
Stable-ts: 让音频转录更加精准和稳定
在当今数字时代,音频内容的重要性日益凸显。无论是播客、视频、会议记录还是语音备忘录,将语音转换为文字并添加准确的时间戳都变得至关重要。Stable-ts应运而生,它在OpenAI的Whisper模型基础上进行了创新性的改进,为用户提供了一个强大而灵活的音频转录解决方案。
Stable-ts的核心优势
-
高精度转录: Stable-ts继承了Whisper模型的强大语音识别能力,能够准确转录多种语言的音频内容。
-
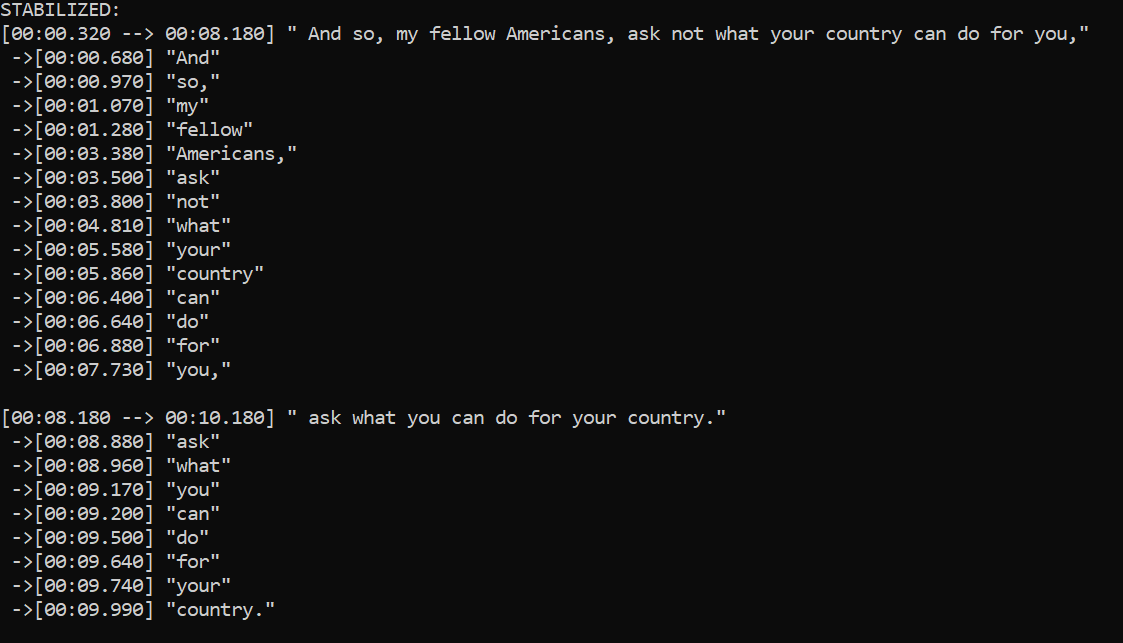
稳定的时间戳: 通过优化的算法,Stable-ts生成的时间戳更加稳定可靠,解决了原始Whisper模型中时间戳不稳定的问题。
-
单词级别时间戳: 不同于仅提供句子级别时间戳的其他工具,Stable-ts能够精确到单词级别,为字幕制作和内容索引提供了更细粒度的支持。
-
灵活的输出格式: 支持多种常用的输出格式,如SRT、ASS等,方便用户在不同场景下使用。
-
开源与可定制: 作为一个开源项目,Stable-ts允许用户根据自身需求进行定制和优化。
安装与使用
Stable-ts的安装非常简单,只需要一行命令:
pip install -U stable-ts
对于想要使用最新开发版本的用户,可以直接从GitHub安装:
pip install -U git+https://github.com/jianfch/stable-ts.git
命令行使用
Stable-ts提供了简洁的命令行界面,使得音频转录变得轻而易举:
- 转录音频并保存为JSON文件:
stable-ts audio.mp3 -o audio.json
2. 将JSON结果处理为ASS格式:
stable-ts audio.json -o audio.ass
3. 批量处理多个音频文件并直接输出为SRT格式:
stable-ts audio1.mp3 audio2.mp3 audio3.mp3 -o audio1.srt audio2.srt audio3.srt
### Python API使用
对于开发者而言,Stable-ts提供了灵活的Python API:
```python
import stable_whisper
model = stable_whisper.load_model('base')
results = model.transcribe('audio.mp3')
# 生成句子级别的SRT文件
stable_whisper.results_to_sentence_srt(results, 'audio.srt')
# 生成包含句子和单词级别时间戳的ASS文件
stable_whisper.results_to_sentence_word_ass(results, 'audio.ass')
```
### 高级功能
Stable-ts不仅仅是一个简单的转录工具,它还提供了许多高级功能:
1. **语音活动检测(VAD)**: 使用Silero VAD生成时间戳抑制掩码,提高转录准确性。
2. **音频预处理**: 可选择使用Demucs对音轨进行预处理,以隔离人声或去除噪音。
3. **beam search**: 支持beam search解码,在温度为零时提供更准确的转录结果。
4. **分段重组**: 能够将单词重新分组为更自然的语句边界。
### 应用场景
Stable-ts的应用场景非常广泛:
1. **字幕制作**: 精确的单词级时间戳使得字幕制作变得更加简单和准确。
2. **内容分析**: 可以轻松地对长音频内容进行索引和搜索。
3. **会议记录**: 自动生成带时间戳的会议记录,提高工作效率。
4. **播客转录**: 为播客创作者提供快速生成文字稿的工具。
5. **学术研究**: 帮助研究人员快速处理大量口述资料。
### 未来展望
尽管Stable-ts已经展现出了强大的功能,但开发团队并未止步于此。未来的发展方向包括:
1. 支持更多语言和方言。
2. 进一步提高转录准确性和时间戳稳定性。
3. 集成更多音频预处理和后处理工具。
4. 优化性能,支持更大规模的音频处理。
### 结语
Stable-ts作为一个开源项目,不仅为用户提供了强大的音频转录工具,也为整个语音识别领域带来了新的可能性。无论您是开发者、内容创作者还是研究人员,Stable-ts都能为您的工作流程带来显著的改进。
我们鼓励更多的开发者和用户参与到Stable-ts的开发和完善中来,共同推动音频转录技术的进步。让我们一起,让音频内容的处理变得更加简单、准确和高效!
[查看Stable-ts GitHub仓库](https://github.com/jianfch/stable-ts)


















