores[doc] = 0
scores[doc] += 1 / (rank + k)
return sorted(scores.items(), key=lambda x: x[1], reverse=True)
# 主函数
def rag_fusion(query):
queries = generate_queries(query)
search_results = vector_search(queries)
reranked_results = rrf_rerank(search_results)
return reranked_results
# 使用示例
results = rag_fusion("What are the latest advancements in AI?")
for doc, score in results[:5]:
print(f"Score: {score:.4f}, Content: {doc.page_content[:100]}...")
未来展望
尽管 RAG Fusion 已经显示出其强大的潜力,但这项技术仍处于不断发展和完善的阶段。未来的研究方向可能包括:
-
查询生成的进一步优化:探索如何生成更加多样化且有针对性的查询变体。
-
动态调整 RRF 参数:研究如何根据不同类型的查询自动调整 RRF 算法的参数,以获得最佳的重排序效果。
-
与其他 AI 技术的结合:探索将 RAG Fusion 与其他先进的 AI 技术(如强化学习、多模态学习等)相结合的可能性。
-
效率优化:考虑到 RAG Fusion 涉及多次查询和复杂的重排序过程,如何在保证性能的同时提高系统效率是一个重要的研究方向。
-
特定领域的适应性:研究如何针对不同的应用领域(如医疗、法律、金融等)定制 RAG Fusion 模型,以满足特定领域的需求。
结语
RAG Fusion 技术的出现无疑为检索增强生成领域带来了新的活力和可能性。通过巧妙地结合多查询生成和检索结果重排序,RAG Fusion 有效地提升了 AI 系统理解和响应复杂人类查询的能力。随着这项技术的不断发展和完善,我们可以期待看到更多智能、精准且富有洞察力的 AI 应用在各个领域蓬勃发展。对于开发者和研究人员来说,RAG Fusion 提供了一个充满挑战和机遇的新领域,值得深入探索和研究。

通过持续的创新和实践,RAG Fusion 有望成为推动下一代 AI 系统发展的关键技术之一,为人工智能与人类需求之间搭建更加智能和高效的桥梁。









