
SUMO-RL简介
SUMO-RL是一个专为交通信号控制设计的强化学习框架。它基于SUMO(Simulation of Urban MObility)交通仿真软件,为研究人员和工程师提供了一个简单而强大的接口,用于创建和实验各种交通信号控制策略。
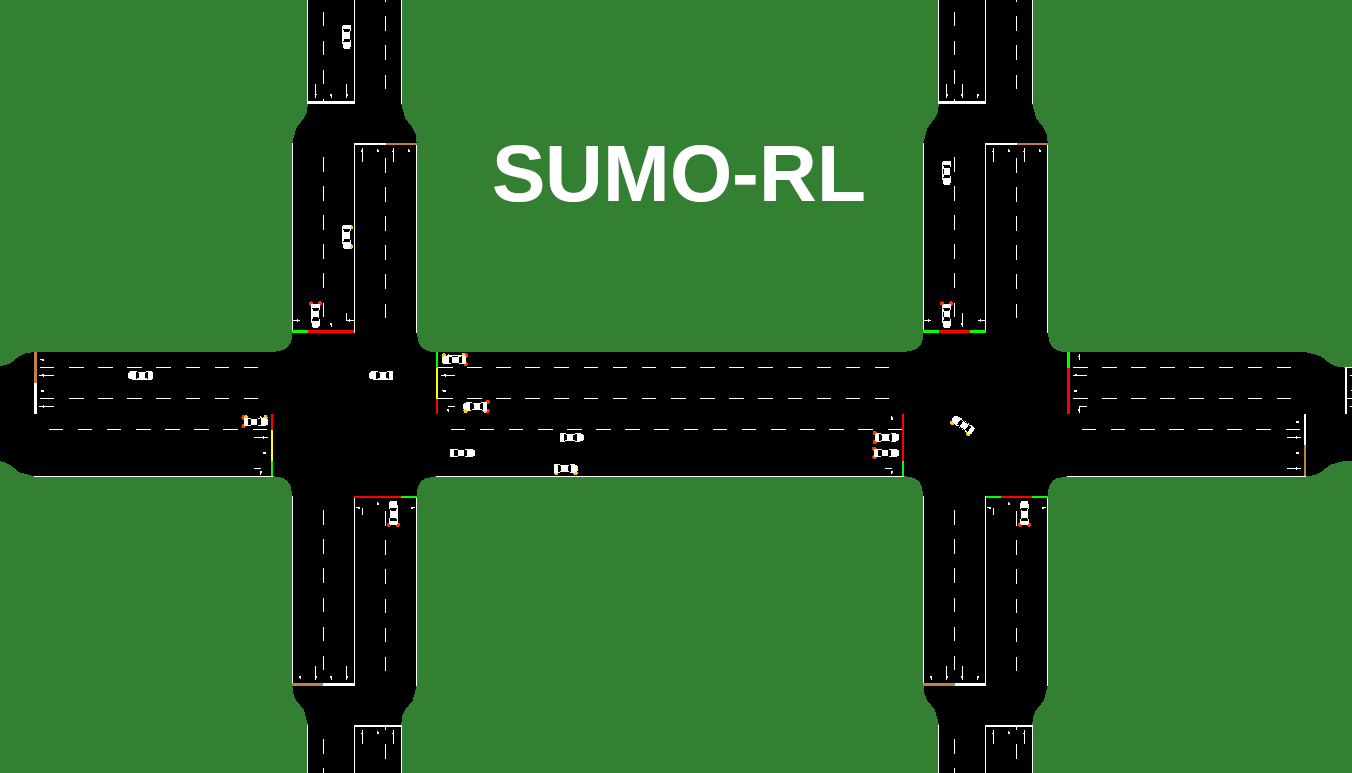
SUMO-RL的主要目标包括:
- 为使用SUMO进行交通信号控制的强化学习研究提供简单易用的接口
- 支持多智能体强化学习
- 与流行的强化学习库(如stable-baselines3和RLlib)兼容
- 易于自定义状态和奖励函数
核心特性
SUMO-RL的核心是SumoEnvironment类。它可以根据需要实例化为单智能体或多智能体环境:
- 单智能体模式:行为类似标准的Gymnasium Env
- 多智能体模式:使用PettingZoo接口,支持AEC或并行API
TrafficSignal类负责使用TraCI API获取交通信息和控制交通灯。
安装指南
要使用SUMO-RL,首先需要安装SUMO和SUMO-RL包。
安装SUMO
-
添加SUMO稳定版仓库:
sudo add-apt-repository ppa:sumo/stable -
更新并安装SUMO:
sudo apt-get update sudo apt-get install sumo sumo-tools sumo-doc -
设置SUMO_HOME环境变量:
echo 'export SUMO_HOME="/usr/share/sumo"' >> ~/.bashrc source ~/.bashrc
安装SUMO-RL
SUMO-RL可以通过pip安装稳定版:
pip install sumo-rl
或者从GitHub安装最新版:
git clone https://github.com/LucasAlegre/sumo-rl
cd sumo-rl
pip install -e .
MDP - 观察、行动和奖励
SUMO-RL中的强化学习环境由观察空间、动作空间和奖励函数组成。
观察空间
默认的观察向量包含以下信息:
obs = [phase_one_hot, min_green, lane_1_density,...,lane_n_density, lane_1_queue,...,lane_n_queue]
phase_one_hot: 当前绿灯相位的one-hot编码min_green: 当前相位是否已经持续最小绿灯时间的二进制变量lane_i_density: 第i条进入车道的车辆密度lane_i_queue: 第i条进入车道的排队车辆数量
用户可以通过继承ObservationFunction类来自定义观察空间。
动作空间
动作空间是离散的。每隔delta_time秒,每个交通信号智能体可以选择下一个绿灯相位配置。
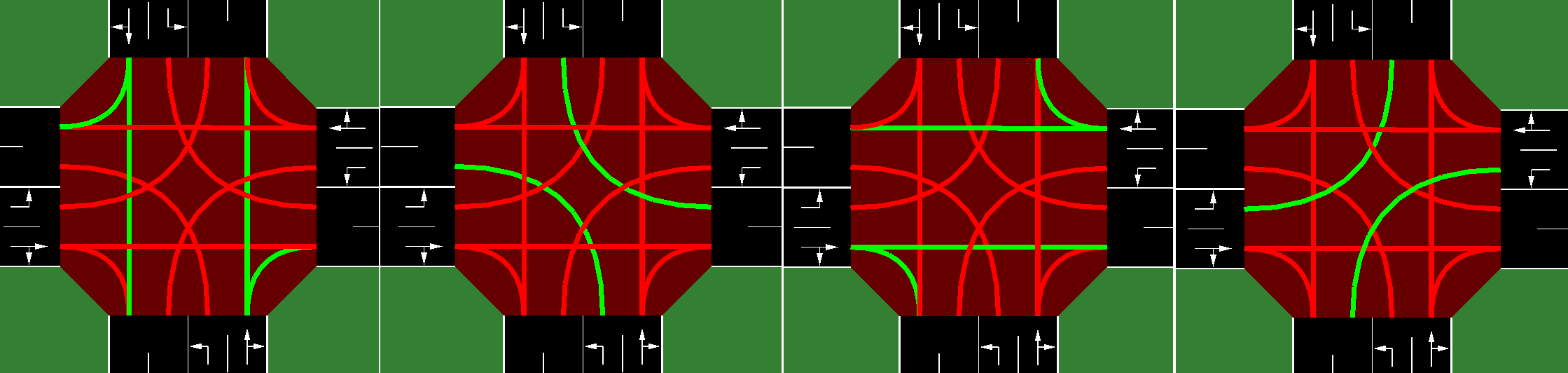
例如,在双向单交叉口场景中,有4种离散动作对应不同的绿灯相位配置。
需要注意的是,每次相位变化时,新相位之前会有一个持续yellow_time秒的黄灯相位。
奖励函数
默认的奖励函数是累积车辆延迟的变化:

即奖励是总延迟(所有接近车辆等待时间之和)相对于上一时间步的变化。
用户可以在SumoEnvironment构造函数中使用reward_fn参数选择不同的奖励函数,也可以自定义奖励函数:
def my_reward_fn(traffic_signal):
return traffic_signal.get_average_speed()
env = SumoEnvironment(..., reward_fn=my_reward_fn)
API使用示例
SUMO-RL支持Gymnasium和PettingZoo两种API,分别用于单智能体和多智能体环境。
Gymnasium单智能体API
对于只有一个交通灯的网络,可以使用标准的Gymnasium环境:
import gymnasium as gym
import sumo_rl
env = gym.make('sumo-rl-v0',
net_file='path_to_your_network.net.xml',
route_file='path_to_your_routefile.rou.xml',
out_csv_name='path_to_output.csv',
use_gui=True,
num_seconds=100000)
obs, info = env.reset()
done = False
while not done:
next_obs, reward, terminated, truncated, info = env.step(env.action_space.sample())
done = terminated or truncated
PettingZoo多智能体API
对于多智能体环境,可以使用PettingZoo API:
import sumo_rl
env = sumo_rl.parallel_env(net_file='nets/RESCO/grid4x4/grid4x4.net.xml',
route_file='nets/RESCO/grid4x4/grid4x4_1.rou.xml',
use_gui=True,
num_seconds=3600)
observations = env.reset()
while env.agents:
actions = {agent: env.action_space(agent).sample() for agent in env.agents} # 这里可以插入您的策略
observations, rewards, terminations, truncations, infos = env.step(actions)
RESCO基准测试
SUMO-RL还包含了RESCO(Reinforcement Learning Benchmarks for Traffic Signal Control)的网络和路由文件,这为研究人员提供了标准化的测试环境。
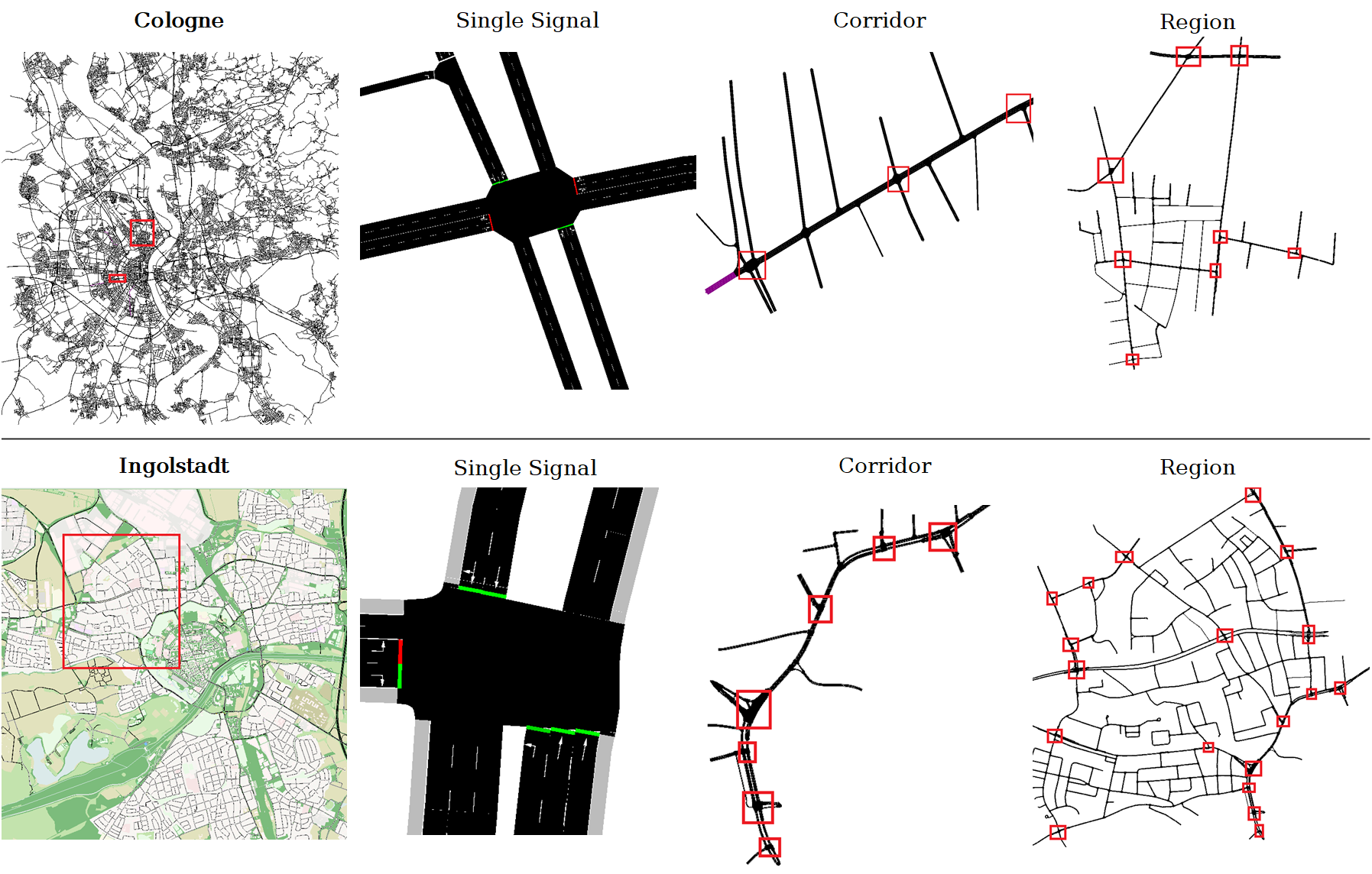
实验示例
SUMO-RL提供了多个实验示例,展示如何实例化环境并训练RL智能体:
-
使用Q-learning在单向单交叉口场景:
python experiments/ql_single-intersection.py -
使用RLlib PPO在4x4网格场景:
python experiments/ppo_4x4grid.py -
使用stable-baselines3 DQN在双向单交叉口场景:
python experiments/dqn_2way-single-intersection.py
这些示例为研究人员提供了良好的起点,可以根据需要进行修改和扩展。
结果可视化
SUMO-RL还提供了结果可视化工具:
python outputs/plot.py -f outputs/4x4grid/ppo_conn0_ep2
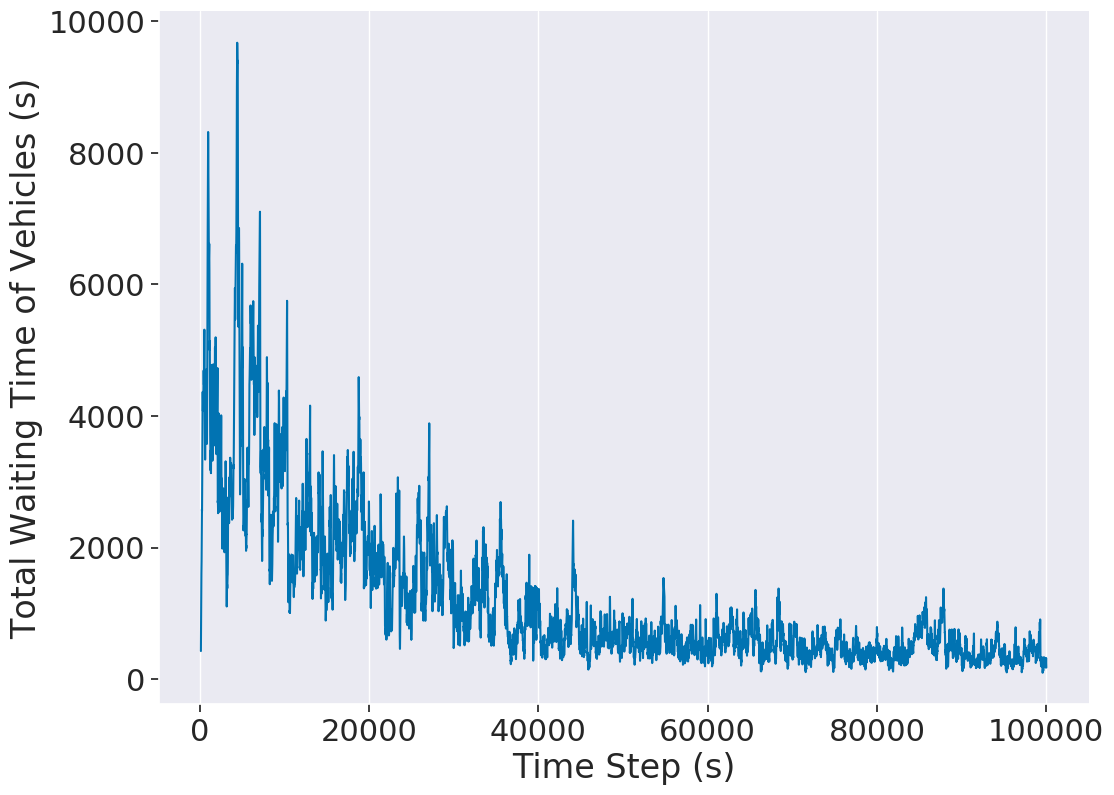
总结
SUMO-RL为交通信号控制领域的强化学习研究提供了一个强大而灵活的工具。它简化了环境设置和实验过程,支持单智能体和多智能体学习,并与主流RL库兼容。通过提供标准化的基准测试和丰富的示例,SUMO-RL正在推动交通信号控制的智能化发展。
无论您是研究人员、工程师还是对智能交通感兴趣的学生,SUMO-RL都为您提供了探索和创新的平台。随着城市化进程的加速和交通问题的日益突出,基于强化学习的智能交通信号控制系统必将在未来的智慧城市中发挥重要作用。
如果您在研究中使用了SUMO-RL,请引用以下信息:
@misc{sumorl,
author = {Lucas N. Alegre},
title = {{SUMO-RL}},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/LucasAlegre/sumo-rl}},
}
SUMO-RL正在被越来越多的研究所采用,相关论文列表不断增长。这不仅证明了该工具的价值,也展示了交通信号控制领域正在蓬勃发展。我们期待看到更多基于SUMO-RL的创新研究成果,共同推动智能交通的进步。









