
Retentioneering简介
Retentioneering是一个创新的Python库,专门为产品分析、用户行为研究和客户旅程优化而设计。它为数据分析师、产品经理和营销专业人士提供了一套强大的工具,用于深入分析用户轨迹数据,从而获得比传统漏斗分析更广泛、更深入的洞察。
通过Retentioneering,分析人员可以轻松探索用户行为模式,对用户进行分群,并形成关于什么因素驱动用户采取期望行动或流失的假设。这个库的独特之处在于它能够处理点击流数据,构建行为分群,并突出显示影响转化率、留存率和收入的用户行为事件和模式。
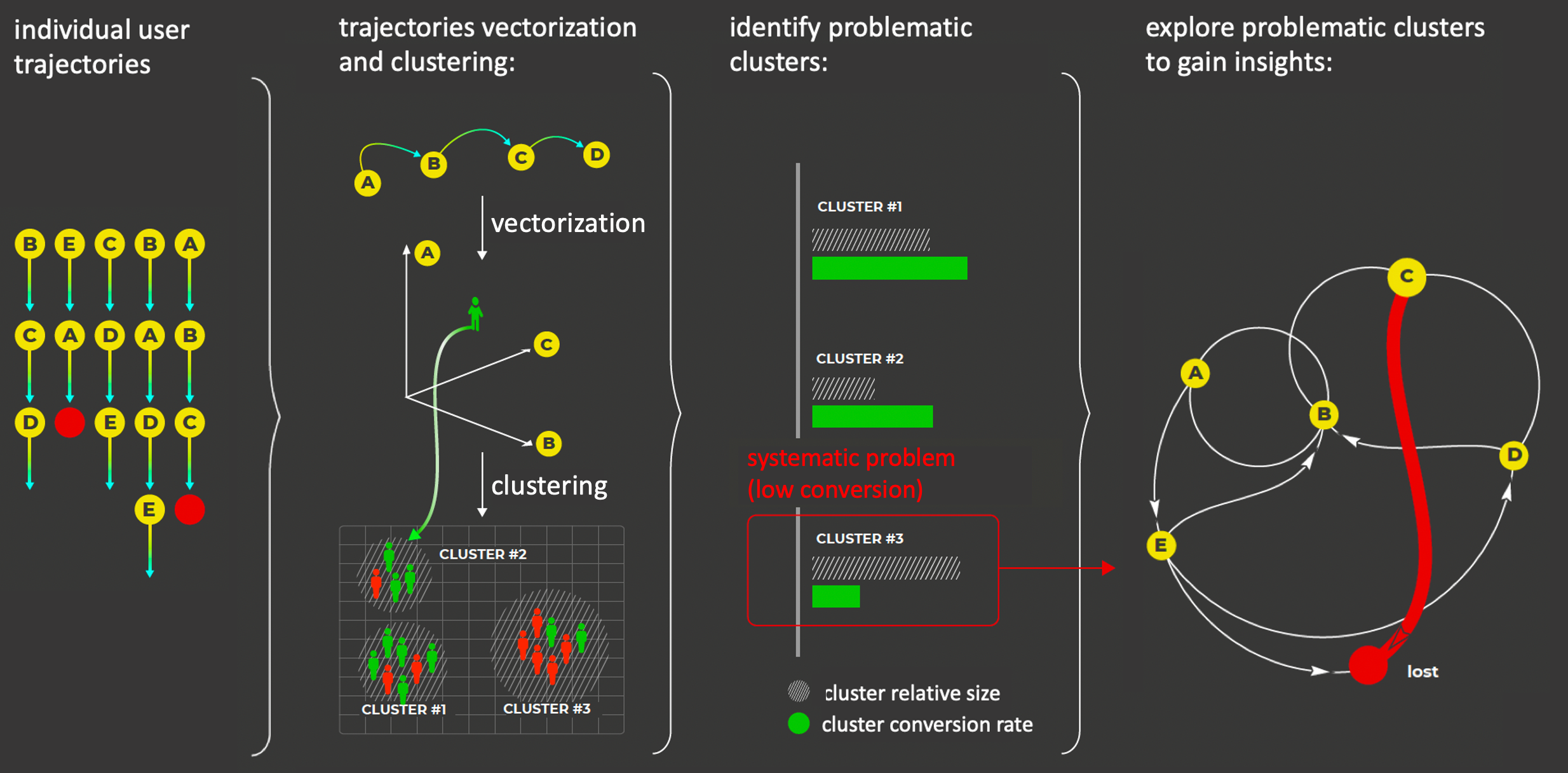
Retentioneering的主要功能
Retentioneering由两个主要部分组成:预处理模块和路径分析工具。
预处理模块
预处理模块提供了一系列专门用于处理点击流数据的实用方法。这些方法可以通过代码调用,也可以通过预处理GUI使用。主要功能包括:
- 事件分组和过滤
- 将点击流分割为会话
- 数据清洗和转换
通过使用这些预处理方法,分析人员可以大大减少代码量,降低潜在错误。此外,这些方法还有助于使计算结构化和可重现,特别适合处理复杂的分支分析。
路径分析工具
路径分析工具为产品分析引入了基于行为驱动的用户分群方法。它提供了一套强大的技术,用于对客户旅程地图进行深入分析。这些工具的特点是提供信息丰富和交互式的可视化,使分析人员能够快速理解点击流的复杂结构。
主要的分析工具包括:
- 转换图(Transition Graph)
- 步骤矩阵(Step Matrix)
- 步骤桑基图(Step Sankey)
- 聚类分析(Clusters)
- 漏斗分析(Funnel)
- 同期群分析(Cohorts)
- 统计检验(Stattests)
Retentioneering的优势
-
深入洞察: 相比传统的漏斗分析,Retentioneering提供了更深入、更全面的用户行为洞察。
-
易于使用: 作为Jupyter环境的自然扩展,Retentioneering使用起来非常直观,即使不是Python专家也能快速上手。
-
灵活性: 它扩展了pandas、NetworkX和scikit-learn等库的功能,使得处理序列事件数据更加高效。
-
可视化: 提供了丰富的交互式可视化工具,帮助分析人员快速理解复杂的用户行为模式。
-
可重复性: 预处理模块使得分析过程更加结构化和可重复,特别适合团队协作。
使用场景
Retentioneering在多个领域都有广泛应用,包括但不限于:
-
产品优化: 通过分析用户行为路径,识别产品中的痛点和改进机会。
-
营销分析: 评估营销活动的效果,优化用户获取和留存策略。
-
用户分群: 基于行为模式对用户进行分群,制定针对性的策略。
-
转化率优化: 识别影响转化的关键因素,优化用户旅程。
-
A/B测试分析: 深入分析A/B测试结果,了解不同版本对用户行为的影响。
快速开始
要开始使用Retentioneering,您可以通过pip安装:
pip install retentioneering
或者在Jupyter notebook或Google Colab中直接安装:
!pip install retentioneering
安装完成后,建议从快速入门文档开始,了解基本用法和概念。
数据要求
Retentioneering可以处理来自Google Analytics BigQuery流或其他类似流的数据。只需将数据转换为用户ID、事件和时间戳的三元组列表,即可传递给Retentioneering工具进行分析。
社区和支持
Retentioneering是一个积极发展的开源项目,欢迎社区贡献新想法、报告bug、修复问题和改进文档。如果您在使用过程中遇到任何问题,可以通过以下渠道寻求帮助:
结语
Retentioneering为产品分析和用户行为研究提供了一个强大而灵活的工具集。通过深入分析用户轨迹数据,它帮助企业更好地理解用户需求,优化产品体验,并制定数据驱动的决策。无论您是产品经理、数据分析师还是营销专业人士,Retentioneering都能为您的工作提供宝贵的洞察和支持。
随着数据驱动决策在企业中的重要性不断提升,像Retentioneering这样的工具将在塑造未来的产品开发和用户体验优化方面发挥越来越重要的作用。我们鼓励您探索Retentioneering的功能,并将其整合到您的分析工作流程中,以获得更深入的用户洞察和更好的业务成果。










