
Sophia优化器:革新大型语言模型预训练的新武器
在深度学习领域,优化器的选择对模型训练效果至关重要。近期,由刘洪等人提出的Sophia优化器在大型语言模型预训练中展现出了卓越的性能,引起了学术界和工业界的广泛关注。本文将深入探讨Sophia优化器的原理、优势及其在实践中的应用。
Sophia优化器简介
Sophia(Scalable Stochastic Second-order Optimizer)是一种针对大型语言模型预训练设计的可扩展随机二阶优化器。它的核心思想是利用随机估计的Hessian对角线信息来自适应调整每个参数的学习率,从而加速模型收敛并提高训练效率。
Sophia优化器的主要优势包括:
- 收敛速度快:相比传统的Adam和Lion优化器,Sophia能够更快地达到相同的模型性能。
- 可扩展性强:适用于各种规模的语言模型,从小型到超大型模型均可使用。
- 内存效率高:与其他二阶优化方法相比,Sophia的内存开销较小。
- 超参数敏感度低:对超参数的选择相对不敏感,易于调优。
Sophia优化器的实现与使用
Sophia优化器的官方实现已在GitHub上开源(https://github.com/Liuhong99/Sophia)。该项目基于PyTorch框架,并提供了详细的使用说明和示例代码。
以下是使用SophiaG(Sophia的一个变体)优化器的基本代码示例:
import torch
from sophia import SophiaG
# 初始化模型和数据加载器
model = Model()
data_loader = ...
# 初始化优化器
optimizer = SophiaG(model.parameters(), lr=2e-4, betas=(0.965, 0.99), rho=0.01, weight_decay=1e-1)
# 训练循环
for epoch in range(epochs):
for X, Y in data_loader:
# 标准训练代码
logits, loss = model(X, Y)
loss.backward()
optimizer.step(bs=batch_size)
optimizer.zero_grad(set_to_none=True)
# 每k次迭代更新一次Hessian EMA
if iter_num % k == k - 1:
# 更新Hessian EMA的代码...
optimizer.update_hessian()
超参数调优技巧
使用Sophia优化器时,合理的超参数设置对于获得最佳性能至关重要。以下是一些关键的调优技巧:
-
学习率(lr)选择:
- 通常选择略小于AdamW的学习率,或者是Lion学习率的3-5倍。
- 对于GPT-2模型,可以使用与AdamW相近或Lion的5-10倍的学习率。
-
ρ参数调整:
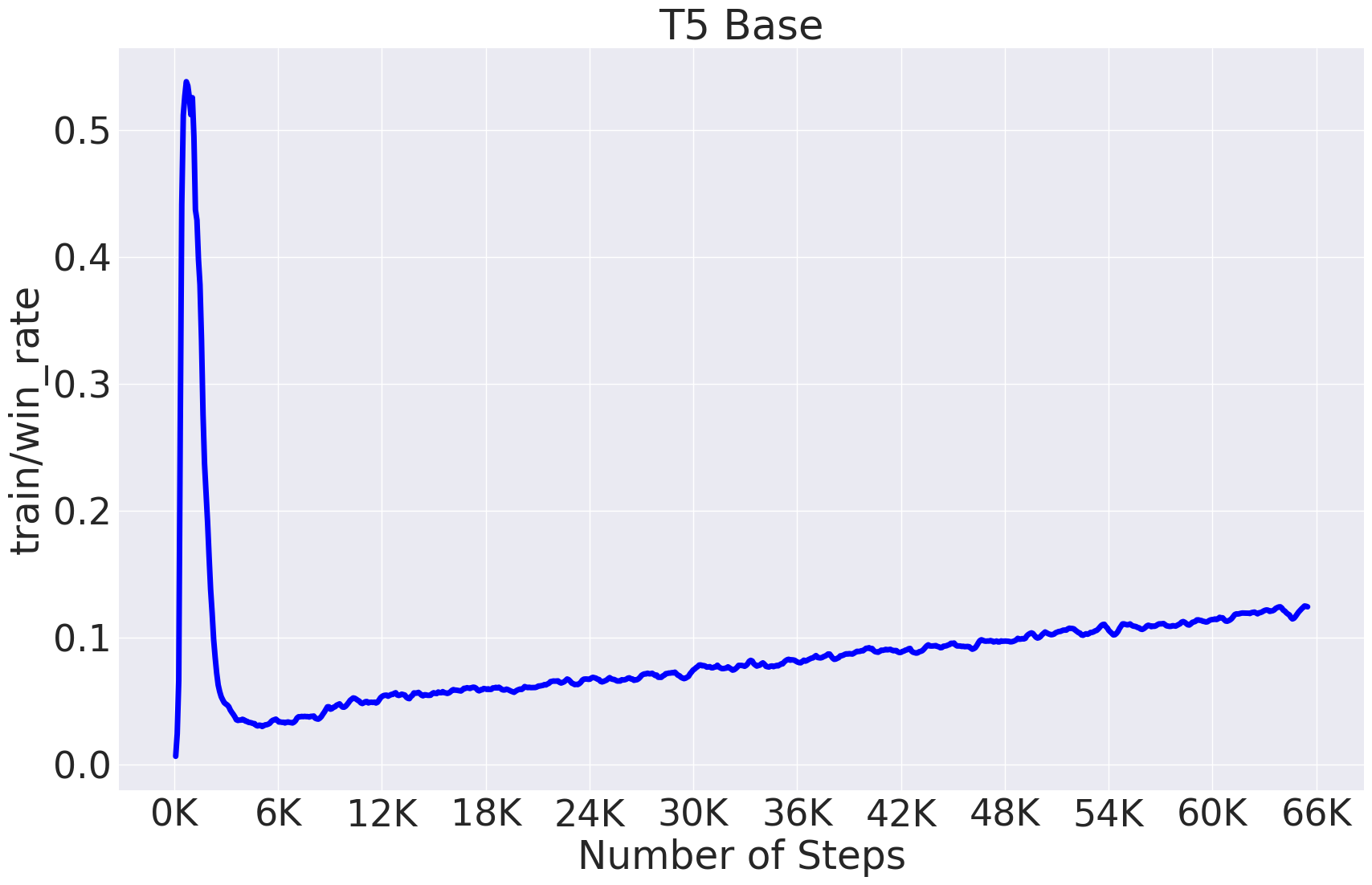
- 调整ρ使得被裁剪的坐标比例(train/win_rate)保持稳定,一般在0.1-0.5之间。
- 较大的ρ通常会导致较高的win_rate。
-
权重衰减(weight_decay):
- 使用比AdamW略大的权重衰减,通常是AdamW的2倍左右。
- 对于GPT-2模型,建议使用0.2的权重衰减。
-
β1和β2参数:
- 一般可以使用(0.965, 0.99)作为默认值。
下面是一张典型的T5模型训练过程中win_rate的变化图,可以作为参考:
GPT-2模型预训练复现
Sophia优化器在GPT-2模型的预训练中展现出了显著的优势。以下是不同规模GPT-2模型的推荐超参数设置:
| 模型大小 | Adam学习率 | Lion学习率 | Sophia学习率 | Sophia的ρ | Sophia的权重衰减 |
|---|---|---|---|---|---|
| 125M | 6e-4 | 1e-4 | 6e-4 | 0.05 | 0.2 |
| 355M | 3e-4 | 1e-4 | 7e-4 | 0.08 | 0.2 |
| 770M | 2e-4 | 8e-5 | 3e-4 | 0.05 | 0.2 |
研究人员使用OpenWebText数据集对GPT-2 Small(125M)和GPT-2 Medium(355M)模型进行了预训练,并与AdamW优化器进行了对比。结果显示,Sophia优化器在训练速度和最终性能上都优于AdamW。
以下是GPT-2 Small模型的训练结果对比图:
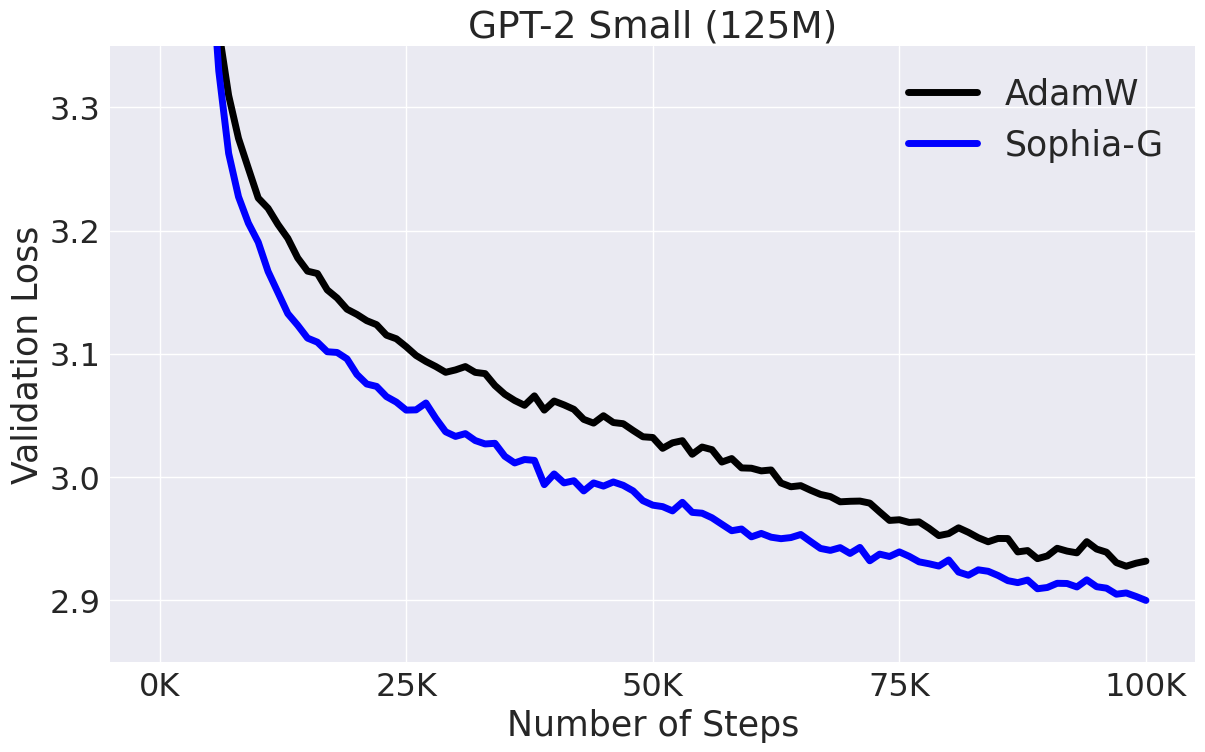
可以看出,Sophia优化器(蓝线)在相同的训练步数下,能够达到更低的损失值,表现出更快的收敛速度和更好的最终性能。
Sophia优化器的未来展望
尽管Sophia优化器在大型语言模型预训练中展现出了巨大潜力,但它仍然有进一步改进和扩展的空间:
-
适用性拓展:目前Sophia主要在语言模型预训练中表现出色,未来可以探索其在其他深度学习任务(如计算机视觉、强化学习等)中的应用。
-
理论分析:深入研究Sophia优化器的收敛性和稳定性,为其性能提供更坚实的理论基础。
-
硬件适配:优化Sophia在不同硬件平台(如TPU、专用AI芯片等)上的实现,以提高其在各种环境下的效率。
-
与其他技术结合:探索Sophia与其他先进技术(如梯度累积、混合精度训练等)的结合,进一步提升大模型训练的效率。
-
自适应超参数调整:研究如何在训练过程中自动调整Sophia的超参数,减少人工调优的工作量。
结语
Sophia优化器为大型语言模型的预训练带来了新的可能性。它不仅能够加速模型收敛,还能提高最终性能,这对于缩短AI模型的研发周期和降低训练成本具有重要意义。随着深度学习领域的不断发展,我们期待看到更多像Sophia这样的创新优化方法,推动人工智能技术向更高层次迈进。
对于有志于探索Sophia优化器的研究者和工程师,建议深入阅读相关论文(https://arxiv.org/abs/2305.14342)并尝试在自己的项目中应用这一优化器。同时,关注Sophia项目的GitHub仓库(https://github.com/Liuhong99/Sophia)以获取最新的代码更新和使用指南。
在人工智能技术日新月异的今天,保持对新技术的开放态度和持续学习的热情至关重要。Sophia优化器的出现,为我们展示了在看似成熟的领域中仍有创新空间的可能性。让我们共同期待Sophia优化器在未来能够为更多的AI应用带来突破性的进展,推动整个行业向前发展。










