
SqueezeLLM:大语言模型的高效量化压缩技术
近年来,大型语言模型(LLM)在各种自然语言处理任务中展现出了惊人的能力。然而,这些模型通常具有数十亿甚至上百亿的参数,对计算和存储资源的需求极其庞大,这给模型的实际部署和应用带来了巨大挑战。为了解决这一问题,研究人员提出了SqueezeLLM,这是一种创新的后训练量化框架,旨在大幅压缩LLM的模型大小,同时保持或甚至提高模型性能。
SqueezeLLM的核心思想
SqueezeLLM的核心在于其独特的"密集-稀疏量化"(Dense-and-Sparse Quantization)方法。这种方法巧妙地将模型权重矩阵分解为两个部分:
- 密集组件:可以进行大幅度量化而不影响模型性能的主要权重。
- 稀疏组件:保留对模型输出敏感的权重和异常值。
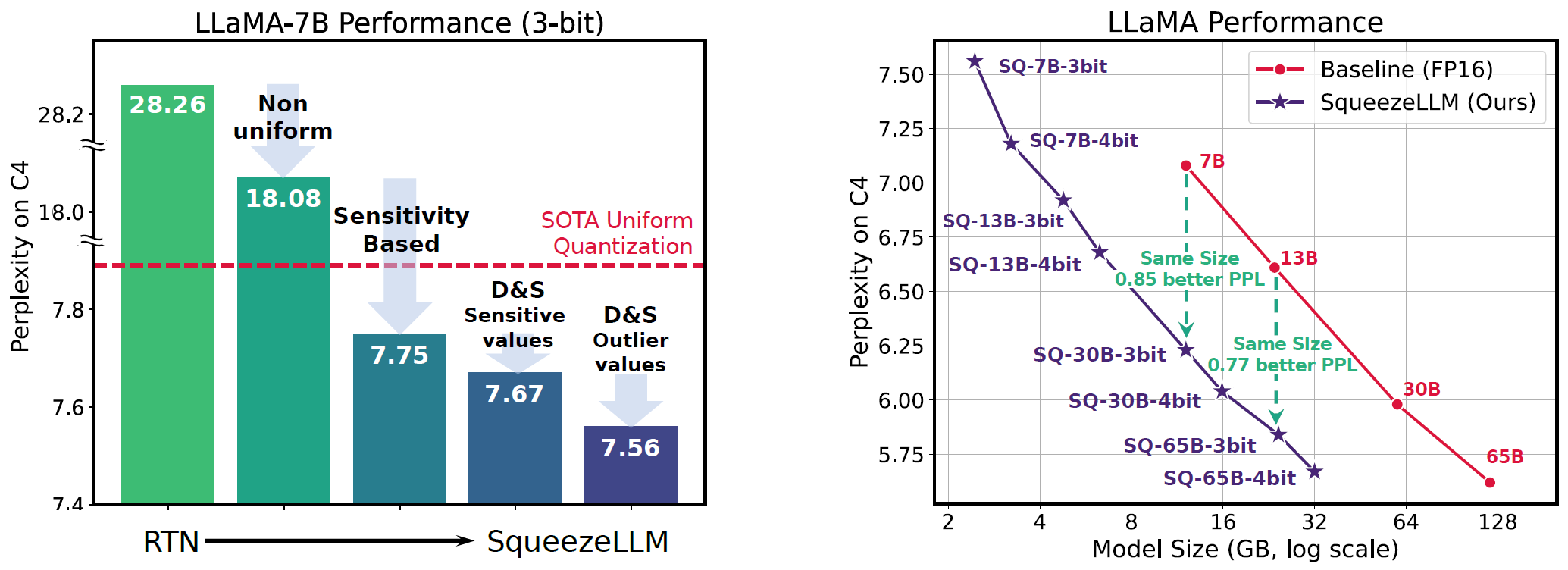
通过这种分解,SqueezeLLM能够在保持模型质量的同时,将权重精度降低到3比特或4比特,实现了极高的压缩率。
技术创新点
SqueezeLLM引入了两个关键的技术创新:
-
基于敏感度的非均匀量化:利用二阶信息(如梯度平方)来搜索最优的比特精度分配,确保重要权重得到更精确的表示。
-
密集-稀疏分解:将少量(通常不超过0.5%)的异常值和敏感权重存储在高效的稀疏格式中,而将大部分权重进行密集量化。这种方法不仅保留了关键信息,还能利用专门的稀疏计算方法提高推理效率。
实验结果
SqueezeLLM在多个大型语言模型上进行了测试,包括LLaMA、Vicuna、XGen等。实验结果表明:
- 在3比特量化下,SqueezeLLM相比基线方法将困惑度(perplexity)差距缩小了多达2.1倍。
- 在A6000 GPU上部署时,量化后的模型相比原始模型实现了高达2.3倍的速度提升。
- Vicuna模型的SqueezeLLM变体可以在仅6GB内存下运行,同时在MMLU基准测试上比16位精度的基线模型高出2%。
支持的模型
SqueezeLLM目前支持多种主流大语言模型,包括:
- LLaMA (7B, 13B, 30B, 65B)
- LLaMA-2 (7B, 13B)
- Vicuna (7B, 13B)
- XGen (7B, 8k序列长度)
- OPT (1.3B至30B)
- Mistral (7B)
对于每个模型,SqueezeLLM提供了3比特和4比特的量化版本,以及不同稀疏度级别(0%, 0.05%, 0.45%)的变体。
使用方法
SqueezeLLM的使用非常简单,主要包括以下步骤:
- 安装SqueezeLLM库
- 下载预训练的量化模型或对自定义模型进行量化
- 使用提供的脚本进行推理或评估
例如,要对LLaMA模型进行基准测试,可以使用以下命令:
CUDA_VISIBLE_DEVICES=0 python llama.py {model_path} c4 --wbits 3 --load sq-llama-7b-w3-s0.pt --benchmark 128 --check --torch_profile
未来展望
SqueezeLLM为大语言模型的高效部署开辟了新的可能性。通过显著减小模型大小和提高推理速度,它使得在资源受限的环境中部署强大的语言模型成为可能。这项技术有望推动LLM在移动设备、边缘计算等场景的应用,为自然语言处理领域带来新的机遇。
随着量化技术的不断发展,我们可以期待看到更多创新方法来进一步提高模型压缩的效率和性能。SqueezeLLM为这一领域的研究指明了方向,相信在不久的将来,我们将看到更多基于这一思想的改进和应用。
结论
SqueezeLLM代表了大语言模型量化压缩领域的重要进展。通过创新的密集-稀疏量化方法,它成功地在模型大小、推理速度和性能之间取得了优秀的平衡。这项技术不仅为研究人员提供了新的思路,也为大语言模型的广泛应用铺平了道路。随着进一步的优化和改进,我们有理由相信,SqueezeLLM及其衍生技术将在未来的AI应用中发挥越来越重要的作用。
对于那些希望在资源受限环境中部署大语言模型的开发者和研究者来说,SqueezeLLM无疑是一个值得关注和尝试的工具。它不仅能够显著减少模型的存储和计算需求,还能保持甚至提升模型的性能,为构建更高效、更实用的AI系统提供了有力支持。










