
react-llm简介
react-llm是一个开源的React库,它提供了一套易用的Hooks API,可以让开发者在浏览器中轻松运行大型语言模型(LLM)。该项目的核心理念是"让在前端使用LLM变得简单",开发者只需调用useLLM()这样简洁的Hook即可实现复杂的LLM功能。
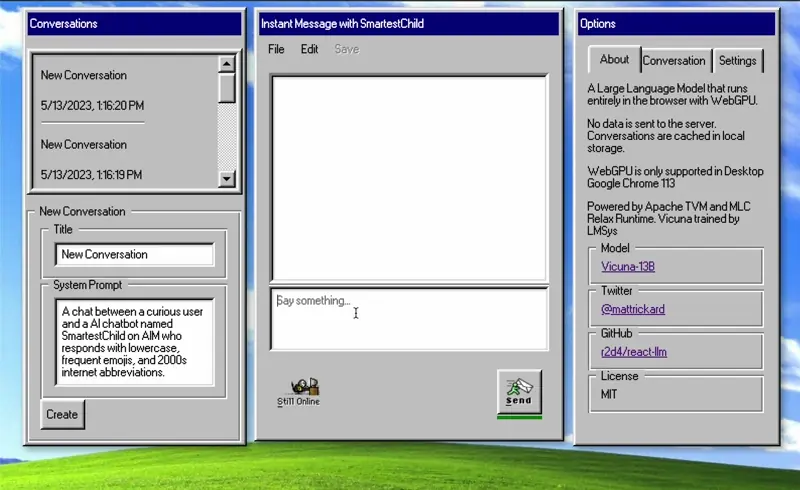
主要特性
react-llm具有以下主要特性:
- 支持Vicuna 7B等大型语言模型
- 可自定义系统提示词和角色名称
- 提供max tokens、stop sequences等补全选项
- 所有数据处理均在浏览器内完成,通过WebGPU加速
- 提供"自带UI"的Hooks设计
- 支持在浏览器存储中持久化对话内容
- 模型缓存功能,加快后续加载速度
安装使用
通过npm安装:
npm install @react-llm/headless
API接口
react-llm提供了useLLM Hook作为主要接口,返回以下方法和状态:
const {
conversation,
allConversations,
loadingStatus,
isGenerating,
createConversation,
setConversationId,
deleteConversation,
deleteAllConversations,
deleteMessages,
setConversationTitle,
onMessage,
setOnMessage,
userRoleName,
setUserRoleName,
assistantRoleName,
setAssistantRoleName,
gpuDevice,
send,
init
} = useLLM();
项目结构
react-llm包含以下几个主要模块:
- @react-llm/model - 为浏览器编译的LLM模型和分词器
- @react-llm/retro-ui - 复古风格的UI组件
- @react-llm/extension - 使用react-llm的Chrome扩展
- @react-llm/headless - 核心的无头React Hooks
工作原理
react-llm通过以下技术实现在浏览器中运行LLM:
- SentencePiece分词器(通过Emscripten编译到浏览器)
- Vicuna 7B模型(转换为Apache TVM格式)
- Apache TVM和MLC Relax(通过Emscripten编译到浏览器)
- Web Worker离线线程运行模型
模型、分词器和TVM运行时从CDN加载,并缓存到浏览器存储中以加快后续加载。
示例代码
以下是一个简单的使用示例:
import { ModelProvider } from "@react-llm/headless";
export default function Home() {
return (
<ModelProvider
config={{
kvConfig: {
numLayers: 64,
shape: [32, 32, 128],
dtype: 'float32',
},
wasmUrl: 'https://your-custom-url.com/model.wasm',
cacheUrl: 'https://your-custom-url.com/cache/',
tokenizerUrl: 'https://your-custom-url.com/tokenizer.model',
sentencePieceJsUrl: 'https://your-custom-url.com/sentencepiece.js',
tvmRuntimeJsUrl: 'https://your-custom-url.com/tvmjs_runtime.wasi.js',
maxWindowSize: 2048,
persistToLocalStorage: true,
}}
>
<Chat />
</ModelProvider>
);
}
相关资源
react-llm为开发者提供了一种简单而强大的方式来在前端集成LLM功能。无论是构建智能对话界面,还是其他需要自然语言处理的应用,react-llm都是一个值得尝试的工具。希望这篇介绍能帮助你快速上手react-llm,开启AI驱动的前端开发之旅!









