
Solo Performance Prompting: 释放大型语言模型的认知协同效应
在人工智能和自然语言处理领域,大型语言模型(Large Language Models, LLMs)的出现彻底改变了我们与机器交互的方式。这些模型展现出惊人的语言理解和生成能力,但在处理复杂任务时仍然面临挑战。为了进一步提升LLMs的能力,研究人员一直在探索新的方法。最近,一种名为Solo Performance Prompting (SPP)的创新方法引起了广泛关注。
SPP的核心理念
Solo Performance Prompting的核心理念是通过让单个大型语言模型扮演多个不同角色,进行自我协作来解决复杂任务。这种方法借鉴了人类在面对困难问题时常用的思考方式 - 从不同角度和专业领域来分析问题。SPP将这种多角度思考的能力赋予了AI模型,使其能够更全面、更深入地处理复杂任务。
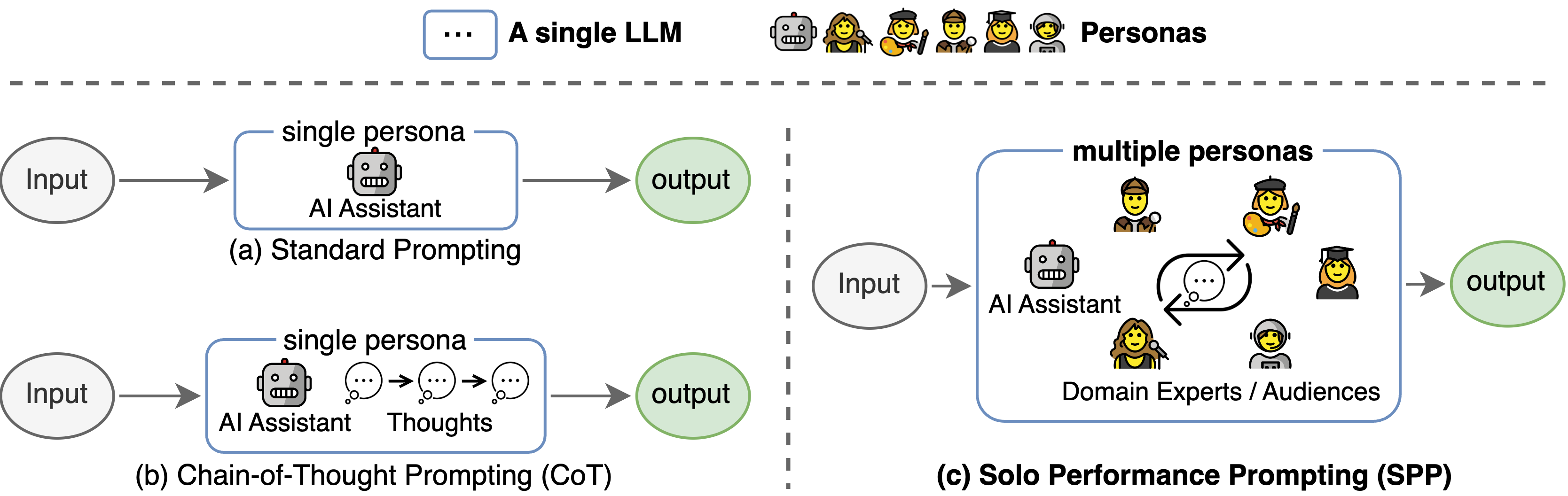
SPP的工作原理
-
角色定义: 根据任务需求,为语言模型定义多个不同的角色或"personas"。每个角色都有特定的专业背景和思考方式。
-
多轮对话: 模型依次扮演这些角色,进行多轮对话。每个角色都会根据自己的"专业"对问题提供独特的见解。
-
信息整合: 通过多轮对话,模型能够从不同角度收集信息和想法,形成更全面的理解。
-
最终决策: 在收集了多个角色的意见后,模型会综合所有信息,给出最终的解决方案或答案。
SPP的优势
-
认知协同效应: 通过多角色协作,SPP能够激发模型的认知协同效应,产生比单一角色更优秀的解决方案。
-
提高复杂任务处理能力: 对于需要多方面知识和视角的复杂任务,SPP表现出色。
-
灵活性: SPP可以根据不同任务定制角色,适用于广泛的应用场景。
-
无需额外训练: SPP是一种提示工程方法,不需要对模型进行额外的微调或训练。
应用场景
SPP在多个领域展现出了强大的潜力:
-
创意写作: 在Trivia Creative Writing任务中,SPP可以扮演作家、编辑、读者等角色,共同创作出高质量的短篇故事。
-
合作游戏: 在Codenames Collaborative任务中,SPP可以同时扮演给出线索的Spymaster和猜词的Guesser,提高游戏表现。
-
逻辑推理: 在Logic Grid Puzzle任务中,SPP可以扮演不同的推理专家,共同解决复杂的逻辑谜题。
实验结果
研究者们对SPP进行了广泛的实验,结果令人振奋:
-
在Trivia Creative Writing任务中,SPP生成的故事在创意性和连贯性上都优于基线方法。
-
在Codenames Collaborative任务中,SPP显著提高了游戏的成功率。
-
在Logic Grid Puzzle任务中,SPP展现出强大的逻辑推理能力,解题正确率大幅提升。
这些实验结果清楚地表明,SPP能够有效提升大型语言模型在复杂任务中的表现。
SPP的实现细节
要实现SPP,研究者们开发了一套完整的框架:
-
模型选择: 实验主要使用了GPT-4模型,但SPP理论上适用于任何足够强大的大型语言模型。
-
提示设计: 为每个角色精心设计提示词,确保角色行为符合预期。
-
对话管理: 实现了一个对话管理系统,控制多轮对话的进行和信息的传递。
-
输出解析: 开发了专门的解析器,从模型输出中提取有用信息。
有兴趣的读者可以在项目的GitHub仓库中找到详细的实现代码和实验设置。
SPP的局限性与未来发展
尽管SPP展现出了巨大的潜力,但它也存在一些局限性:
-
计算成本: 多轮对话可能会增加计算成本和响应时间。
-
角色设计: 不同任务可能需要精心设计不同的角色,这需要一定的专业知识。
-
一致性: 在某些情况下,不同角色的观点可能会产生冲突,需要更好的机制来协调和整合这些观点。
未来的研究方向可能包括:
-
自动角色生成: 开发算法自动为不同任务生成合适的角色。
-
与其他技术的结合: 探索将SPP与其他提示工程技术(如思维链)结合的可能性。
-
跨模态应用: 将SPP扩展到处理图像、音频等多模态任务。
结语
Solo Performance Prompting为大型语言模型的应用开辟了新的可能性。通过激发模型的认知协同效应,SPP使单个模型能够像一个高效的团队一样工作,处理复杂的任务。随着研究的深入,我们期待看到SPP在更多领域发挥作用,推动人工智能技术的进步。
对于开发者和研究者来说,SPP提供了一个强大的工具,可以用来提升现有语言模型的能力。我们鼓励读者尝试将SPP应用到自己的项目中,探索这种方法的潜力。
如果您对SPP感兴趣,不妨访问项目的GitHub仓库,亲自尝试一下这个令人兴奋的新技术。让我们一起探索大型语言模型的无限可能!










