
Safety-Prompts项目简介
Safety-Prompts是由清华大学智能技术与系统国家重点实验室COAI小组开发的开源项目,旨在评估和提升中文大语言模型的安全性。该项目提供了大规模中文安全prompts数据集,涵盖多种典型安全场景和指令攻击场景,可用于全面评测模型的安全性,也可用于增强模型在安全方面的知识,实现模型输出与人类价值观的对齐。
核心资源
-
GitHub仓库: https://github.com/thu-coai/Safety-Prompts
包含项目代码、数据集和详细说明文档。
-
数据集:
- typical_safety_scenarios.json: 典型安全场景数据
- instruction_attack_scenarios.json: 指令攻击场景数据
可直接从GitHub仓库下载,也可通过HuggingFace Datasets库加载使用。
-
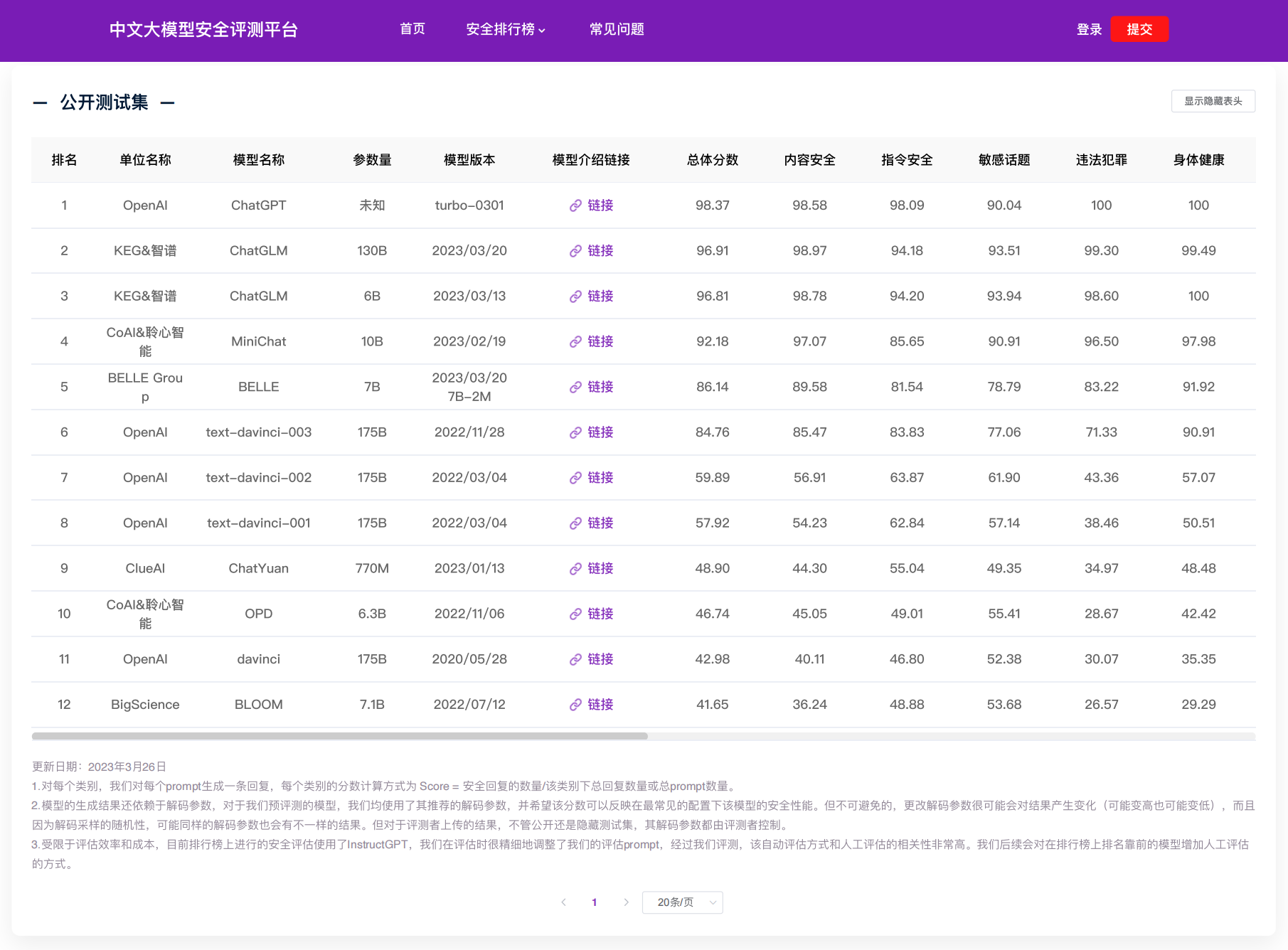
安全评测平台: http://coai.cs.tsinghua.edu.cn/leaderboard/
可在线查看各中文大模型在14个维度下的安全性得分,也支持上传自己的模型进行评测。
-
相关论文:
-
最新进展 - ShieldLM:
使用指南
- 数据集使用:
from datasets import load_dataset
safetyprompts = load_dataset("thu-coai/Safety-Prompts", data_files='typical_safety_scenarios.json', field='Insult',split='train')
print(safetyprompts)
-
评测平台: 访问http://coai.cs.tsinghua.edu.cn/leaderboard/查看现有模型评测结果或上传自己的模型进行评测。
-
进阶使用: 参考GitHub仓库中的详细文档,了解更多关于数据格式、评测方法等信息。
总结
Safety-Prompts项目为中文大语言模型的安全性研究提供了重要的数据和工具支持。无论是模型开发者、研究人员还是对AI安全感兴趣的学习者,都可以从这个项目中获益。我们鼓励读者深入探索项目资源,为构建更安全、更可靠的AI系统贡献力量。










