
RefChecker:检测大型语言模型幻觉的新利器
大型语言模型(LLM)在各种应用中展现出令人惊叹的能力,但它们也存在一个明显的弱点 - 幻觉。所谓幻觉,指的是模型生成看似合理但实际上并不准确的内容。有时这些幻觉可能非常微妙,比如只是将某个日期错误地提前或推后了一两年。为了帮助检测这些细微的幻觉,亚马逊最近发布了一个名为RefChecker的新工具。
RefChecker的核心特性
RefChecker是一个用于检测幻觉的标准化评估框架,同时也提供了一个基准数据集。它具有以下几个突出特点:
-
更精细的粒度 - RefChecker将LLM响应中的声明分解为知识三元组,而不是段落、句子或子句。这种方法可以更精确地测试事实的真实性。
-
更广泛的覆盖 - 基于提供给LLM的上下文质量和数量,RefChecker区分了三种不同的设置:
- 零上下文:提示是一个没有任何上下文的事实性问题(如开放式问答)
- 噪声上下文:提示是一个问题以及一组检索到的文档(如检索增强生成RAG)
- 准确上下文:提示是一个问题以及一个文档(如摘要生成)
-
人工评估 - RefChecker包含2100个人工标注的LLM响应,包括300个测试样本,每个样本由7个流行的LLM(如GPT-4、Claude 2等)生成响应。
-
模块化架构 - RefChecker是一个3阶段的流水线,包括声明提取器、幻觉检查器和聚合规则。它们可以通过命令行单独调用和配置。
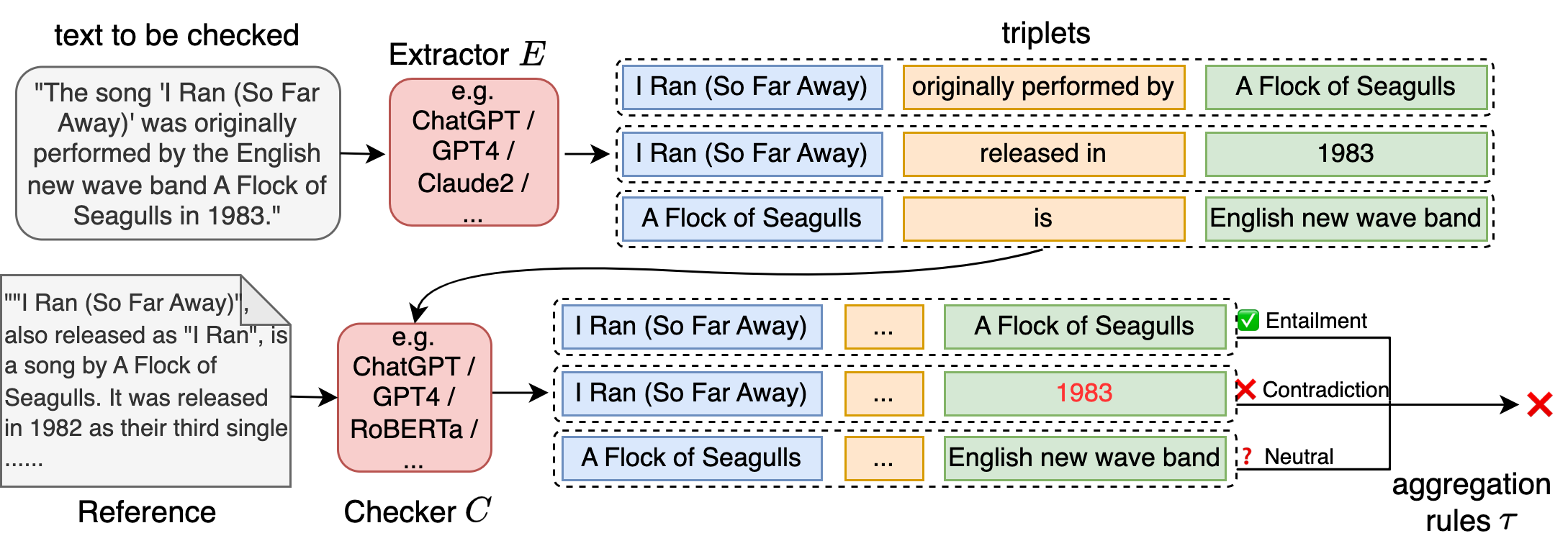
工作原理
RefChecker的工作流程包括以下几个关键步骤:
-
声明提取 - 首先使用LLM从输入文本中提取知识三元组。这些三元组采用<主语,谓语,宾语>的结构,能够捕获更细粒度的信息。
-
参考收集 - 根据不同的场景(零上下文、噪声上下文、准确上下文)收集相应的参考文本。
-
事实检查 - 将提取的声明三元组与参考文本进行比对,判断是否存在幻觉。
-
结果聚合 - 根据预定义的规则,将单个三元组的检查结果聚合,得出整体的幻觉评估结果。
基准数据集
RefChecker还提供了一个包含300个示例的基准数据集,每种设置(零上下文、噪声上下文、准确上下文)各100个。这些示例来自不同的数据源:
- 零上下文:NaturalQuestions(开发集)
- 噪声上下文:MS MARCO(开发集)
- 准确上下文:databricks-dolly-15k
研究人员收集了7个流行LLM(包括GPT-4、Claude 2等)在这个基准数据集上的响应,并进行了人工评估。这为比较不同LLM的幻觉生成情况提供了宝贵的资源。
使用RefChecker
要开始使用RefChecker,可以按照以下步骤操作:
-
从GitHub克隆RefChecker仓库:
git clone https://github.com/amazon-science/RefChecker.git -
安装依赖:
pip install -e . python -m spacy download en_core_web_sm -
选择合适的模型作为提取器和检查器。RefChecker使用litellm来调用LLM,支持多种模型提供商。
-
运行提取和检查:
from refchecker import LLMExtractor, LLMChecker extractor = LLMExtractor(model="your_model", batch_size=8) checker = LLMChecker(model="your_model", batch_size=8) extraction_results = extractor.extract( batch_responses=responses, batch_questions=questions, max_new_tokens=1000 ) batch_claims = [[c.content for c in res.claims] for res in extraction_results] batch_labels = checker.check( batch_claims=batch_claims, batch_references=references, max_reference_segment_length=0 )
RefChecker还提供了命令行界面,可以更方便地运行整个流水线:
refchecker-cli extract-check \
--input_path {INPUT_PATH} \
--output_path {OUTPUT_PATH} \
--extractor_name {EXTRACTOR_NAME} \
--checker_name {CHECKER_NAME} \
--extractor_api_base {EXTRACTOR_API_BASE} \
--checker_api_base {CHECKER_API_BASE} \
--aggregator_name {strict,soft,major}
未来展望
RefChecker为检测LLM生成内容中的幻觉提供了一个强大的工具。然而,研究人员也承认该工具还存在一些限制,需要进一步改进:
- 开发更轻量级、性能更好的开源提取器和检查器
- 改进外部搜索工具,更准确地检测错误记忆
- 扩展任务覆盖范围,包含更多LLM应用场景
- 增加helpfulness评估,避免生成事实正确但无用的响应
RefChecker的发布为LLM幻觉检测研究开辟了新的方向。随着更多研究人员的参与和贡献,我们有理由相信,在不久的将来,LLM生成内容的可靠性将得到显著提升。
作为一个开源项目,RefChecker欢迎社区的贡献。无论是改进现有功能,还是添加新特性,都可以通过GitHub提交pull request。研究人员也鼓励使用者通过GitHub issues提供反馈,帮助进一步完善这个工具。
总的来说,RefChecker代表了LLM评估和改进的一个重要里程碑。它不仅提供了一个标准化的框架来检测幻觉,还为未来的研究指明了方向。随着这项技术的不断发展,我们可以期待看到更加可靠、更值得信赖的AI系统出现。









