Sweep:一款强大的时间序列预测工具
 Ray
RaySweep:让时间序列预测变得简单而强大
在数据科学和商业分析领域,时间序列预测一直是一个重要而富有挑战性的任务。为了简化这一过程并提高预测效率,业界专家开发了一款名为Sweep的R语言包。这个强大的工具不仅扩展了广受欢迎的broom包的功能,还专门针对时间序列预测和分析进行了优化。让我们深入了解Sweep的特性、优势以及它如何revolutionize时间序列预测领域。
Sweep的核心优势
Sweep的设计初衷是为了使时间序列预测更加简单、高效和"整洁"。它的主要优势包括:
-
与tidyverse生态系统完美集成:Sweep专为使用R for Data Science中的tidyverse工具进行建模和扩展预测而设计。这意味着用户可以无缝地将Sweep融入到他们现有的数据分析工作流程中。
-
扩展broom功能:Sweep为各种时间序列模型(如ARIMA、ETS、BATS等)提供了模型分析工具。这使得用户可以更容易地理解和解释他们的模型结果。
-
简化forecast对象处理:Sweep可以将forecast对象转换为易于操作的tibble格式。这大大简化了数据操作和可视化过程。
-
支持不规则时间序列:通过与timetk包的集成,Sweep能够在整理后的预测输出中处理日期和日期时间,这对于处理不规则时间序列数据尤为重要。

Sweep的核心工具
Sweep包含以下关键元素:
-
模型整理函数:
sw_tidy、sw_glance、sw_augment和sw_tidy_decomp函数扩展了broom包的tidy、glance和augment功能,专门用于预测模型(如ets()、Arima()、bats()等)。 -
预测整理函数:
sw_sweep函数可以将forecast对象转换为易于在tidyverse中操作的tibble格式。
在tidyverse中进行预测
Sweep的一大优势是它能够将forecast对象转换为tibble格式。这意味着用户可以原生使用dplyr、tidyr和ggplot等工具来操作、分析和可视化预测结果。
例如,以下是使用Sweep处理和可视化美国酒精销售数据的预测结果:

大规模处理多个时间序列组
在实际业务场景中,我们经常需要对多个子类别或产品线进行预测分析。Sweep结合dplyr和purrr,使得从单一时间序列扩展到多个时间序列变得异常简单。
下面的图表展示了如何使用Sweep对多个产品类别进行销售预测:
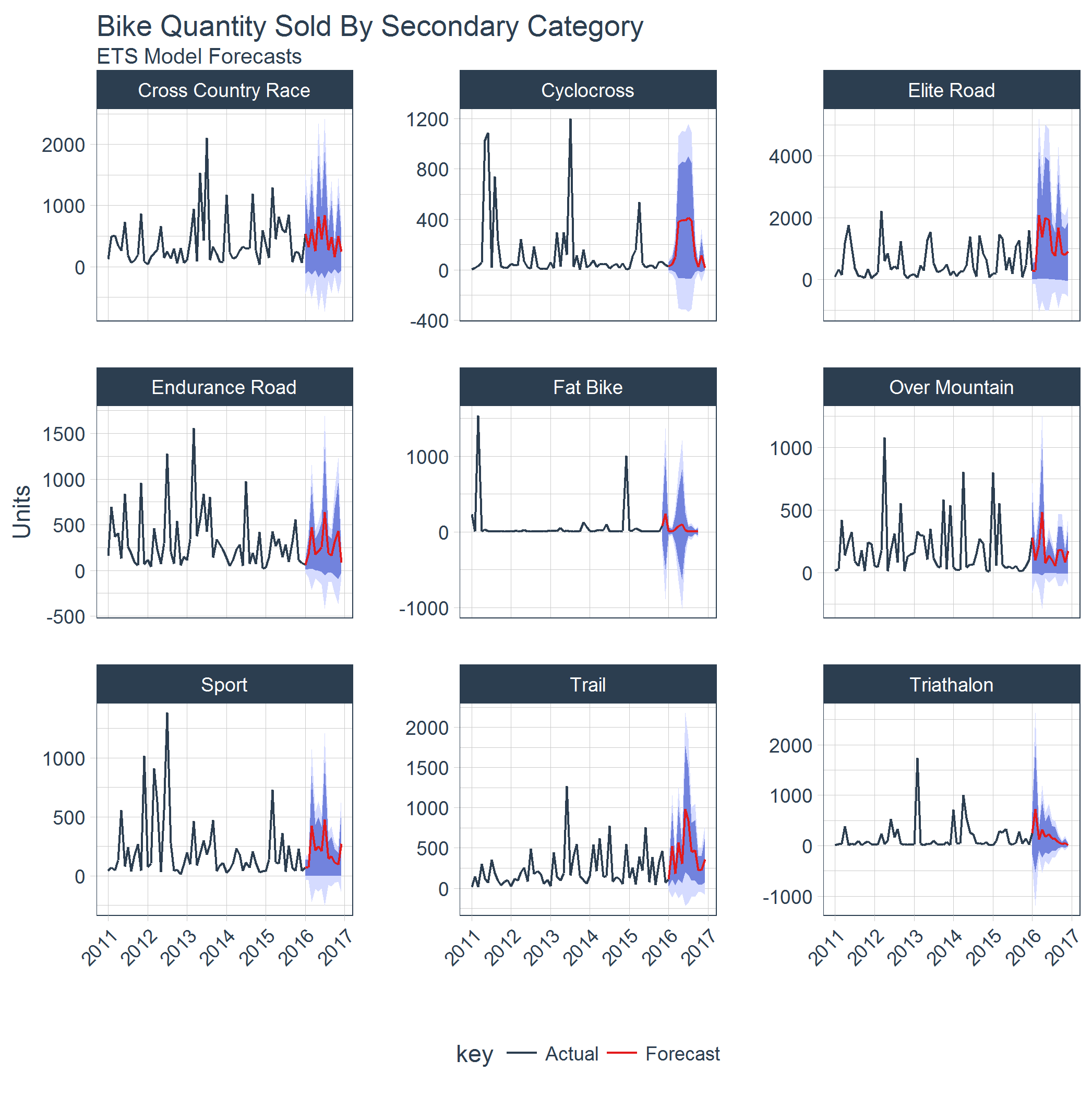
多模型预测比较
在预测领域,比较不同预测模型的性能是一个常见需求。Sweep在这方面也提供了强大的支持。
以下是使用Sweep比较多个模型对黄金和白银价格预测的结果:
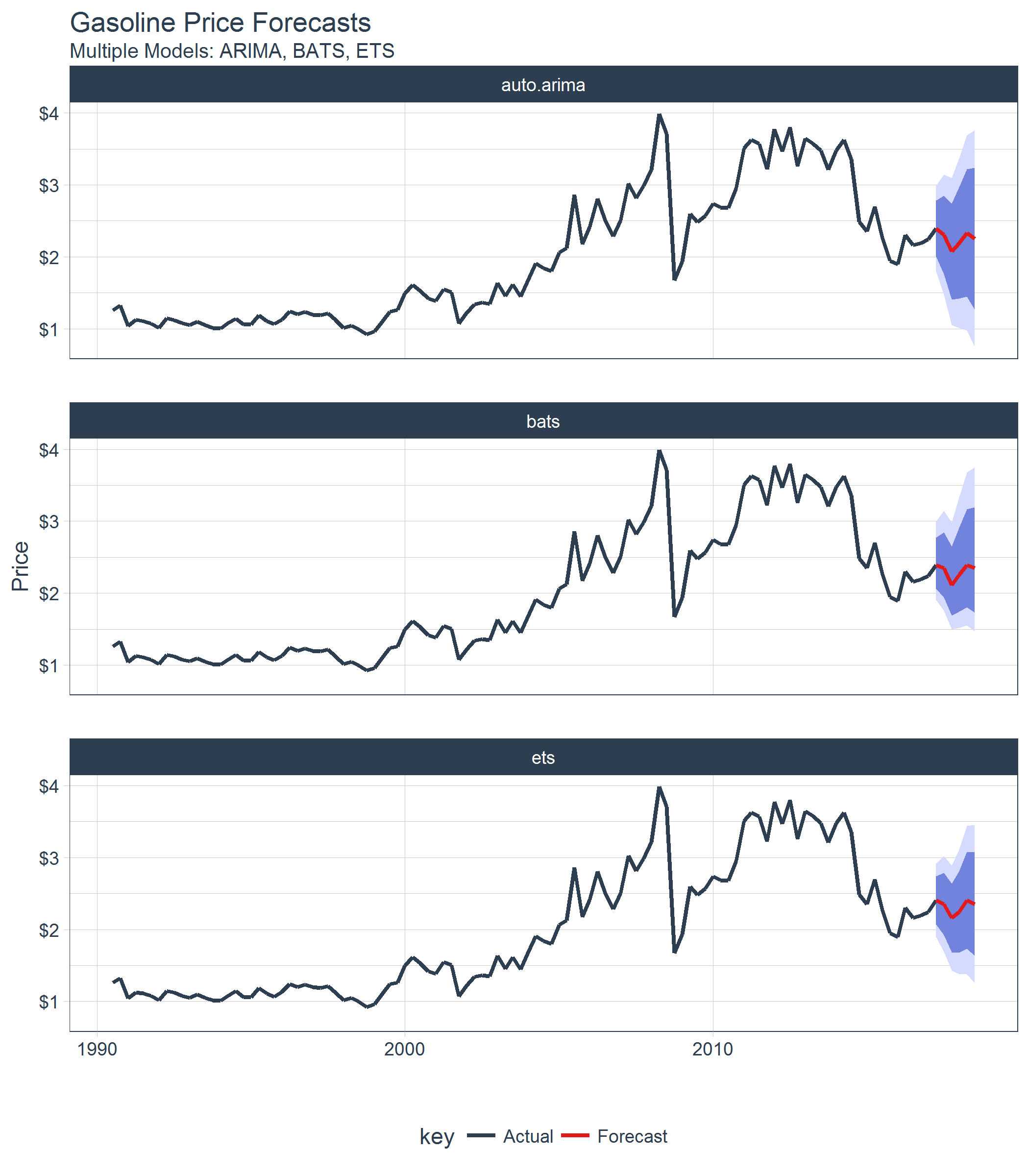
Sweep与broom的兼容性
Sweep扩展了broom包的功能,为forecast包的工作流程提供了以下函数:
sw_tidy:返回模型系数(单列)sw_glance:返回准确度统计(单行)sw_augment:返回残差sw_tidy_decomp:返回季节性分解sw_sweep:返回整洁的预测输出
这些函数与各种时间序列模型和测试兼容,包括ARIMA、ETS、BATS、TBATS、神经网络自回归等。
安装和使用
要开始使用Sweep,你可以通过以下命令安装最新的开发版本:
# install.packages("remotes") remotes::install_github("business-science/sweep")
深入学习
Sweep包含多个vignettes(教程),帮助用户快速上手:
- SW00 - Sweep简介
- SW01 - 在tidyverse中预测时间序列组
- SW02 - 使用多个模型进行预测
这些教程提供了详细的示例和最佳实践,帮助用��户充分利用Sweep的功能。
结语
Sweep为R语言中的时间序列预测带来了革命性的变化。通过简化预测工作流程、提供强大的分析工具,以及与tidyverse生态系统的无缝集成,Sweep使得时间序列预测变得更加高效和易于理解。无论你是数据科学家、商业分析师,还是对时间序列预测感兴趣的研究人员,Sweep都是一个值得探索和使用的强大工具。
随着数据驱动决策在各行各业变得越来越重要,像Sweep这样的工具将在帮助组织更好地理解和预测未来趋势方面发挥关键作用。我们期待看到Sweep在未来的发展,以及它如何继续推动时间序列预测领域的创新。
编辑推荐精选


讯飞智文
一键生成PPT和Word,让学习生活更轻松
讯飞智文是一个利用 AI 技术的项目,能够帮助用户生成 PPT 以及各类文档。无论是商业领域的市场分析报告、年度目标制定,还是学生群体的职业生涯规划、实习避坑指南,亦或是活动策划、旅游攻略等内容,它都能提供支持,帮助用户精准表达,轻松呈现各种信息。


讯飞星火
深度推理能力全新升级,全面对标OpenAI o1
科大讯飞的星火大模型,支持语言理解、知识问答和文本创作等多功能,适用于多种文件和业务场景,提升办公和日常生活的效率。讯飞星火是一个提供丰富智能服务的平台,涵盖科技资讯、图像创作、写作辅助、编程解答、科研文献解读等功能,能为不同需求的用户提供便捷高效的帮助,助力用户轻松获取信息、解决问题,满足多样化使用场景。


Spark-TTS
一种基于大语言模型的高效单流解耦语音令牌文本到语音合成模型
Spark-TTS 是一个基于 PyTorch 的开源文本到语音合成项目,由多个知名机构联合参与。该项目提供了高效的 LLM(大语言模型)驱动的语音合成方案,支持语音克隆和语音创建功能,可通过命令行界面(CLI)和 Web UI 两种方式使用。用户可以根据需求调整语音的性别、音高、速度等参数,生成高质量的语音。该项目适用于多种场景,如有声读物制作、智能语音助手开发等。


Trae
字节跳动发布的AI编程神器IDE
Trae是一种自适应的集成开发环境(IDE),通过自动化和多元协作改变开发流程。利用Trae,团队能够更快速、精确地编写和部署代码,从而提高编程效率和项目交付速度。Trae具备上下文感知和代码自动完成功能,是提升开发效率的理想工具。


咔片PPT
AI助力,做PPT更简单!
咔片是一款轻量化在线演示设计工具,借助 AI 技术,实现从内容生成到智能设计的一站式 PPT 制作服务。支持多种文档格式导入生成 PPT,提供海量模板、智能美化、素材替换等功能,适用于销售、教师、学生等各类人群,能高效制作出高品质 PPT,满足不同场景演示需求。


讯飞绘文
选题、配图、成文,一站式创作,让内容运营更高效
讯飞绘文,一个AI集成平台,支持写作、选题、配图、排版和发布。高效生成适用于各类媒体的定制内容,加速品牌传播,提升内容营销效果。


材料星
专业的AI公文写作平台,公文写作神器
AI 材料星,专业的 AI 公文写作辅助平台,为体制内工作人员提供高效的公文写作解决方案。拥有海量公文文库、9 大核心 AI 功能,支持 30 + 文稿类型生成,助力快速完成领导讲话、工作总结、述职报告等材料,提升办公效率,是体制打工人的得力写作神器。


openai-agents-python
OpenAI Agents SDK,助力开发者便捷使用 OpenAI 相关功能。
openai-agents-python 是 OpenAI 推出的一款强大 Python SDK,它为开发者提供了与 OpenAI 模型交互的高效工具,支持工具调用、结果处理、追踪等功能,涵盖多种应用场景,如研究助手、财务研究等,能显著提升开发效率,让开发者更轻松地利用 OpenAI 的技术优势。


Hunyuan3D-2
高分辨率纹理 3D 资产生成
Hunyuan3D-2 是腾讯开发的用于 3D 资产生成的强大工具,支持从文本描述、单张图片或多视角图片生成 3D 模型,具备快速形状生成能力,可生成带纹理的高质量 3D 模型,适用于多个领域,为 3D 创作�提供了高效解决方案。


3FS
一个具备存储、管理和客户端操作等多种功能的分布式文件系统相关项目。
3FS 是一个功能强大的分布式文件系统项目,涵盖了存储引擎、元数据管理、客户端工具等多个模块。它支持多种文件操作,如创建文件和目录、设置布局等,同时具备高效的事件循环、节点选择和协程池管理等特性。适用于需要大规模数据存储和管理的场景,能够提高系统的性能和可靠性,是分布式存储领域的优质解决方案。
推荐工具精选




AI云服务特惠
懂AI专属折扣关注微信公众号
最新AI工具、AI资讯
独家AI资源、AI项目落地

微信扫一扫关注公众号