SheepRL: 分布式强化学习的新选择
在人工智能领域,强化学习一直是一个充满挑战和机遇的研究方向。随着算法和硬件的不断进步,如何高效实现和扩展强化学习算法成为了一个重要问题。SheepRL 应运而生,它是一个基于 Lightning Fabric 构建的分布式强化学习框架,旨在为研究人员和开发者提供一个易用、高效且可扩展的强化学习工具。
SheepRL 的核心特性
SheepRL 具有以下几个突出的特点:
-
丰富的算法支持: SheepRL 实现了多种经典的强化学习算法,包括 A2C、PPO、SAC、Dreamer 等,并支持这些算法的不同变体。
-
多种环境兼容: 框架支持 Gym、Atari、MuJoCo、DeepMind Control Suite 等多种常用环境,还包括 MineRL、MineDojo、DIAMBRA 等特殊环境。
-
分布式训练: 利用 Lightning Fabric 的能力,SheepRL 可以轻松实现分布式训练,提高算法的训练效率。
-
灵活的配置系统: 采用基于 Hydra 的配置系统,使得实验参数的管理和调整变得简单直观。
-
模块化设计: 算法实现采用模块化设计,便于扩展和定制。
-
性能优化: 框架在实现上注重性能,提供了与 Stable Baselines3 等知名框架相当甚至更优的训练速度。
快速上手 SheepRL
要开始使用 SheepRL,首先需要安装框架。SheepRL 提供了多种安装方式,以适应不同的需求:
-
直接从 PyPI 安装最新版本:
pip install sheeprl -
克隆 GitHub 仓库并安装:
git clone https://github.com/Eclectic-Sheep/sheeprl.git cd sheeprl pip install -e . -
使用 GitHub URL 安装:
pip install "sheeprl @ git+https://github.com/Eclectic-Sheep/sheeprl.git"
安装完成后,就可以开始训练你的第一个 SheepRL 智能体了。例如,要训练一个 PPO 智能体在 CartPole 环境中学习,只需运行以下命令:
sheeprl exp=ppo env=gym env.id=CartPole-v1
这个简单的命令就能启动一个完整的训练过程。SheepRL 会自动设置环境、初始化智能体、执行训练循环,并记录训练日志。
SheepRL 的核心组件
为了更好地理解 SheepRL 的工作原理,让我们深入了解一下框架的核心组件:
1. 算法实现
SheepRL 的算法实现遵循一种清晰的结构。每个算法通常包含以下文件:
<algorithm>.py: 算法的主要实现<algorithm>_decoupled.py: 算法的解耦版本实现(如果有)agent.py: 智能体的实现(可选)loss.py: 损失函数的实现utils.py: 算法相关的工具函数
这种结构使得算法的各个部分清晰可见,便于理解和修改。
2. 环境包装器
SheepRL 提供了多种环境包装器,用于处理不同类型的观察和动作空间。这些包装器位于 sheeprl/envs 目录下,可以轻松地应用于各种环境。
3. 数据缓冲区
数据缓冲区是强化学习算法中的重要组成部分。SheepRL 实现了多种缓冲区,如 ReplayBuffer、SequentialReplayBuffer 等,它们都基于 NumPy 数组,提供高效的数据存储和采样功能。
4. 模型构建块
在 sheeprl/models 目录下,SheepRL 提供了一些常用的神经网络构建块,如多层感知器(MLP)和卷积神经网络(CNN)。这些模块可以方便地组合,构建复杂的策略网络和价值网络。
深入理解 SheepRL 的工作流程
要充分利用 SheepRL 的强大功能,了解其工作流程是很有必要的。让我们以 PPO 算法为例,探讨 SheepRL 是如何组织训练过程的。
PPO 算法的实现
PPO(Proximal Policy Optimization)是一种流行的策略梯度算法。在 SheepRL 中,PPO 的实现分为两个版本:耦合版和解耦版。
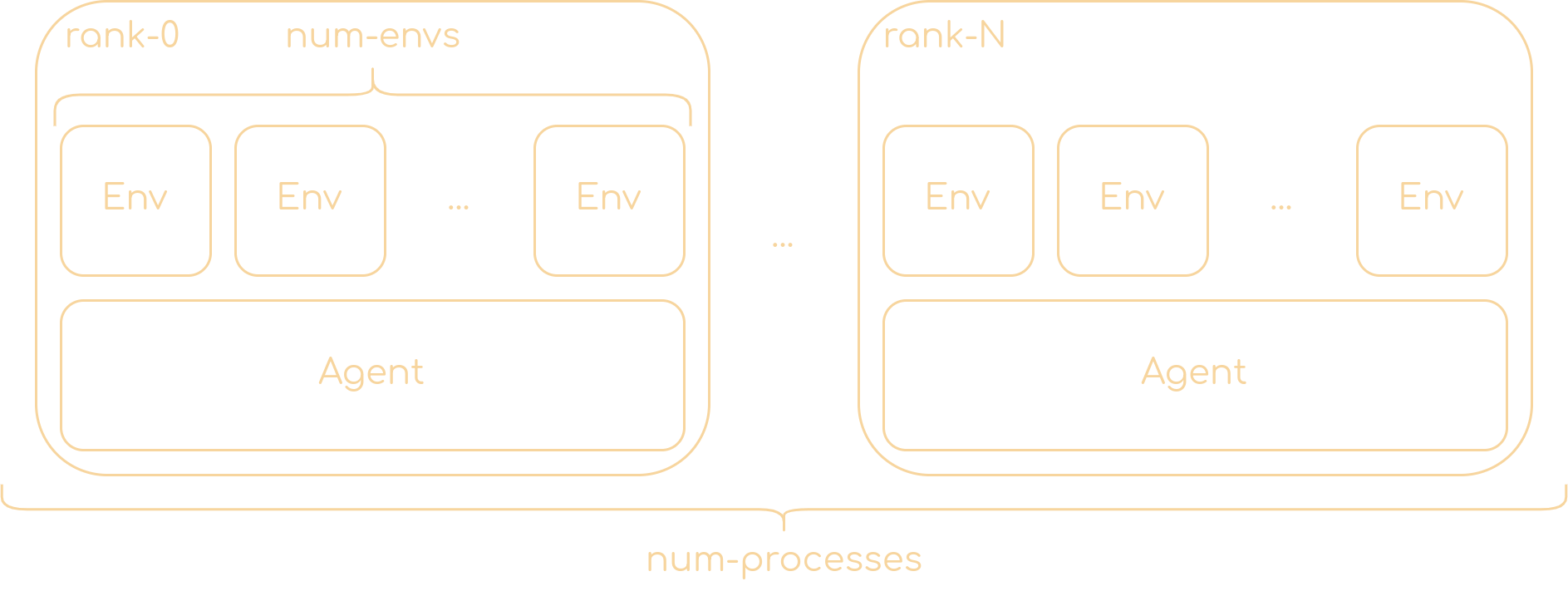
- 耦合版 PPO:
在耦合版中,环境交互和模型训练在同一个进程中进行。主要流程如下:
main()函数初始化环境、智能体和其他组件。- 在主循环中,智能体与环境交互,收集数据。
- 当收集到足够的数据后,调用
train()函数进行模型更新。
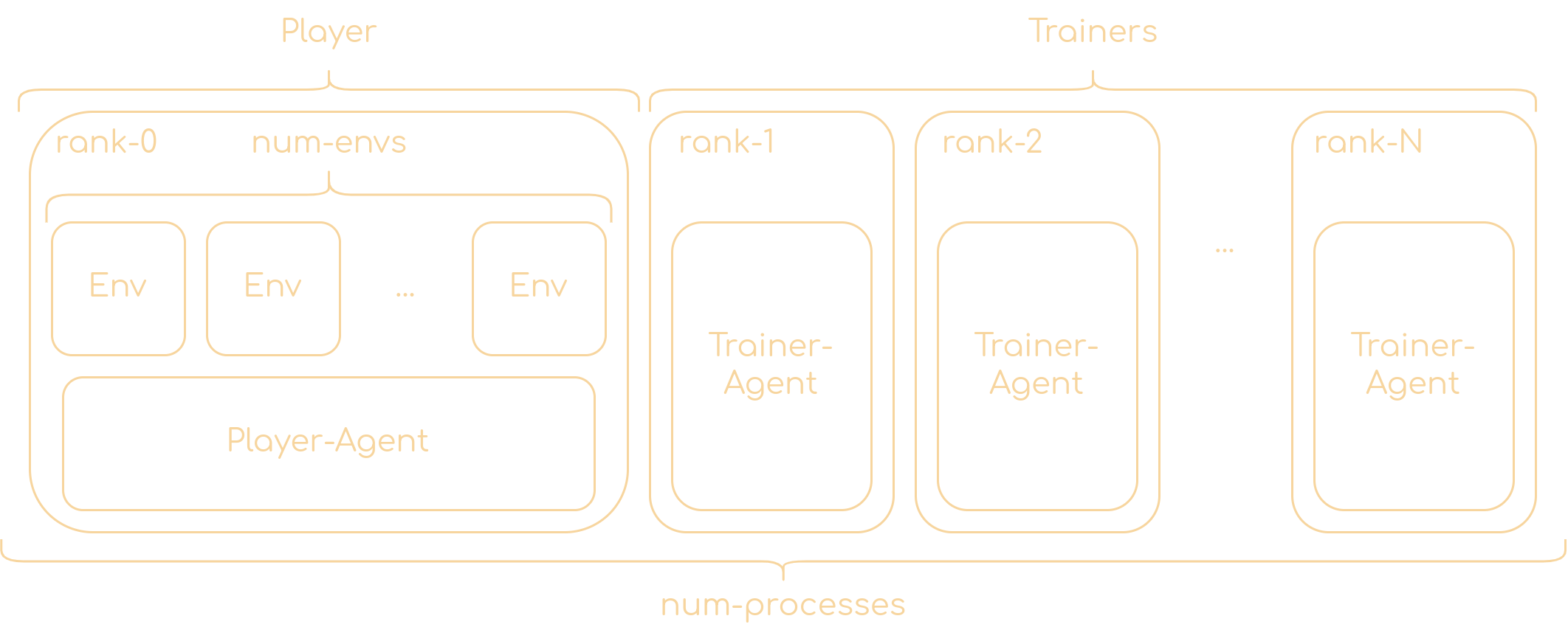
- 解耦版 PPO:
解耦版将环境交互和模型训练分离到不同的进程中,提高了并行性:
player()函数负责与环境交互,收集数据。trainer()函数负责模型训练。- 两个进程通过 Lightning Fabric 提供的分布式通信机制交换数据和模型参数。
这种设计允许更高效地利用计算资源,特别是在多 GPU 环境下。
配置系统
SheepRL 使用 Hydra 作为配置系统,这允许用户轻松地修改实验参数。配置文件位于 sheeprl/configs 目录下,包括算法特定的配置和通用配置。
例如,要修改 PPO 的学习率,可以在命令行中这样指定:
sheeprl exp=ppo env=gym env.id=CartPole-v1 algo.optimizer.lr=0.0001
这种灵活的配置系统使得实验调整变得非常方便。
日志记录和可视化
SheepRL 集成了 TensorBoard 用于训练过程的可视化。在训练过程中,各种指标如奖励、损失等都会被记录下来。训练完成后,可以使用以下命令查看训练曲线:
tensorboard --logdir logs
这为分析和调试提供了强大的支持。
SheepRL 的高级特性
除了基本的训练功能,SheepRL 还提供了一些高级特性,进一步增强了框架的实用性:
1. 分布式训练
SheepRL 借助 Lightning Fabric 的能力,可以轻松实现分布式训练。例如,要在两个 GPU 上运行 PPO 算法:
sheeprl fabric.accelerator=gpu fabric.strategy=ddp fabric.devices=2 exp=ppo env=gym env.id=CartPole-v1
这种分布式能力使得 SheepRL 能够处理大规模的强化学习任务。
2. 智能体评估
训练完成后,可以使用 sheeprl-eval 命令对智能体进行评估:
sheeprl-eval checkpoint_path=/path/to/checkpoint.ckpt fabric.accelerator=gpu env.capture_video=True
这个命令会加载训练好的模型,在环境中运行,并可选地录制视频。
3. 自定义环境和算法
SheepRL 的模块化设计使得添加新的环境和算法变得相对简单。用户可以通过继承现有的基类,实现自己的环境包装器或算法。
4. 内存映射缓冲区
为了提高大规模数据处理的效率,SheepRL 实现了基于内存映射的数组(MemmapArray)。这使得处理超出内存容量的大型数据集成为可能。
SheepRL 的性能表现
SheepRL 不仅易于使用,其性能也是令人印象深刻的。以下是一些基准测试结果:
| 环境 | 总帧数 | 训练时间 | 测试奖励 | 论文奖励 | GPU |
|---|---|---|---|---|---|
| Crafter | 1M | 1d 3h | 12.1 | 11.7 | 1-V100 |
| Atari-MsPacman | 100K | 14h | 1542 | 1327 | 1-3080 |
| Atari-Boxing | 100K | 14h | 84 | 78 | 1-3080 |
这些结果表明,SheepRL 在各种环境中都能达到或超过基准水平,同时保持较快的训练速度。
未来展望
SheepRL 作为一个活跃开发的项目,其未来发展方向可能包括:
- 支持更多先进的强化学习算法。
- 进一步优化分布式训练性能。
- 增强与其他深度学习框架的集成。
- 提供更丰富的示例和教程,以帮助用户快速上手。
结语
SheepRL 为强化学习研究和应用提供了一个强大而灵活的工具。无论是初学者还是经验丰富的研究者,都能从这个框架中受益。它的易用性、可扩展性和性能优势使其成为强化学习领域的一个重要贡献。
随着人工智能和机器学习技术的不断发展,像 SheepRL 这样的工具将在推动强化学习研究和应用方面发挥越来越重要的作用。我们期待看到更多基于 SheepRL 的创新成果,以及框架本身的进一步发展和完善。
如果你对强化学习感兴趣,不妨尝试使用 SheepRL 来开展你的下一个项目。无论是复现经典算法,还是探索新的研究方向,SheepRL 都将是你的得力助手。