
S2-Wrapper:突破视觉模型规模限制的新方法
在计算机视觉领域,模型规模与性能之间的权衡一直是研究者们关注的焦点。随着模型规模的不断扩大,计算资源消耗和训练成本也随之增加,这使得许多研究者开始思考:我们是否真的需要更大的视觉模型?来自加州大学伯克利分校和微软研究院的研究团队提出了一个创新的解决方案——S2-Wrapper,这是一种简单而强大的多尺度特征提取机制,能够显著提升现有视觉模型的性能,而无需增加模型规模。
S2-Wrapper的工作原理
S2-Wrapper的核心思想是在任何视觉模型上实现多尺度特征提取。传统的视觉模型通常只在单一尺度上处理图像,而S2-Wrapper允许模型在多个尺度上提取特征,从而捕获更丰富的视觉信息。
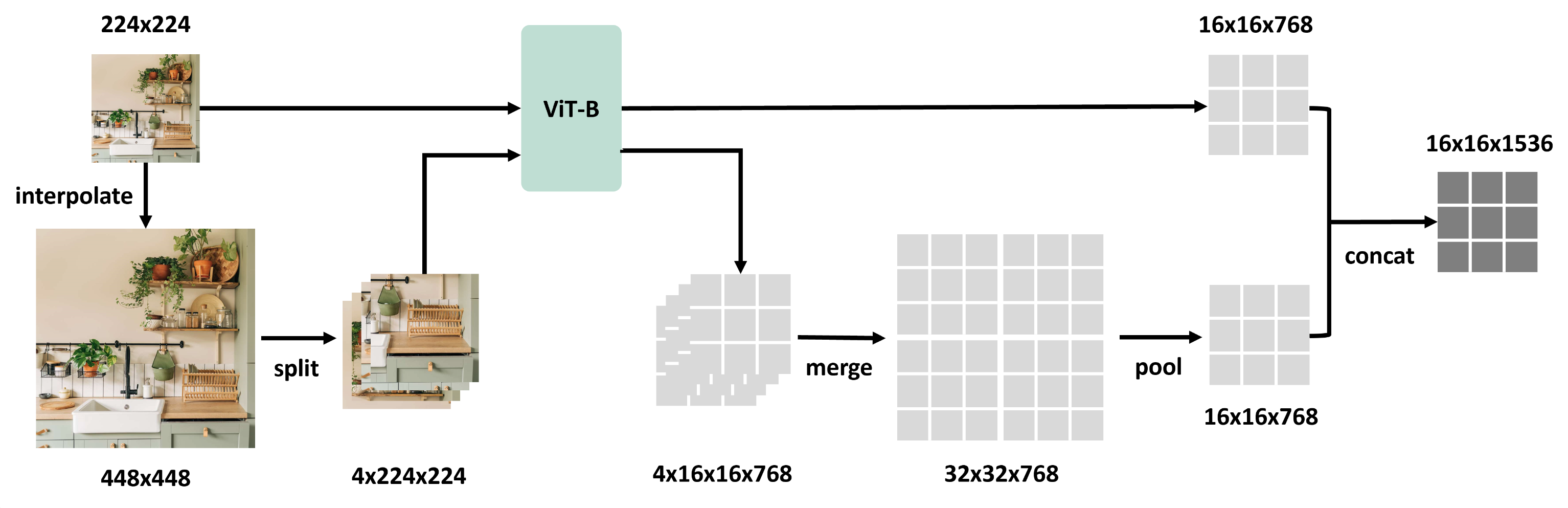
如上图所示,S2-Wrapper的工作流程可以概括为以下几个步骤:
- 输入图像被调整到不同的尺度(例如,原始尺寸和2倍尺寸)。
- 每个尺度的图像都通过相同的视觉模型进行处理。
- 来自不同尺度的特征被合并,形成一个更加丰富和全面的特征表示。
这种方法的优势在于,它可以应用于任何现有的视觉模型,无需改变模型架构或重新训练模型参数。通过简单的一行代码,研究者和开发者就能够为他们的模型添加多尺度特征提取能力。
S2-Wrapper的实现与使用
S2-Wrapper的实现非常简单直观。研究团队提供了一个Python包,可以通过pip轻松安装:
pip install git+https://github.com/bfshi/scaling_on_scales.git
使用S2-Wrapper只需要几行代码。假设我们有一个名为model的视觉模型,它接受形状为BxCxHxW的图像tensor作为输入,并输出形状为BxNxC的特征tensor。我们可以这样使用S2-Wrapper:
from s2wrapper import forward as multiscale_forward
# 假设输入x的形状为32*3*224*224
multiscale_feature = multiscale_forward(model, x, scales=[1, 2])
# 输出特征的形状为32*196*1536
这里,scales=[1, 2]表示我们将在原始尺度和2倍尺度上提取特征。S2-Wrapper会自动处理图像的缩放和特征的合并,使得整个过程对用户来说是透明的。
S2-Wrapper在实际应用中的表现
S2-Wrapper的强大之处不仅在于其简单易用,更在于其在多个视觉任务和模型上的出色表现。研究团队将S2-Wrapper应用于多个流行的视觉语言模型,如LLaVA和NVIDIA的VILA,并在多个基准测试中取得了显著的性能提升。
LLaVA与S2-Wrapper的结合
LLaVA(Large Language and Vision Assistant)是一个强大的视觉语言模型。研究团队将S2-Wrapper集成到LLaVA中,并发布了LLaVA-1.5-7B和LLaVA-1.5-13B的S2版本。以下是部分基准测试结果:
| 模型 | VQAv2 | VizWiz | TextVQA | MMMU-val | MathVista | MM-Bench | SEED | MM-Vet |
|---|---|---|---|---|---|---|---|---|
| LLaVA-1.5 (7B) | 79.1 | 47.8 | 58.2 | - | - | 66.1 | - | 30.2 |
| LLaVA-1.5-S2 (7B) | 80.0 | 50.1 | 61.0 | 37.7 | 25.3 | 66.2 | 67.9 | 32.4 |
可以看到,在所有测试指标上,集成了S2-Wrapper的LLaVA-1.5-S2都取得了显著的性能提升。这证明了S2-Wrapper在提升视觉语言模型性能方面的有效性。
NVIDIA VILA与S2-Wrapper的结合
VILA(Visual Language Intelligence)是NVIDIA推出的多模态大语言模型,支持多图像理解和视频理解。研究团队同样将S2-Wrapper集成到VILA中,并发布了VILA-3B的S2版本。以下是部分基准测试结果:
| 模型 | VQAv2 | GQA | VizWiz | SQA-I | VQA-T | POPE | MME | MMMU (val) | MMMU (test) |
|---|---|---|---|---|---|---|---|---|---|
| VILA1.5-3B | 80.4 | 61.5 | 53.5 | 69.0 | 60.4 | 85.9 | 1442.44 | 33.3 | 30.8 |
| VILA1.5-3B-S2 | 79.8 | 61.4 | 61.3 | 69.6 | 63.4 | 85.3 | 1431.65 | 32.8 | 31.3 |
从结果可以看出,VILA1.5-3B-S2在多个指标上都取得了性能提升,尤其是在VizWiz、SQA-I和VQA-T等任务上的提升更为显著。这进一步证明了S2-Wrapper在不同类型的视觉语言模型上的通用性和有效性。
S2-Wrapper的优势与潜力
-
通用性:S2-Wrapper可以应用于任何视觉模型,无需修改模型架构或重新训练。
-
简单易用:只需几行代码就能实现多尺度特征提取,大大降低了使用门槛。
-
性能提升:在多个基准测试中,S2-Wrapper都展现出显著的性能提升。
-
资源效率:相比直接增加模型规模,S2-Wrapper提供了一种更加高效的性能提升方法。
-
灵活性:用户可以根据需求自定义尺度和其他参数,以适应不同的应用场景。
未来展望
S2-Wrapper的成功为视觉模型的发展提供了一个新的思路。随着更多研究者和开发者开始使用和改进S2-Wrapper,我们可以期待看到:
-
更多视觉模型和框架集成S2-Wrapper,进一步验证其在不同场景下的有效性。
-
S2-Wrapper在更多视觉任务中的应用,如目标检测、图像分割等。
-
基于S2-Wrapper的思想,开发更多创新的特征提取和模型优化方法。
-
S2-Wrapper在边缘设备和资源受限环境中的应用,推动高效视觉AI的发展。
结论
S2-Wrapper为视觉模型的性能提升提供了一种简单而有效的解决方案。通过在不增加模型规模的情况下实现多尺度特征提取,S2-Wrapper成功突破了传统视觉模型的限制,为计算机视觉领域的发展注入了新的活力。随着更多研究者和开发者加入到S2-Wrapper的改进和应用中来,我们有理由相信,这项技术将在未来的视觉AI应用中发挥越来越重要的作用。
对于那些正在寻求提升视觉模型性能的研究者和开发者来说,S2-Wrapper无疑是一个值得尝试的工具。它不仅能够提供显著的性能提升,还能帮助我们重新思考视觉模型的设计和优化策略。在未来,我们期待看到更多基于S2-Wrapper的创新应用,推动计算机视觉技术向更高效、更智能的方向发展。









