RLHF:让AI更懂人类偏好的关键技术
近年来,大型语言模型(LLM)在生成人类语言方面取得了令人瞩目的进展。然而,如何让AI生成的内容更符合人类的偏好和价值观,一直是一个巨大的挑战。RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)技术的出现,为解决这一问题提供了一个强有力的工具。本文将深入探讨RLHF的工作原理、应用场景以及最新进展。
RLHF的核心思想
RLHF的核心思想是将人类反馈融入到强化学习的过程中,通过构建奖励模型来优化语言模型的输出。这种方法可以让AI系统更好地理解和满足人类的偏好,生成更加自然、友好和符合道德规范的内容。
RLHF的训练过程通常包括以下几个关键步骤:
- 预训练语言模型
- 收集人类反馈数据并训练奖励模型
- 使用强化学习算法微调语言模型
让我们逐一深入了解这些步骤。
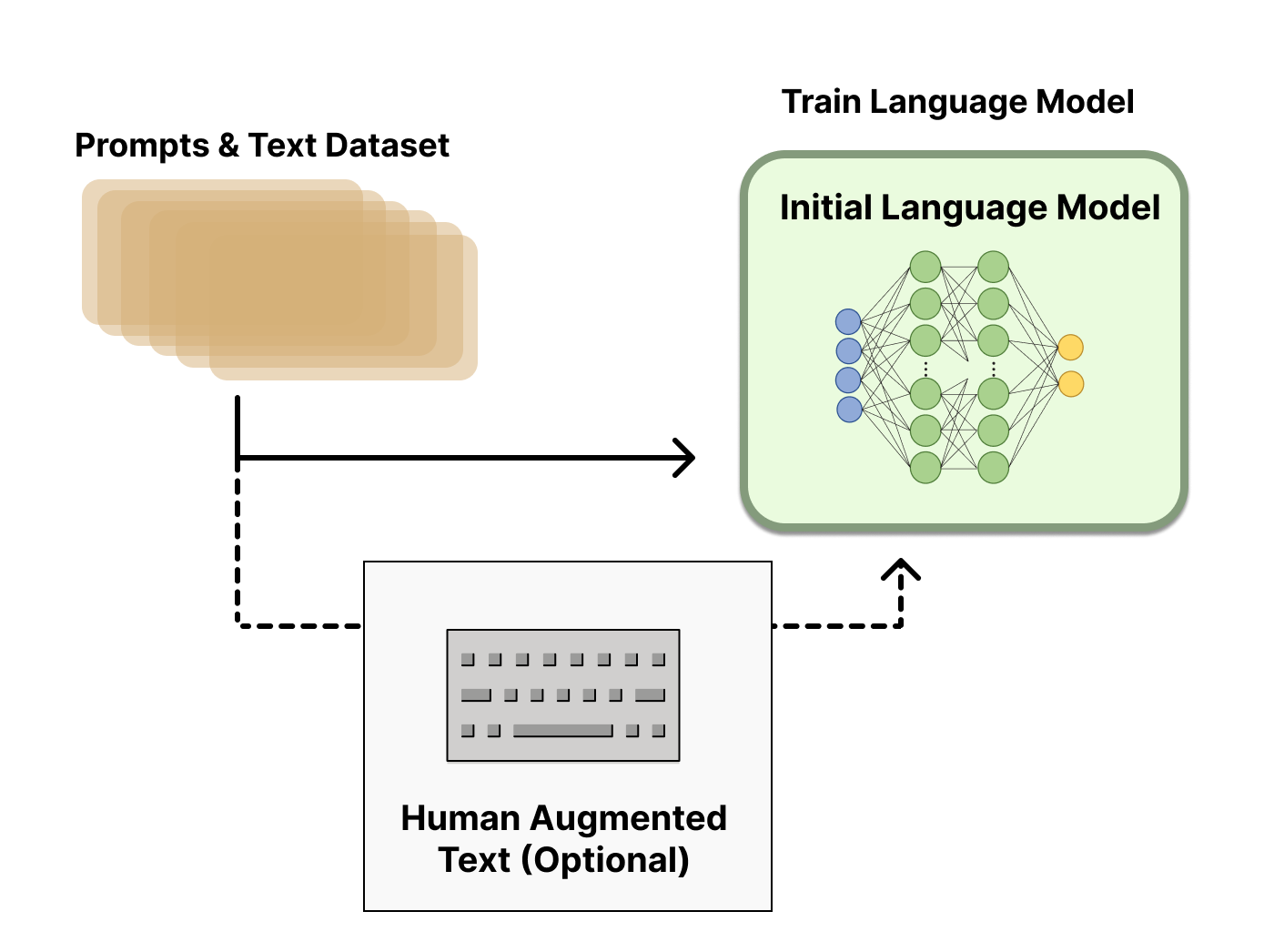
步骤一:预训练语言模型
RLHF的起点是一个预训练好的大型语言模型。这个模型通常是在海量文本数据上训练得到的,具备强大的语言理解和生成能力。例如,OpenAI的InstructGPT使用了GPT-3的一个较小版本作为起点,而Anthropic则使用了从1000万到520亿参数不等的Transformer模型。
预训练模型的选择对RLHF的效果有重要影响,但目前还没有明确的最佳选择。关键是要选择一个能够很好地响应多样化指令的模型。
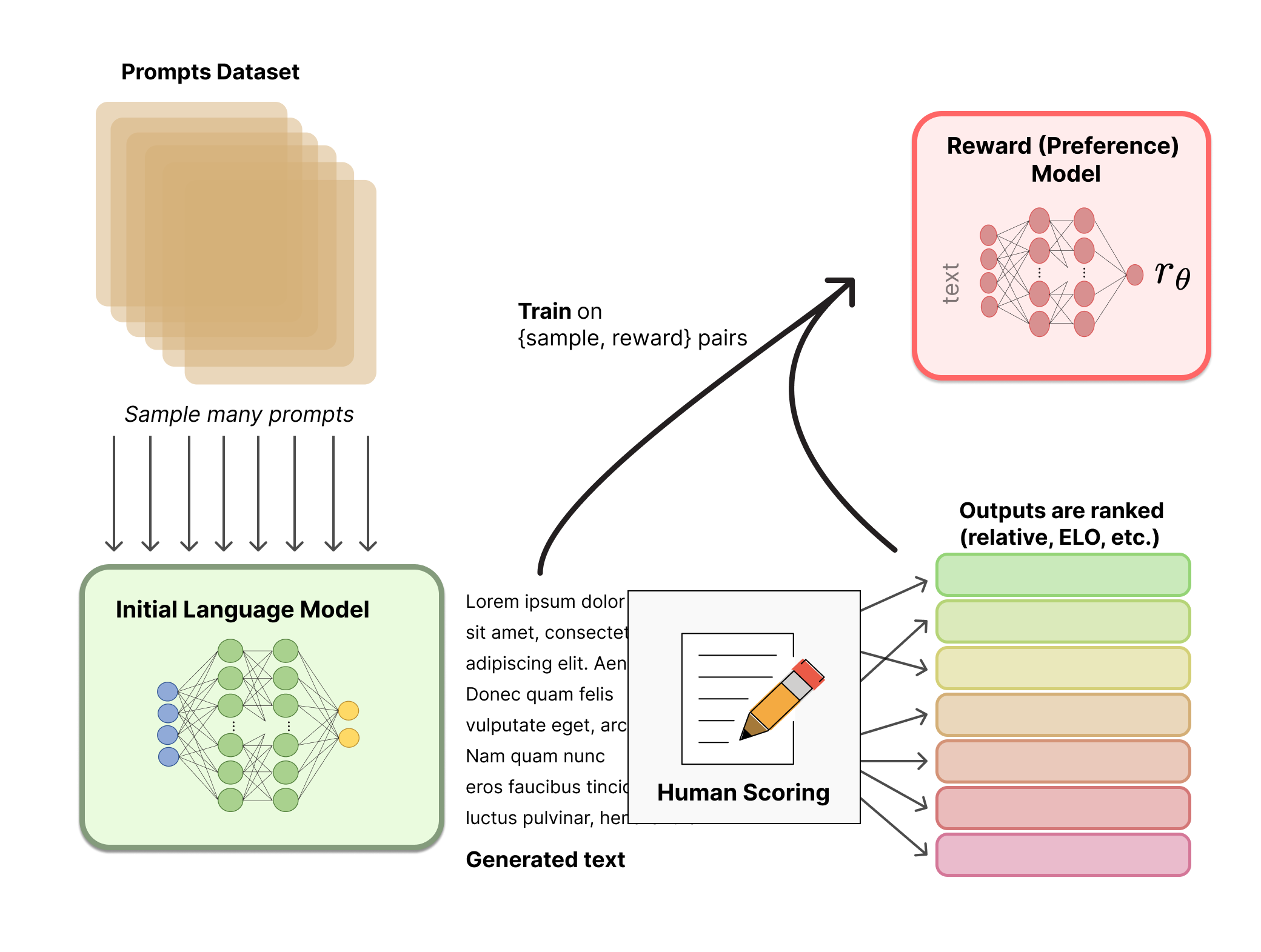
步骤二:收集人类反馈数据并训练奖励模型
这是RLHF中最具创新性的部分。研究人员需要收集大量的人类偏好数据,然后用这些数据训练一个奖励模型(Reward Model, RM)。
具体来说,过程如下:
- 从预定义的数据集中采样一组提示(prompts)。
- 将这些提示输入预训练的语言模型,生成多个不同的输出。
- 让人类标注者对这些输出进行排序,评判哪些输出更符合人类偏好。
- 使用这些排序数据训练奖励模型,使其能够为任意文本输出一个标量奖励值。
值得注意的是,直接让人类为每个输出打分是很困难的,因为不同人的评分标准可能差异很大。相比之下,让人类比较两个输出哪个更好要容易得多,而且结果更加一致。因此,许多RLHF系统采用了类似于Elo评分系统的方法来生成相对排名。
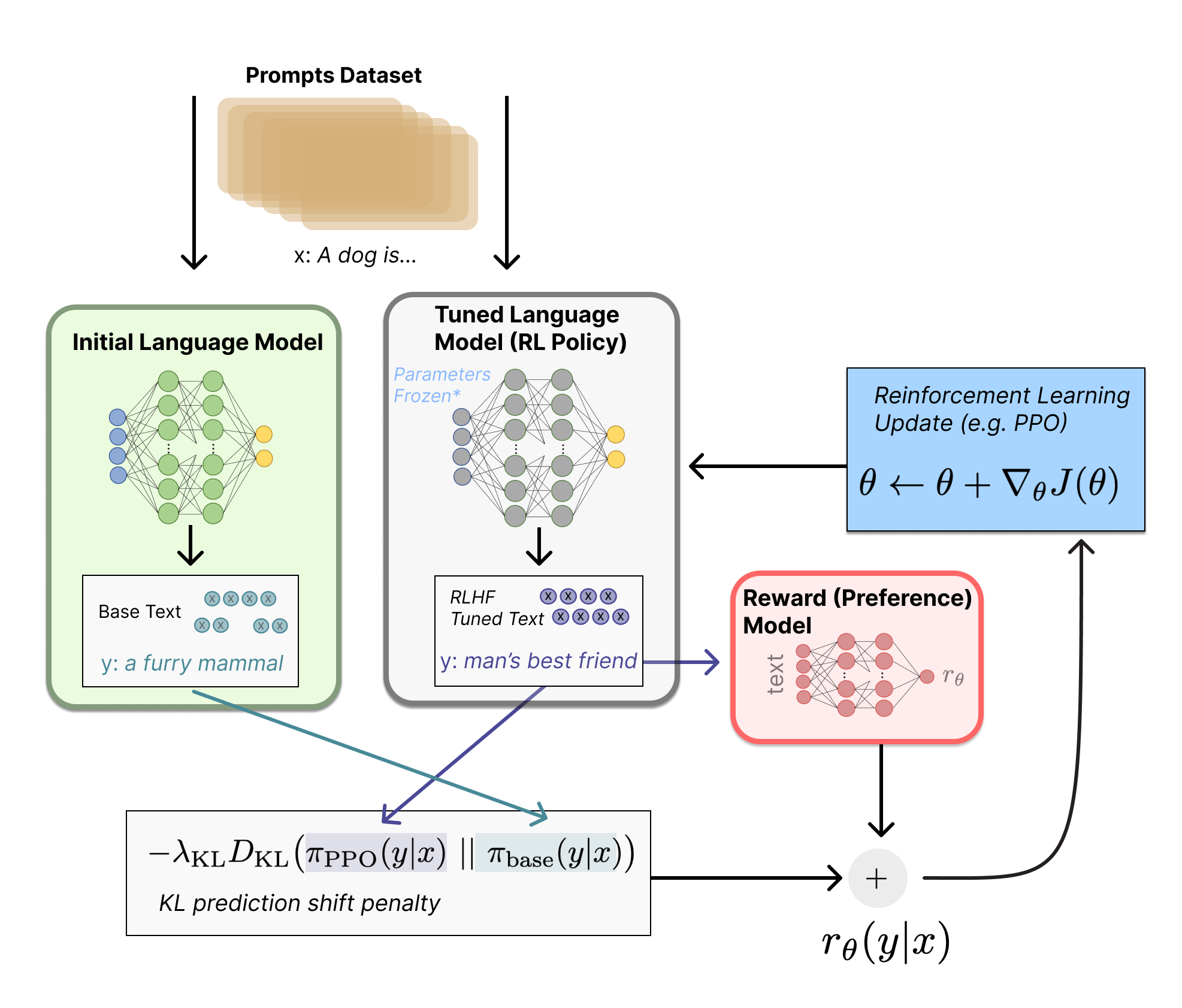
步骤三:使用强化学习算法微调语言模型
有了奖励模型后,我们就可以使用强化学习算法来微调原始的语言模型了。这个过程通常使用近端策略优化(Proximal Policy Optimization, PPO)算法。
在这个阶段,我们将语言模型视为一个策略(policy),它接收一个提示作为输入,输出一段文本。我们的目标是优化这个策略,使其生成的文本能够获得更高的奖励值。
具体来说,对于每个输入提示,我们会:
- 使用当前的语言模型生成一段文本。
- 将这段文本输入奖励模型,得到一个奖励值。
- 同时计算新旧语言模型输出的KL散度,作为一个额外的惩罚项。
- 使用PPO算法更新语言模型的参数,以最大化奖励并控制模型的变化幅度。
这个过程会不断重复,直到模型收敛或达到预设的迭代次数。
RLHF的应用场景
RLHF技术在多个领域展现出了巨大的潜力:
-
对话系统: RLHF可以帮助聊天机器人生成更加自然、友好和有帮助的回复。ChatGPT的成功就是一个典型例子。
-
内容生成: 在写作助手、代码生成等应用中,RLHF可以帮助AI生成更符合人类偏好和质量要求的内容。
-
信息检索: 在问答系统中,RLHF可以帮助模型生成更准确、更有价值的答案,并提供适当的引用。
-
安全性和道德性: RLHF可以帮助AI系统避免生成有害、不当或具有偏见的内容,提高AI的安全性和道德水平。
-
个性化: 通过收集特定用户或群体的反馈,RLHF可以帮助AI系统更好地适应不同用户的偏好和需求。
RLHF的最新进展
RLHF技术正在快速发展,一些最新的研究方向包括:
-
多目标奖励建模: 例如ArmoRM提出了一种基于多目标奖励建模和专家混合的方法,可以更好地解释和控制AI的行为。
-
迭代式RLHF: 一些研究探索了如何在模型部署后持续收集用户反馈,不断优化模型。
-
离线RLHF: 为了提高训练效率,研究人员正在探索如何使用离线强化学习算法来优化语言模型。
-
探索与利用的平衡: 如何在RLHF过程中更好地平衡探索新的行为和利用已知的好行为,是一个重要的研究方向。
-
大规模RLHF: 随着语言模型规模的不断增大,如何在更大规模的模型上高效地实施RLHF也成为一个重要课题。
RLHF的挑战与局限性
尽管RLHF取得了显著的成果,但它仍然面临一些挑战:
-
数据质量: RLHF的效果很大程度上依赖于人类反馈数据的质量。如何确保反馈数据的多样性、一致性和代表性是一个重要问题。
-
计算成本: RLHF的训练过程计算量很大,特别是对于大型语言模型来说,这可能会限制其应用范围。
-
过度优化: 如果不加以控制,RLHF可能会导致模型过度优化某些特定指标,而忽视其他重要的方面。
-
伦理问题: 如何确保RLHF不会被用来强化有害或不道德的行为,是一个需要认真考虑的问题。
-
泛化能力: 在特定任务上训练的RLHF模型可能难以泛化到其他领域或任务。
结语
RLHF作为一种将人类价值观和偏好融入AI系统的技术,正在深刻地改变我们与AI交互的方式。它为解决AI对齐问题提供了一个有力的工具,有望帮助我们创造出更加智能、友好和负责任的AI系统。
然而,RLHF并非万能良药。它的成功应用需要我们在技术、伦理和社会层面上进行深入的思考和探索。随着研究的不断深入,我们有理由相信,RLHF将在未来的AI发展中发挥越来越重要的作用。
参考资源
对于想要深入了解RLHF的读者,以下是一些有价值的资源:
通过不断学习和实践,我们可以更好地理解和应用RLHF技术,为创造更加智能和友好的AI系统贡献自己的力量。


















