
SuperSonic: 融合Chat BI和Headless BI的智能分析新范式
在当今数据驱动的商业环境中,企业对快速、精准的数据分析需求日益增长。传统的商业智能(BI)工具虽然功能强大,但往往需要专业技能才能充分发挥其潜力。而新兴的自然语言查询技术又常常面临数据一致性和可靠性的挑战。在这样的背景下,腾讯音乐推出了SuperSonic平台,巧妙地将Chat BI和Headless BI两种范式融为一体,为用户提供了一种全新的智能分析体验。
SuperSonic的核心理念
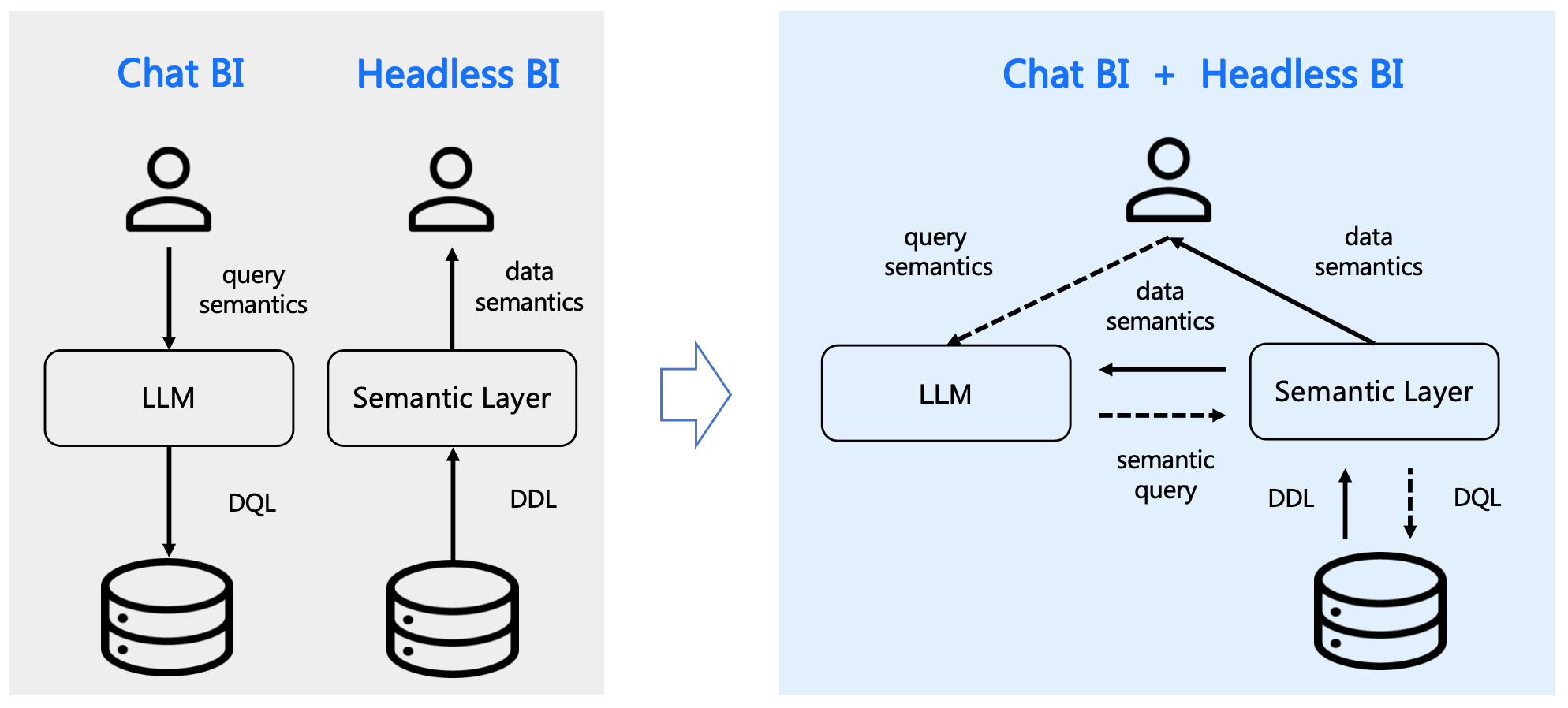
SuperSonic的核心理念在于将大语言模型(LLM)驱动的Chat BI与语义层驱动的Headless BI有机结合。这种结合不仅确保了Chat BI能够访问与传统BI相同的经过策划和治理的语义数据模型,还通过两种范式的互补优势提升了整体性能:
- Chat BI的文本到SQL(Text2SQL)转换能力通过从语义模型中检索上下文得到了增强。
- Headless BI的查询接口扩展了自然语言API,使其更易于使用。
用户友好的界面设计
SuperSonic为用户提供了一个直观的Chat BI界面,使他们能够使用自然语言进行数据查询,并通过合适的图表可视化结果。这种体验的实现仅需通过Headless BI接口构建逻辑语义模型,定义指标、维度、标签及其含义和关系。
SuperSonic的技术创新
SuperSonic的创新之处在于其对Text2SQL生成过程的改进:
- 将数据语义(如业务术语、列值等)纳入提示中,使LLM能更好地理解语义并减少幻觉。
- 将高级SQL语法(如连接、公式等)的生成从LLM转移到语义层,以降低复杂性。
这种方法不仅提高了查询的准确性,还增强了系统的可靠性和可扩展性。
架构与核心组件
SuperSonic采用模块化设计,主要包含以下核心组件:
- 知识库:定期从语义模型中提取模式信息,构建词典和索引以促进模式映射。
- 模式映射器:识别用户查询中对模式元素的引用,并与知识库进行匹配。
- 语义解析器:理解用户查询并生成语义查询语句,包括基于规则和基于模型的解析器。
- 语义校正器:检查语义查询语句的有效性,并在需要时进行纠正和优化。
- 语义转换器:将语义查询语句转换为可针对物理数据模型执行的SQL语句。
- 聊天插件:通过第三方工具扩展功能,利用LLM选择最合适的插件。
- 聊天记忆:封装历史查询轨迹,便于进行少样本提示。

丰富的开箱即用功能
SuperSonic提供了一系列开箱即用的功能:
- 为业务用户提供内置的Chat BI界面,支持自然语言查询
- 为分析工程师提供内置的Headless BI界面,用于构建语义数据模型
- 内置基于规则的语义解析器,提高特定场景下的效率
- 支持输入自动完成、多轮对话以及查询后推荐
- 支持三级数据访问控制:数据集级、列级和行级
灵活的可扩展性
SuperSonic设计为可扩展和可组合的框架,允许通过Java SPI添加和配置自定义实现。这种灵活性使得SuperSonic能够适应不同组织的特定需求,并随着技术的发展不断进化。
快速上手与部署
SuperSonic提供了多种部署选项,方便用户快速上手:
-
在线体验:访问http://117.72.46.148:9080注册并体验。
-
Docker部署:
- 安装Docker和docker-compose
- 下载docker-compose.yml文件
- 执行"docker-compose up -d"
- 访问http://localhost:9080开始探索
-
本地构建:
- 从release页面下载最新预构建二进制文件
- 运行脚本"assembly/bin/supersonic-daemon.sh start"启动独立Java服务
- 访问http://localhost:9080开始探索
结语
SuperSonic作为一个融合Chat BI和Headless BI的创新平台,为企业提供了一种全新的数据分析方式。它不仅简化了复杂查询的过程,还确保了数据的一致性和可靠性。随着更多组织采用这种智能分析范式,我们可以期待看到数据驱动决策的效率和准确性得到显著提升。
SuperSonic的开源nature也为整个BI社区带来了新的机遇。开发者和企业可以基于这个平台进行定制和扩展,推动BI技术的进一步创新。随着AI技术的不断进步,我们有理由相信SuperSonic这样的平台将在未来的数据分析领域发挥越来越重要的作用。









