Semantra: 一款强大的语义搜索工具
 Ray
RaySemantra:革新文档搜索体验的语义搜索利器
在这个信息爆炸的时代,如何从海量文档中快速精准地找到所需信息已经成为一个普遍的挑战。传统的关键词搜索往往难以满足复杂的查询需求,而新兴的语义搜索技术则为解决这一难题带来了新的可能。近期,一款名为Semantra的开源语义搜索工具引起了广泛关注,它为用户提供了一种全新的文档搜索体验。
Semantra的核心功能与特点
Semantra是一款多功能的语义搜索工具,其核心功能是通过理解查询的语义含义来搜索文档,而不仅仅依赖于简单的文本匹配。它可以分析用户本地计算机上的文本和PDF文件,并启动一个本地Web搜索应用程序,让用户能够交互式地查询这些文档。
Semantra的主要特点包括:
-
语义搜索:通过理解查询的含义而非仅依赖关键词匹配来搜索文档。
-
本地化:在用户本地计算机上运行,确保数据隐私和安全。
-
灵活配置:支持多种嵌入模型,用户可以根据需求选择合适的模型。
-
交互式界面:提供友好的Web界面,支持结果标记、查询修改等功能。
-
开源免费:代码完全开源,用户可以自由使用和定制。
Semantra的工作原理
Semantra的工作流程大致可以分为以下几个步骤:
-
文档处理:Semantra首先会分析用户指定的文本或PDF文件,将其分割成适当大小的文本块。
-
嵌入生成:使用选定的嵌入模型(如BERT、OpenAI等)将文本块转换为高维向量表示。
-
索引建立:基于生成的嵌入向量建立索引,以便快速检索。
-
查询处理:当用户输入查询时,同样将查询转换为向量表示��。
-
相似度计算:计算查询向量与文档向量的相似度,找出最相关的文本块。
-
结果展示:将相关度最高的结果呈现给用户,并提供进一步的交互操作选项。
这种基于语义的搜索方法使得Semantra能够理解查询的深层含义,从而找到表述不同但内容相关的文本,大大提高了搜索的准确性和全面性。
Semantra的应用场景
Semantra的设计初衷是为那些需要在大量文档中寻找"大海捞针"的人提供帮助。它的潜在用户群体包括:
- 记者:在处理大量泄露文件时,需要在截止日期前快速找到关键信息。
- 研究人员:在阅读大量论文时,需要寻找特定主题或观点的相关内容。
- 学生:在研究文学作品时,需要通过主题查询来深入理解文本。
- 历史学家:需要在多本书籍中连接相关的历史事件。
对于这些用户来说,Semantra提供了一种高效、准确的方式来探索和分析大量文本数据。
使用Semantra的基本流程
- 安装:Semantra是一个Python命令行工具,用户需要先安装Python(3.9或更高版本),然后通过pipx安装Semantra。
python3 -m pip install --user pipx python3 -m pipx ensurepath python3 -m pipx install semantra
- 运行:安装完成后,用户可以通过简单的命令来处理文档并启动搜索界面:
semantra report.pdf book.txt
- 搜索:Semantra会启动一个本地Web服务器(默认地址为localhost:8080),用户可以在浏览器中访问搜索界面,输入查询并查看结果。
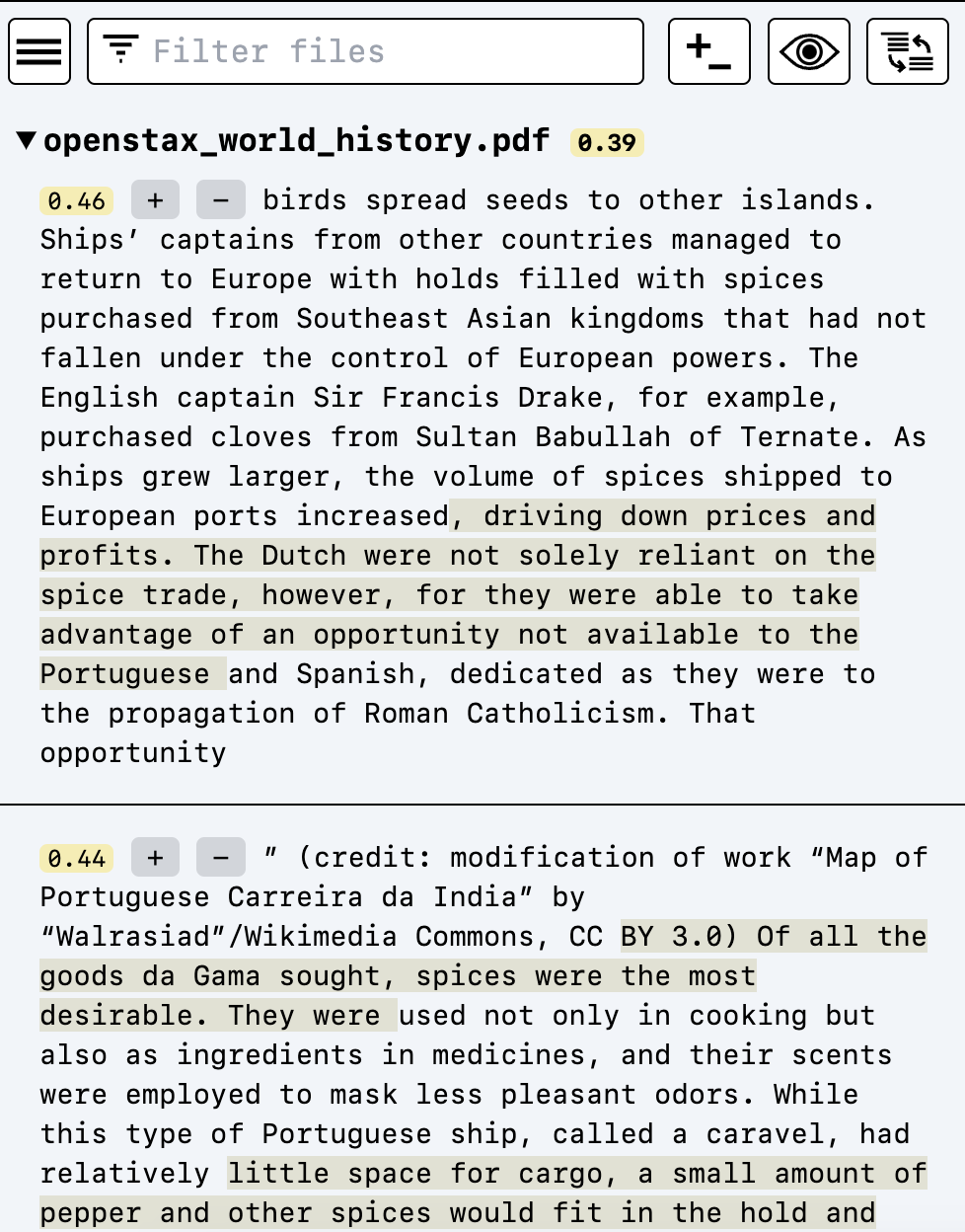
- 交互:用户可以通过点击结果来查看相关文档段落,还可以使用标记功�能来优化搜索结果。
Semantra的技术特性
-
多种嵌入模型:Semantra支持多种预设的嵌入模型,如OpenAI、MiniLM、MPNet等,用户可以根据需求选择合适的模型。
-
自定义窗口大小:用户可以自定义文档分割的窗口大小和重叠程度,以优化搜索效果。
-
近似K近邻搜索:Semantra默认使用Annoy库进行近似K近邻搜索,在保证准确性的同时提高查询速度。
-
SVM支持:除了K近邻搜索,Semantra还支持使用SVM进行查询,适用于某些特定场景。
-
结果解释:Semantra会自动高亮显示查询结果中最相关的文本部分,帮助用户快速理解匹配原因。
Semantra vs 传统搜索引擎
相比传统的基于关键词的搜索引擎,Semantra在以下几个方面具有明显优势:
-
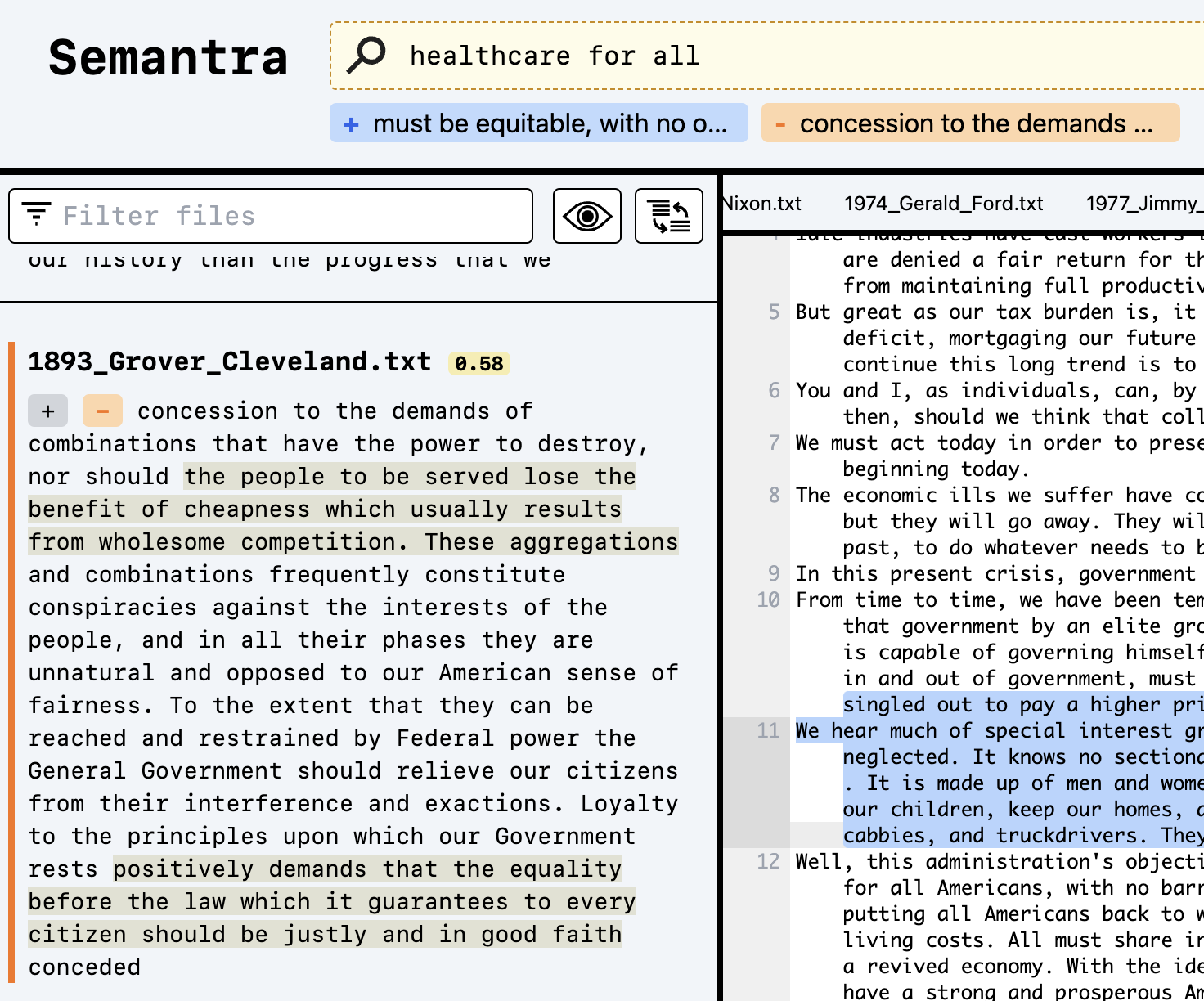
语义理解:Semantra能够理解查询的语义含义,而不仅仅是匹配关键词,这使得它能够找到表述不同但内容相关的结果。
-
灵活查询:用户可以使用自然语言进行查询,甚至可以通过加减查询词来精确控制搜索方向。
-
上下文感知:Semantra会考虑文本的上下文,因此能够更准确地理解词语在特定语境中的含义。
-
交互式优化:通过标记功能,用户可以迭代优化搜索结果,不断提高查询的精准度。
-
隐私保护:所有处理都在本地完成,无需将敏感文档上传到云端,保护了用户的数据隐私。
Semantra的局限性
尽管Semantra在语义搜索方面表现出色,但它也存在一些局限性:
-
计算资源需求:处理大量文档时可能需要较长时间和较大的存储空间,特别是在首次处理文档时。
-
学习曲线:相比简单的关键词搜索,使用Semantra可能需要用户学习一些新的概念和操作方法。
-
非实时更新:Semantra不支持实时索引新文档,每次添加新文档都需要重新处理。
-
语言模型依赖:搜索效果在很大程度上依赖于所使用的嵌入模型的质量。
Semantra的未来发展
作为一个开源项目,Semantra的发展潜力巨大。未来可能的改进方向包括:
-
支持更多文档格式:目前Semantra主要支持文本和PDF文件,未来可能会扩展到更多文件类型。
-
实时索引:开发增量索引功能,支持实时添加新文档。
-
多语言支持:增强对非英语文档的处理能力。
-
性能优化:提高大规模文档处理和查询的效率。
-
用户界面优化:开发更直观、功能更丰富的Web界面。
结语
Semantra为文档搜索带来了一种全新的范式,它将深度学习技术与传统信息检索方法相结合,为用户提供了一种强大而灵活的语义搜索工具。无论是专业研究人员还是普通用户,都可以借助Semantra来更高效地探索和分析大量文本数据。随着自然语言处理技术的不断进步,我们有理由期待Semantra及类似工具在未来会发挥越来越重要的作用,彻底改变人们获取和处理信息的方式。
对于那些经常需要在大量文档中查找特定信息的人来说,Semantra无疑是一个值得尝试的工具。它不仅能够提高工作效率,还能帮助用户发现传统搜索方法可能忽略的有价值信息。随着更多人参与到这个开源项目中来,我们期待看到Semantra在功能和性能上的进一步提升,为更广泛的用户群体带来便利。
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答��、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境�(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号