SCOPE-RL简介
SCOPE-RL是一个开源的Python库,专门用于离线强化学习(Offline Reinforcement Learning, Offline RL)的研究与应用。它提供了一整套工具,可以实现从数据收集到离线策略学习、离线性能评估和策略选择的完整流程。
SCOPE-RL的主要特点包括:
- 端到端实现离线RL和离线策略评估(Off-Policy Evaluation, OPE)
- 提供多种OPE估计器和标准化的OPE评估协议
- 支持累积分布OPE,用于风险函数估计
- 验证OPS在部署糟糕策略时的潜在风险
该库的设计目标是使离线RL的实验更加容易、透明和可靠。它不仅适用于任何具有OpenAI Gym和Gymnasium类接口的环境,还可以方便地在各种自定义数据集和真实世界数据集上实施离线RL。
主要功能
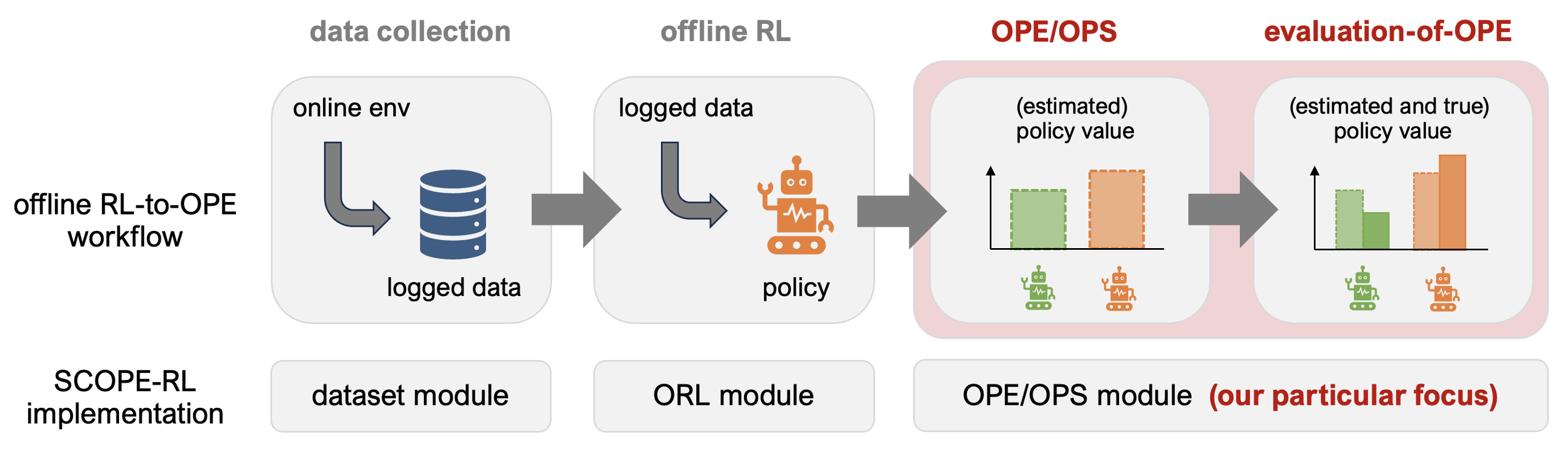
SCOPE-RL主要由以下三个模块组成:
-
数据集模块: 提供工具生成基于OpenAI Gym和Gymnasium接口的任何环境的合成数据,并对日志数据进行预处理。
-
策略模块: 提供d3rlpy的包装类,实现灵活的数据收集。
-
OPE模块: 提供通用的抽象类来实现OPE估计器,并提供一些用于执行离线策略选择(Off-Policy Selection, OPS)的工具。
SCOPE-RL支持多种行为策略、OPE估计器和OPS准则,为研究人员提供了丰富的选择。同时,它还实现了多种评估OPS的指标,如均方误差、Spearman秩相关系数、遗憾等。
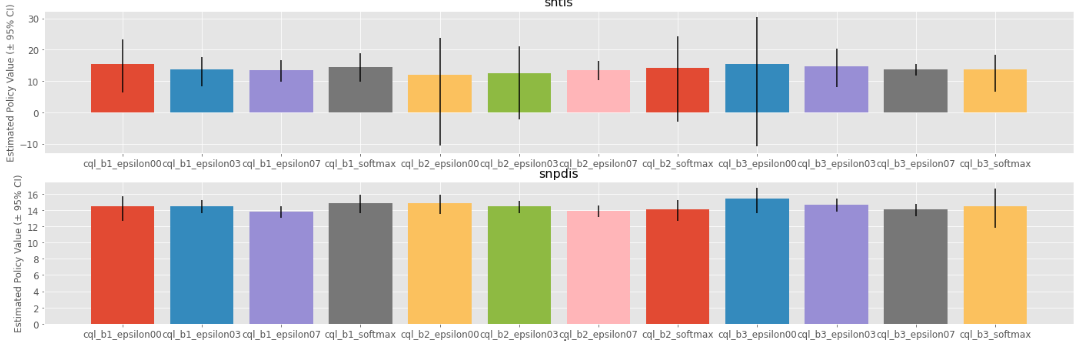
使用示例
以下是使用SCOPE-RL进行基本离线策略评估的简单示例:
# 初始化OPE类
ope = OPE(
logged_dataset=logged_dataset,
ope_estimators=[DM(), TIS(), PDIS(), DR()],
)
# 执行OPE并可视化结果
ope.visualize_off_policy_estimates(
input_dict,
random_state=random_state,
sharey=True,
)
这段代码将使用多种OPE估计器(直接法、轨迹重要性采样、每次决策重要性采样和双重鲁棒)评估策略性能,并生成可视化结果。
SCOPE-RL还支持更高级的功能,如累积分布函数估计:
# 初始化累积分布OPE类
cd_ope = CumulativeDistributionOPE(
logged_dataset=logged_dataset,
ope_estimators=[
CD_DM(estimator_name="cdf_dm"),
CD_IS(estimator_name="cdf_is"),
CD_DR(estimator_name="cdf_dr"),
CD_SNIS(estimator_name="cdf_snis"),
CD_SNDR(estimator_name="cdf_sndr"),
],
)
# 估计并可视化累积分布函数
cd_ope.visualize_cumulative_distribution_function(input_dict, n_cols=4)

高级功能
除了基本的OPE,SCOPE-RL还提供了许多高级功能:
-
离线策略选择: 可以基于OPE结果从候选策略集中选择最佳表现的策略。
-
OPE/OPS评估: 提供了多种指标来评估OPE和OPS的可靠性,如均方误差、秩相关、遗憾等。
-
风险评估: 可以估计策略的方差、条件风险价值(CVaR)等风险指标。
-
自定义环境支持: 提供了RTBGym和RecGym,分别用于实时竞价(RTB)和推荐系统的RL环境。
这些功能使SCOPE-RL成为一个全面的离线RL研究和应用工具。
项目贡献
SCOPE-RL欢迎任何形式的贡献。如果您对该项目感兴趣,可以通过以下方式参与:
- 访问GitHub仓库
- 阅读贡献指南
- 加入Google Group讨论
总结
SCOPE-RL为离线强化学习的研究和应用提供了一个强大而灵活的工具。无论是学术研究还是实际应用,它都能满足用户在离线RL、OPE和OPS方面的各种需求。随着离线RL在工业界的日益普及,SCOPE-RL有望成为这一领域的重要工具之一。









