
RL Games: 高性能强化学习框架
RL Games是一个用于实现各种强化学习算法的高性能框架。它支持多种流行的强化学习算法,并可与多种环境和仿真器集成,实现端到端的GPU加速训练。本文将详细介绍RL Games的主要特性、支持的算法和环境,以及如何使用该框架进行强化学习任务的训练。
主要特性
RL Games具有以下主要特性:
-
高性能:支持端到端的GPU加速训练,可实现高效的强化学习算法实现。
-
多算法支持:实现了PPO、SAC、Rainbow DQN、A2C等多种流行的强化学习算法。
-
多环境支持:可与Isaac Gym、Brax、Mujoco、Atari等多种环境和仿真器集成。
-
多智能体训练:支持多智能体训练,包括分散式和集中式critic。
-
自对弈:支持自对弈训练。
-
RNN支持:支持使用LSTM和GRU等循环神经网络。
-
异步Actor-Critic:支持异步Actor-Critic变体。
-
动作掩码:支持动作掩码。
支持的算法
RL Games目前支持以下强化学习算法:
- PPO (Proximal Policy Optimization)
- SAC (Soft Actor-Critic)
- Rainbow DQN
- A2C (Advantage Actor-Critic)
其中PPO和SAC是当前最常用的算法,适用于连续动作空间。Rainbow DQN和A2C则主要用于离散动作空间。
支持的环境
RL Games可以与多种流行的强化学习环境和物理仿真器集成,包括:
- NVIDIA Isaac Gym:高性能GPU加速物理仿真环境
- Brax:Google开发的可微分物理引擎
- MuJoCo:OpenAI开发的物理引擎,适用于机器人控制等任务
- Atari:经典的Atari游戏环境
- DeepMind Control Suite:DeepMind开发的连续控制任务集
- StarCraft II:暴雪的即时战略游戏,用于多智能体研究
这些环境涵盖了从简单的控制问题到复杂的多智能体任务,可以满足不同类型的强化学习研究需求。
安装
RL Games可以通过pip安装:
pip install rl-games
建议先安装PyTorch 2.2或更新版本,以获得最佳性能:
conda install pytorch torchvision pytorch-cuda=12.1 -c pytorch -c nvidia
或
pip install torch torchvision
快速开始
RL Games提供了多个Colab notebook,可以快速开始使用:
这些notebook涵盖了从基本训练到模型导出的多个方面,可以帮助用户快速上手RL Games框架。
训练示例
以下是一些使用RL Games进行训练的示例命令:
NVIDIA Isaac Gym环境
# 训练Ant环境
python train.py task=Ant headless=True
# 测试训练好的Ant模型
python train.py task=Ant test=True checkpoint=nn/Ant.pth num_envs=100
# 训练Humanoid环境
python train.py task=Humanoid headless=True
# 训练Shadow Hand环境
python train.py task=ShadowHand headless=True
Atari环境
# 训练Pong
python runner.py --train --file rl_games/configs/atari/ppo_pong.yaml
# 测试训练好的Pong模型
python runner.py --play --file rl_games/configs/atari/ppo_pong.yaml --checkpoint nn/PongNoFrameskip.pth
Brax环境
# 训练Ant
python runner.py --train --file rl_games/configs/brax/ppo_ant.yaml
# 测试训练好的Ant模型
python runner.py --play --file rl_games/configs/brax/ppo_ant.yaml --checkpoint runs/Ant_brax/nn/Ant_brax.pth
实验跟踪
RL Games支持使用Weights and Biases进行实验跟踪:
# 使用wandb跟踪训练过程
python runner.py --train --file rl_games/configs/atari/ppo_breakout_torch.yaml --track
# 指定wandb项目名
python runner.py --train --file rl_games/configs/atari/ppo_breakout_torch.yaml --wandb-project-name rl-games-test --track
多GPU训练
RL Games使用torchrun来协调多GPU训练:
torchrun --standalone --nnodes=1 --nproc_per_node=2 runner.py --train --file rl_games/configs/ppo_cartpole.yaml
配置参数
RL Games使用YAML文件进行配置。以下是一些重要的配置参数:
algo.name: 算法名称,如"a2c_continuous"model.name: 模型名称,如"continuous_a2c_logstd"network: 网络结构配置config: 强化学习配置env_name: 环境名称num_actors: 并行环境数量horizon_length: 每个actor的horizon长度minibatch_size: mini-batch大小mini_epochs: 每次更新的epoch数lr_schedule: 学习率调度策略normalize_input: 是否对输入进行归一化normalize_value: 是否对值函数进行归一化
完整的配置参数列表可以参考项目文档。
自定义网络
RL Games支持自定义网络结构。用户可以创建自己的网络类,并通过以下方式注册:
from rl_games.envs.test_network import TestNetBuilder
from rl_games.algos_torch import model_builder
model_builder.register_network('testnet', TestNetBuilder)
然后在配置文件中使用自定义网络:
network:
name: testnet
...
结果展示
RL Games在多个环境中都取得了不错的结果。以下是一些训练结果的可视化:


上图展示了在Isaac Gym环境中训练的Ant和Humanoid模型。

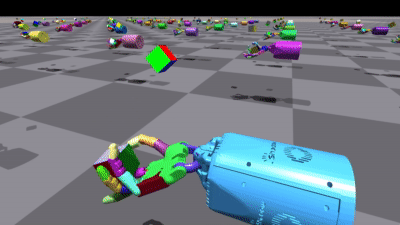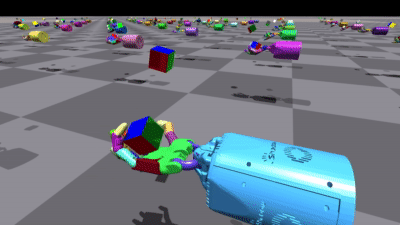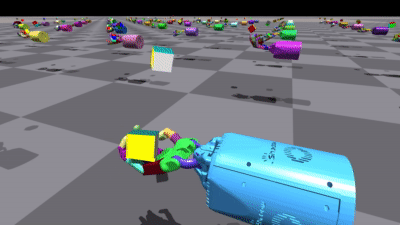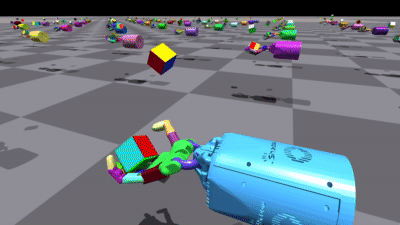
这两张图展示了训练好的机器人手模型,分别是Allegro Hand和Shadow Hand。
更多结果可以在项目文档中查看。
总结
RL Games是一个功能强大、性能优秀的强化学习框架。它支持多种算法和环境,可以实现端到端的GPU加速训练,适用于从简单控制到复杂多智能体任务的多种强化学习研究。通过提供丰富的示例和详细的文档,RL Games降低了使用门槛,使得研究人员和开发者可以快速开始强化学习实验。
无论是进行基础的强化学习研究,还是开发实际应用,RL Games都是一个值得考虑的工具。随着持续的更新和社区贡献,相信RL Games会在未来为更多的强化学习项目提供支持。
🔗 相关链接:
希望这篇文章能帮助你了解RL Games框架,并在你的强化学习项目中发挥作用。如果你有任何问题或建议,欢迎在GitHub上提issue或贡献代码。让我们一起推动强化学习的发展! 🚀🤖









