
RLCard:一个强大的卡牌游戏强化学习工具包
RLCard是由德克萨斯A&M大学和莱斯大学的DATA实验室开发的一个开源强化学习工具包,专门用于卡牌游戏领域的研究。它支持多种流行的卡牌游戏环境,如21点、德州扑克、斗地主等,并提供简单易用的接口来实现各种强化学习和搜索算法。RLCard的目标是搭建起强化学习与不完全信息博弈之间的桥梁,推动这一领域的研究发展。
主要特点
RLCard具有以下几个主要特点:
-
支持多种卡牌游戏环境:包括21点、德州扑克、斗地主、麻将、UNO等流行卡牌游戏。
-
提供易用的接口:可以方便地实现各种强化学习算法,如DQN、NFSP、CFR等。
-
内置多种算法:提供了一些常用算法的实现,如Deep Monte-Carlo (DMC)、Deep Q-Learning (DQN)等。
-
预训练模型:提供了一些预训练好的模型,可以直接使用。
-
规则模型:内置了一些基于规则的模型,可以作为基线。
-
灵活的环境配置:可以通过配置来调整游戏参数。
-
支持多进程:可以利用多进程加速训练。
支持的游戏环境
RLCard目前支持以下几种卡牌游戏环境:
- 21点(Blackjack)
- 勒杜克扑克(Leduc Hold'em)
- 限注德州扑克(Limit Texas Hold'em)
- 无限注德州扑克(No-limit Texas Hold'em)
- 斗地主(Dou Dizhu)
- 麻将(Mahjong)
- UNO
- 金拉米(Gin Rummy)
- 桥牌(Bridge)
这些游戏环境涵盖了从简单到复杂的不同难度级别,信息集大小从10^3到10^163不等,为研究人员提供了丰富的实验平台。
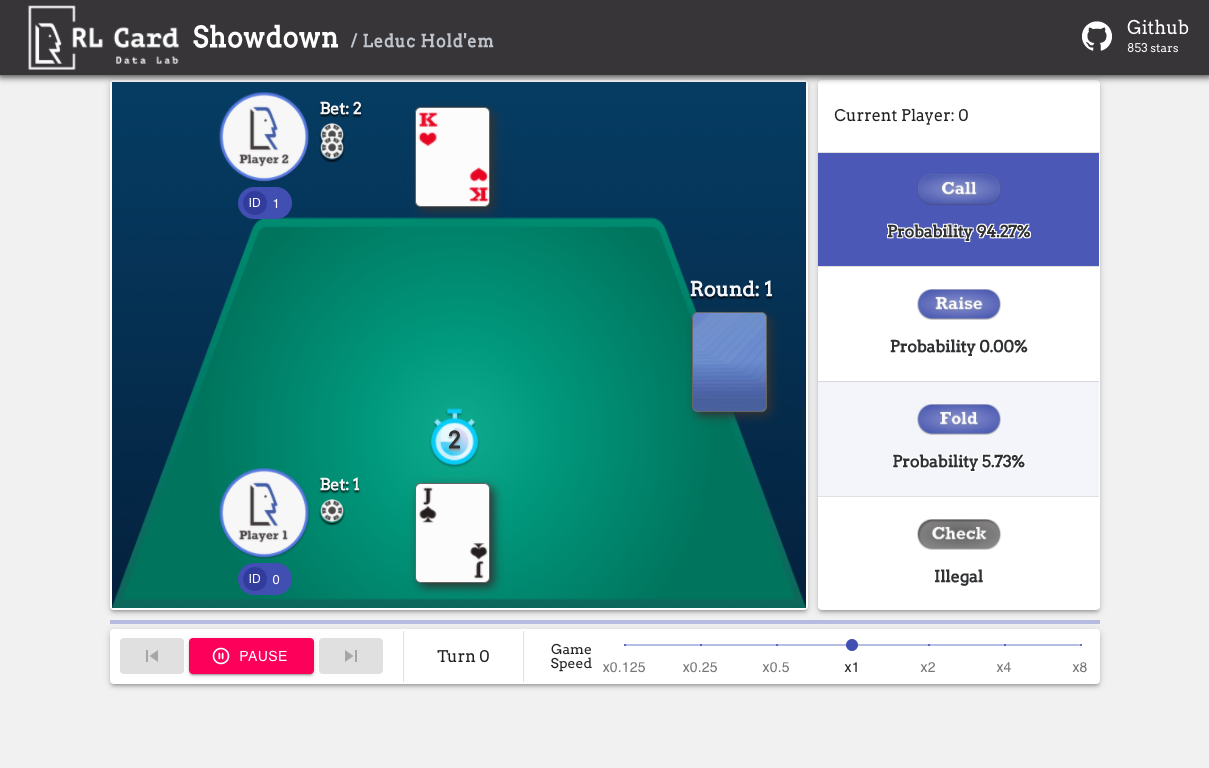
使用示例
下面是一个使用RLCard的简单示例:
import rlcard
from rlcard.agents import RandomAgent
env = rlcard.make('blackjack')
env.set_agents([RandomAgent(num_actions=env.num_actions)])
print(env.num_actions) # 2
print(env.num_players) # 1
print(env.state_shape) # [[2]]
print(env.action_shape) # [None]
trajectories, payoffs = env.run()
这个例子展示了如何创建一个21点游戏环境,设置一个随机智能体,并运行游戏。RLCard提供了灵活的接口,可以方便地与各种强化学习算法结合使用。
内置算法
RLCard内置了以下几种常用的强化学习算法:
- Deep Monte-Carlo (DMC)
- Deep Q-Learning (DQN)
- Neural Fictitious Self-Play (NFSP)
- Counterfactual Regret Minimization (CFR)
研究人员可以直接使用这些算法,也可以基于RLCard的接口实现自己的算法。
预训练模型和规则模型
RLCard还提供了一些预训练好的模型和基于规则的模型,可以直接使用或作为基线:
- leduc-holdem-cfr: 在Leduc Hold'em上预训练的CFR模型
- leduc-holdem-rule-v1/v2: Leduc Hold'em的规则模型
- uno-rule-v1: UNO的规则模型
- limit-holdem-rule-v1: 限注德州扑克的规则模型
- doudizhu-rule-v1: 斗地主的规则模型
- gin-rummy-novice-rule: 金拉米的新手规则模型
这些模型为研究人员提供了很好的起点和比较基准。
安装和使用
RLCard可以通过pip轻松安装:
pip install rlcard
如果需要使用PyTorch实现的训练算法,可以安装:
pip install rlcard[torch]
RLCard提供了详细的文档和教程,可以帮助用户快速上手。项目的GitHub仓库中还有许多示例代码,展示了如何使用RLCard实现各种算法和实验。
总结
RLCard为卡牌游戏领域的强化学习研究提供了一个强大而灵活的工具包。它支持多种流行的卡牌游戏环境,提供了易用的接口,内置了常用算法,并提供了预训练模型等丰富资源。无论是刚接触强化学习的新手,还是该领域的资深研究人员,都可以利用RLCard来进行各种实验和研究。随着不断的更新和社区贡献,RLCard正在成为推动卡牌游戏强化学习研究的重要平台。










